






前言
最近在做一个串口相关的项目,里面频繁使用了对字节数组的处理,所以需要使用 ByteBuffer 来处理,于是就对这方面知识做一个简单的梳理和记录。
NIO
Java NIO 是 java 1.4 之后出的一套 IO 接口 NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。
NIO 的特性 / NIO 与 IO 区别:IO 是面向流的,NIO 是面向缓冲区的
IO 流是阻塞的,NIO 流是不阻塞的
NIO 有选择器,而 IO 没有
Java IO 是面向流的意味着我们从一个流中一次读取一个或多个字节。而要对读到的字节作何处理由我们自己决定;这其中没有任何缓存。此外,我们不能在数据流中来回移动;如果想要在从流读取的数据中来回移动,我们需要首先将数据缓存到缓冲区。Java NIO 的缓冲型方法稍有不同。数据读取到缓冲区后被加工,我们可以根据需求在数据中来回移动。这为处理提供了灵活性;然而为了充分处理所有数据我们还需要检查缓冲区是否包含所有需要的数据,并且我们需要确保读取更多数据到缓冲区时未被处理的数据不能被覆盖。
Java IO 的各种流是阻塞型的。这意味着,当一个线程调用 read() 方法或 write() 方法时这个线程将一直被阻塞,直到有数据被读到或者数据被完全写入;在被阻塞的同时,该线程不能做任何其他事情。Java NIO 的非阻塞模式允许一个线程从一个channel中请求读取数据,这只会取到当前有效的数据或当前没有数据有效时获取不到任何数据;而不是一直阻塞直到所读取数据准备好为止;在这同时该线程可以做其他事情。
NIO 读数据和写数据方式:从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。
从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据
NIO 核心组件有:Channels:NIO 中的所有 IO 都是通过 Channel(通道) 传输的。
Buffers:本质上就是一块内存区, 一个Buffer有三个属性分别是:capacity 容量、 position 位置、 limit 限制。
Selectors:称为选择器,用于检查一个或多个 NIO Channel(通道)的状态是否处于可读、可写。
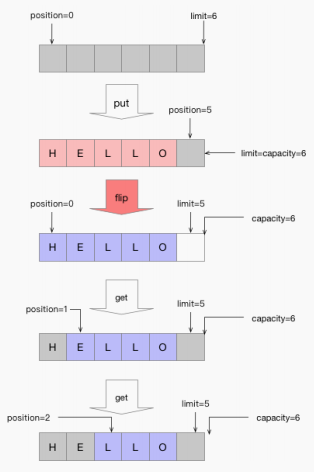
ByteBuffer的读写过程
capacity: 分配好的一个内存块大小,分配好后大小不可变。
limit:在读的模式下,表示缓存内数据的多少,并且 limit<=capacity。在写的模式下,表示最多能存入多少数据,此时 limit=capacity。
position:表示读写的位置,下标从 0 开始。0 <= mark <= position <= limit <= capacity
使用 Selector 的好处在于: 使用更少的线程来就可以来处理通道了, 相比使用多个线程,避免了线程上下文切换带来的开销。
ByteBuffer
ByteBuffer 最核心的方法是 put(byte) 和 get()。分别是往 ByteBuffer 里写一个字节,和读一个字节。
值得注意的是,ByteBuffer 的读写模式是分开的,正常的应用场景是:往 ByteBuffer 里写一些数据,然后 flip(),然后再读出来。
一个 ByteBuffer 的使用过程是这样的:
12345678910111213141516171819202122mByteBuffer = ByteBuffer.allocate(2048)
//读取数据,写入bytes数组mByteBuffer.put(bytes, offset, length);
//变读为写mByteBuffer.flip();
//读取byteBuffer,写入数据writableByteChannel.write(byteBuffer);
//remaining方法返回剩余可用长度(实际读取的数据长度)while ((readable = mByteBuffer.remaining()) >= Protocol.MIN_PACK_LEN) {
mByteBuffer.mark(); // 标记一下开始的位置 mByteBuffer.get(); //读取一字节数据(读取后会自动自增position) mByteBuffer.position(mByteBuffer.position() + 2);
mByteBuffer.get();
mByteBuffer.reset(); // 回到头 final byte[] allPack = new byte[total];
mByteBuffer.get(allPack); // 拿到整个包
//只清空已读取的数据,未被读取的数据会被移动到buffer的开始位置 mByteBuffer.compact();
}
allocate方法
分配一个新的指定字节大小的缓冲区。新缓冲区的 position 将为零,其 limit 将为其容量,其 mark(标记位)是不确定的。它的底层是用一个数组实现的。
put方法
写模式下,往 buffer 里写一个字节,并把 postion 移动一位。写模式下,一般 limit 与 capacity 相等。
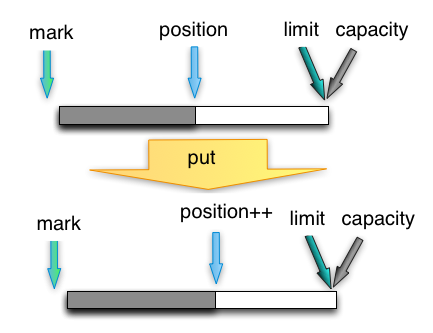
bytebuffer写模式示意图
flip方法
flip() 方法可以把 Buffer 从写模式切换到读模式。调用flip方法会把 position 归零,并设置 limit 为之前的 position 的值。 也就是说,现在 position 代表的是读取位置,limit 标示的是已写入的数据末尾位置。
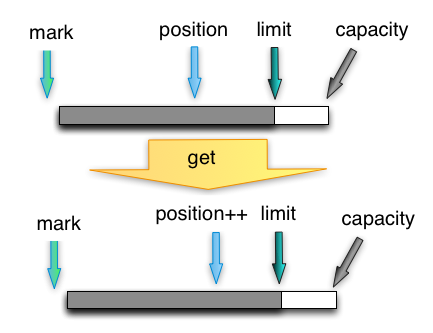
flip方法调用位置示意图
get方法
从 buffer 里读一个字节,并把 postion 移动一位。上限是 limit,即写入数据的最后位置。

get方法调用过程示意图
mark和reset方法
通过 mark 方法可以标记当前的 position,通过 reset 来恢复 mark 的位置,这个非常像 canva 的 save 和 restore:
12345buffer.mark();
//call buffer.get() a couple of times, e.g. during parsing.
buffer.reset(); //set position back to mark.
clear和compact方法
当读取完数据后,需要清空 buffer,以满足后续写入操作。清空 buffer 有两种方式:调用 clear() 或 compact() 方法。clear 会清空整个 buffer,compact 则只清空已读取的数据,未被读取的数据会被移动到 buffer 的开始位置,写入位置则紧跟着未读数据之后。
remaining和hasRemaining方法
remaining 方法返回当前的 position 和 limit 之间的元素个数,而 hasRemaining 方法可以判断当前的 position 和 limit 之间是否有元素。
案例分析
接下来通过一个实际案例看一下 position, limit, capacity, remaining, mark 的关系。
封装一个打印 log 的方法:
1234567private void printByteBuffer(String tag){
LogPlus.i(tag, "mark = " + mByteBuffer.mark());
LogPlus.i(tag, "position = " + mByteBuffer.position());
LogPlus.i(tag, "limit = " + mByteBuffer.limit());
LogPlus.i(tag, "capacity = " + mByteBuffer.capacity());
LogPlus.i(tag, "remaing = " + mByteBuffer.remaining());
}
接下来我们在 put() 数据的前后打印相关日志:
1234567@Override
public boolean onReceive(final byte[] bytes, int offset, int length) {
LogUtil.sendEventBusLog("接收数据:" + new String(bytes, offset, length));
printByteBuffer("DataReceiver1");
mByteBuffer.put(bytes, offset, length);
printByteBuffer("DataReceiver2");
}
打印的获得数据结果:
1接收数据=112233445566778899, offset = 0, length = 18
打印的 put 数据前的指针位置:
123456DataReceiver1:
mark = java.nio.ByteArrayBuffer[position=0,limit=100,capacity=100]
position = 0
limit = 100
capacity = 100
remaing = 100
需要注意的是 mark 是我们在设置的时候才改变,而且 remaing 的值始终是 reming = limit - position;
可以看到当前position 指向的是 0, limit = capacity.
打印的 put 数据后的指针位置:
123456DataReceiver2:
mark = java.nio.ByteArrayBuffer[position=18,limit=100,capacity=100]
position = 18
limit = 100
capacity = 100
remaing = 82
可以看到此时我们的 position 处于 18, 当然此时 remaing = 100 - 18 = 82。
然后我们来 flip() 一下,看看位置变化:
12mByteBuffer.flip();
printByteBuffer("DataReceiver3");
打印 flip 后的指针位置:
123456DataReceiver3:
mark = java.nio.ByteArrayBuffer[position=0,limit=18,capacity=100]
position = 0
limit = 18
capacity = 100
remaing = 18
可以看到此时唯一变化的就是 limit, limit 变成 flip 之前的 position 的值,而 position 归零准备读数据。
接下来做一个判断,当我们的有效收据 remaing 大于某个长度的时候取出固定长度到 byte 数组, 取的方式是从后取。
例如:我们此时 ByteBuffer 的数据是: 11223344556677889900, 我们的 CODE_PACK_LEN = 18, 则取的数据是 223344556677889900 而不是 112233445566778899。
123456789101112if(mByteBuffer.remaining() >= Protocol.CODE_PACK_LEN){
final byte[] allPack = new byte[Protocol.CODE_PACK_LEN];
mByteBuffer.position(mByteBuffer.limit() - Protocol.CODE_PACK_LEN);
mByteBuffer.get(allPack);
mSerialWorker.onReceiveValidData(allPack); //byte集合数据回调到上层 printByteBuffer("DataReceiver4");
mByteBuffer.clear();
printByteBuffer("DataReceiver5");
}else {
mByteBuffer.compact();
printByteBuffer("DataReceiver6");
}
上面例子找那个我们设置的 Protocol.CODE_PACK_LEN 是一个常量为 18, 而我们的数据也刚好是 18,所以上面的判断结果为 true. 我们通过 position() 方法移动指针到从后往前数第 18 个位置:
1mByteBuffer.position(mByteBuffer.limit() - Protocol.CODE_PACK_LEN);
然后取出这 18 位数据,取完后打印指针位置如下:
123456DataReceiver4:
mark = java.nio.ByteArrayBuffer[position=18,limit=18,capacity=100]
position = 18
limit = 18
capacity = 100
remaing = 0
你好发现我们读完后刚好指针 position 等于了 limit, 此时 remaing = 0, 接下来我们 clear() 一下,让恢复指针。
123456DataReceiver5:
mark = java.nio.ByteArrayBuffer[position=0,limit=100,capacity=100]
position = 0
limit = 100
capacity = 100
remaing = 100
如果我们此时的数据不到 18 位,则上面的判断结果会是 false, 此时会执行 compat() 方法,假设第一次的数据长度只有 6 位,则该方法执行后的结果如下:
123456DataReceiver6:
mark = java.nio.ByteArrayBuffer[position=6,limit=100,capacity=100]
position = 6
limit = 100
capacity = 100
remaing = 94
可以看到执行 compat() 方法的时候 position 的位置并没有发生改变,而 limit 则恢复到了 limit = capacity, 所以此时再次接收数据会追加到之前的数据后面。
因此我们可以简单的得出一个结论,push() 完之后 position 就是数据实际长度, 而flip() 方法会使 position 指针归 0 ,当我们需要继续追加数据的时候,在 put 方法前请调用一次 compat() 让读取完后的指针 position 归位(实际数据长度的位置)再调用 push() 追加, 如果我们需要重置一次指针(清除所有数据)则调用一次 clear()。















 1847
1847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









