






监督学习解决的问题 监督学习 学习两个数据集之间的联系:观测数据X和我们试图预测的外部变量
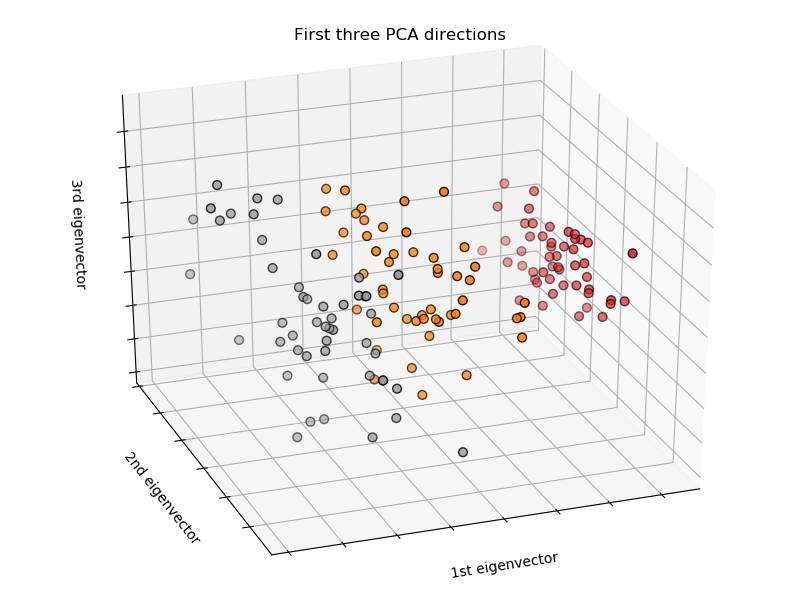 iris(鸢尾花)数据集是一个分类任务,根据(Setosa, Versicolour, and Virginica)花瓣和萼片长度和宽度来对3种不同类型的鸢尾花进行分类:
iris(鸢尾花)数据集是一个分类任务,根据(Setosa, Versicolour, and Virginica)花瓣和萼片长度和宽度来对3种不同类型的鸢尾花进行分类:
y ,通常称为“目标”或“标签”。通常情况下,
y 是长度为
n_samples 的一维数组。 scikit-learn中所有的监督学习估计器都有一个用来拟合模型的
fit(X, y) 函数和输入未标记的观察值
X ,返回预测标记
y 的
predict(X) 方法。
分类与回归 如果预测任务是将观测值分类到一组有限的标签集合中,换句话说就是“命名”观察到的物体,则称为
分类任务。如果是预测的是连续目标变量,称为
回归任务。 在scikit learn中进行分类时,
y 是整数或字符型向量。 注:请参阅 使用scikit-learn的机器学习简介教程( https://scikit-learn.org/stable/tutorial/basic/tutorial.html#introduction )快速浏览 scikit-learn 中使用的基础机器学习概念。
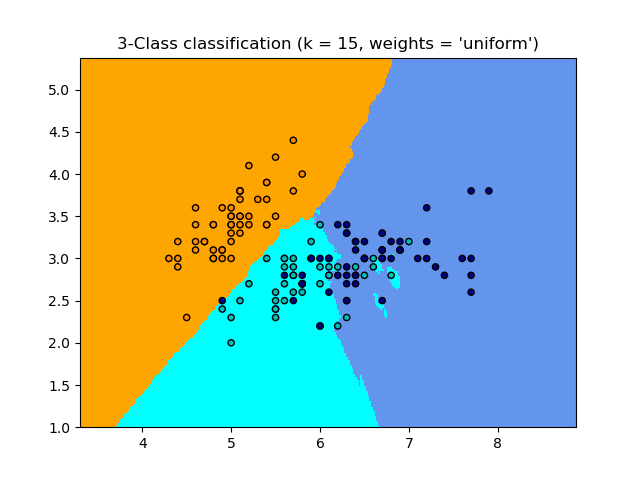
最近邻分类器与维度惩罚
irises(鸢尾花)分类: iris(鸢尾花)数据集是一个分类任务,根据(Setosa, Versicolour, and Virginica)花瓣和萼片长度和宽度来对3种不同类型的鸢尾花进行分类:
>>> import numpy as np>>> from sklearn import datasets>>> iris_X, iris_y = datasets.load_iris(return_X_y=True)>>> np.unique(iris_y)array([0, 1, 2])k近邻分类器
最近邻分类器最简单的分类器: 给定一个新的观测数据X_test ,在训练集(即训练估计器所用的数据)中找到最接近特征向量的观测值。(有关此分类器的更多详细信息,请参阅 Scikit-learn 文档的最近邻分类器章节 https://scikit-learn.org/stable/modules/neighbors.html#neighbors 。)
训练集和测试集 在尝试使用任何机器学习算法进行实验时,最重要的是不要在用于拟合估计器的数据上测试估计器的预测值,因为这没有办法体现出估计器在
新数据上的性能。这就是为什么数据集经常被分成_train_和_test_数据的原因。
KNN (k近邻) 分类示例 :
>>> # 将iris(鸢尾花)数据分成训练数据和测试数据>>> # 随机排列,使得数据随机划分>>> np.random.seed(0)>>> indices = np.random.permutation(len(iris_X))>>> iris_X_train = iris_X[indices[:-10]]>>> iris_y_train = iris_y[indices[:-10]]>>> iris_X_test = iris_X[indices[-10:]]>>> iris_y_test = iris_y[indices[-10:]]>>> # 创建和训练最近邻分类器>>> from sklearn.neighbors import KNeighborsClassifier>>> knn = KNeighborsClassifier()>>> knn.fit(iris_X_train, iris_y_train)KNeighborsClassifier()>>> knn.predict(iris_X_test)array([1, 2, 1, 0, 0, 0, 2, 1, 2, 0])>>> iris_y_testarray([1, 1, 1, 0, 0, 0, 2, 1, 2, 0]) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1320
1320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









