






Python基础初识
1、Python介绍
1.1、Python简介
Python是著名的“龟叔”Guido van Rossum在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言,Python官方网站 。
Python是一种计算机程序设计语言。你可能已经听说过很多种流行的编程语言,比如非常难学的C语言,非常流行的Java语言,适合初学者的Basic语言,适合网页编程的JavaScript语言等等。
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
解释型语言:这意味着开发过程中没有编译环节,类似于PHP和Perl语言。
交互式语言:这意味着可以在一个Python提示符直接互动执行你写的程序。
面向对象语言:这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
1.2、Python特点
易于学习:Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
易于阅读:Python代码定义的更清晰。
易于维护:Python的成功在于它的源代码是相当容易维护的。
丰富的标准库:Python的最大的优势之一是丰富的库,跨平台的,在UNIX,Windows和Macintosh兼容很好。
互动模式:互动模式的支持,您可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片断。
可移植:基于其开放源代码的特性,Python已经被移植(也就是使其工作)到许多平台。
可扩展:如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那部分程序,然后从你的Python程序中调用。
数据库:Python提供所有主要的商业数据库的接口。
GUI编程:Python支持GUI可以创建和移植到许多系统调用。
可嵌入: 你可以将Python嵌入到C/C++程序,让你的程序的用户获得"脚本化"的能力。
1.3、Python应用领域
云计算: 云计算最火的语言, 典型应用OpenStack
WEB开发: 众多优秀的WEB框架,众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣。。。, 典型WEB框架有Django
科学运算、人工智能: 典型库NumPy, SciPy, Matplotlib, Enthought librarys,pandas
系统运维: 运维人员必备语言
金融:量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很牛逼,生产效率远远高于c,c++,java,尤其擅长策略回测
图形GUI: PyQT, WxPython,TkInter
1.4、Python解释器的种类
当我们编写Python代码时,我们得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件。
CPython
Python的官方版本,使用C语言实现,使用最为广泛,CPython会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。
PyPy
Python实现的Python,PyPy运行在CPython(或者其它实现)之上,用户程序运行在PyPy之上,将Python的字节码再动态编译成机器码(非解释),它的目标是执行速度。
其它Python
如Jyhton、IronPython、RubyPython、Brython等。
小结:
Python的解释器很多,但使用最广泛的还是CPython。如果要和Java或.Net平台交互,最好的办法不是用Jython或IronPython,而是通过网络调用来交互,确保各程序之间的独立性。
2、Python基础初识
2.1、运行python代码
在桌面下创建一个t1.py文件内容是:
print('hello world')
打开windows命令行输入cmd,确定后 写入代码python t1.py
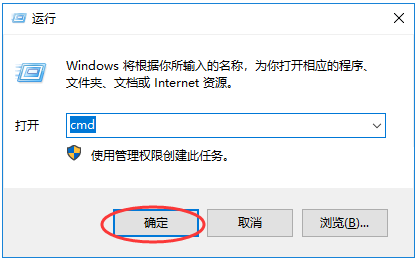

在这里也可以切换成python2.x的环境进行运行,但是2.x版本和3.x版本是有一定区别的。
python2和python3的区别:
python2:默认编码方式为ascii编码。解决方式:在文件的首行添加:-*- coding: utf-8 -*-
python3:默认编码方式utf-8
2.2、变量
变量:把程序运行的中间结果临时的存在内存里,以便后续的代码调用。
声明变量:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
name = "beijing"
上述代码声明了一个变量,变量名为: name,变量name的值为:"taibai"
变量的作用:昵称,其代指内存里某个地址中保存的内容。
变量定义的规则:
1、必须由数字,字母,下划线任意组合,且不能数字开头。
2、不能是python中的关键字。['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
3、变量具有可描述性,看名知意。
4、不建议使用中文作为变量名称,遵守规范。
推荐变量的定义方式:
#驼峰体
AgeOfKimboy = 26
NumberOfStudents = 80
#下划线
age_of_kimboy = 56
number_of_students = 80
变量的赋值
#!/usr/bin/env python
# -*- coding: utf-8 -*-
name1 = "wusong"
name2 = "suwukong"
student1 = "tangseng"
student2 = student1
2.3、常量
常量即指不变的量,如π 3.141592653..., 或在程序运行过程中不会改变的量
2.4、注释
当行注释:# 被注释内容
多行注释:'''被注释内容''',或者 """被注释内容"""
2.5、用户交互
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 将用户输入的内容赋值给 name 变量
name = input("请输入用户名:")
# 打印输入的内容
print(name)
执行结果:
E:\Python19\venv\Scripts\python.exe E:/Python19/DAY01/t2.py
please input your name:kimi
kimi
Process finished with exit code 0
执行脚本就会发现,程序会等待你输入姓名后再往下继续走。 同时也可以让用户输入多个信息,如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
name = input("what is your name?")
age = input("how old are you?")
hometown = input("where are you come from?")
print("hello",name,"you are",age,"years old,you come from",hometown)
执行结果:
E:\Python19\venv\Scripts\python.exe E:/Python19/DAY01/t2.py
what is your name?kimi
how old are you?26
where are you come from?China
hello kimi you are 26 years old,you come from China
2.6、基础数据类型了解
什么是数据类型?
我们人类可以很容易的分清数字与字符的区别,但是计算机并不能呀,计算机虽然很强大,但从某种角度上看又很傻,除非你明确的告诉它,1是数字,“汉”是文字,否则它是分不清1和‘汉’的区别的,因此,在每个编程语言里都会有一个叫数据类型的东东,其实就是对常用的各种数据类型进行了明确的划分,你想让计算机进行数值运算,你就传数字给它,你想让他处理文字,就传字符串类型给他。Python中常用的数据类型有多种,今天我们暂只讲3种, 数字、字符串、布尔类型
2.6.1、整数类型(int)
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
PS:在Python3中不再有long整型,全部都为int类型
>>> a= 2**64
>>> type(a) #type()是查看数据类型的方法
>>> b = 2**60
>>> type(b)
2.6.2、字符串类型(str)
在Python中,加了引号的字符都被认为是字符串!!!!
>>> name = "Kimi Li" #双引号
>>> age = "26" #只要加引号就是字符串
>>> age2 = 26 #int类型
>>>
>>> msg = '''My name is taibai, I am 22 years old!''' #3个引号也可以
>>>
>>> hometown = 'Guangdong' #单引号也可以
单引号、双引号、多引号基本没什么区别,但是在以下这种情况时,需要考虑单双的配合:
msg = "My name is Kimi, I'm 26 years old!"
多引号什么作用呢?作用就是多行字符串必须用多引号
#!/usr/bin/env python
# -*- coding: utf-8 -*-
msg = '''
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
'''
print(msg)
执行结果:
E:\Python19\venv\Scripts\python.exe E:/Python19/DAY01/t2.py
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
Process finished with exit code 0
字符串的拼接
数字可以进行加减乘除等运算,字符串呢?是的,但只能进行"相加"和"相乘"运算。
>>> name = 'kimi'
>>> print(name)
kimi
>>> age = '26'
>>> name + age#相加其实就是简单拼接
'kimi26'
>>> name * 5#相乘其实就是复制自己多少次,再拼接在一起
'kimikimikimikimikimi'
**注意,字符串的拼接只能是双方都是字符串,不能跟数字或其它类型拼接 **
>>> age2 =30
>>> type(name),type(age2)
(, )
>>> name
'kimi'
>>> age2
30
>>> name + age2
Traceback (most recent call last):
File "", line 1, in
TypeError: can only concatenate str (not "int") to str#错误提示数字 和 字符 不能拼接
2.6.3、布尔值(True、False)
布尔类型很简单,就两个值 ,一个True(真),一个False(假), 主要用记逻辑判断
现在有2个值 , a=3, b=5 , 我说a>b你说成立么? 我们当然知道不成立,但问题是计算机怎么去描述这成不成立呢?或者说a< b是成立,计算机怎么描述这是成立呢?
没错,答案就是,用布尔类型
>>> a=3
>>> b=5
>>>
>>> a > b #不成立就是False,即假
False
>>>
>>> a < b #成立就是True, 即真
True
2.7、流程控制语句if
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。
单分支
if 表达式1:
语句
双分支
if 表达式1:
语句1
else:
语句2
多分支
if 表达式1:
语句
elif 表达式2:
语句
else:
语句
if嵌套
if 表达式1:
语句
if 表达式2:
语句
elif 表达式3:
语句
else:
语句
elif 表达式4:
语句
else:
语句
注意:
1、每个条件后面要使用冒号 :,表示接下来是满足条件后要执行的语句块。
2、使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。
3、在Python中没有switch – case语句。
#!/usr/bin/python
# -*- coding:utf-8 -*-
score = int(input("输入分数:"))
if score > 100:
print("我擦,最高分才100...")
elif score >= 90:
print("A")
elif score >= 80:
print("B")
elif score >= 60:
print("C")
elif score >= 40:
print("D")
else:
print("太笨了...E")
执行结果:
E:\Python19\venv\Scripts\python.exe E:/Python19/DAY01/t2.py
输入分数:10
太笨了...E
Process finished with exit code 0
这里有个问题,就是当我输入95的时候 ,它打印的结果是A,但是95 明明也大于第二个条件elif score >=80:呀, 为什么不打印B呢?这是因为代码是从上到下依次判断,只要满足一个,就不会再往下走啦,这一点一定要清楚呀!
2.8、循环语句while
2.8.1、语法
while 判断条件:
语句
同样需要注意冒号和缩进。另外,在Python中没有do..while循环。
使用while 来打印1-100:
********方法一********
count = 1
flag = True
#标志位
while flag:
print(count)
count = count + 1
if count > 100 :
flag = False
********方法二********
count = 1
while count <= 100:
print(count)
count = count + 1
计算1-100的总和
count = 1
sum = 0
while count <= 100:
sum = sum + count
count = count + 1
print(sum)
2.8.2、终止循环语句
如果在循环的过程中,因为某些原因,你不想继续循环了,怎么把它中止掉呢?这就用到break 或 continue 语句
break用于完全结束一个循环,跳出循环体执行循环后面的语句
continue和break有点类似,区别在于continue只是终止本次循环,接着还执行后面的循环,break则完全终止循环
例子:break
count = 0
while count <= 100 : #只要count<=100就不断执行下面的代码
print("loop ", count)
if count == 5:
break
count +=1 #每执行一次,就把count+1,要不然就变成死循环啦,因为count一直是0
print("-----out of while loop ------")
执行结果:
E:\Python19\venv\Scripts\python.exe E:/Python19/DAY01/t1.py
loop 0
loop 1
loop 2
loop 3
loop 4
loop 5
-----out of while loop ------
Process finished with exit code 0
**例子:continue **
count = 0
while count <= 100 :
count += 1
if count > 5 and count < 95: #只要count在6-94之间,就不走下面的print语句,直接进入下一次loop
continue
print("loop ", count)
print("-----out of while loop ------")
执行结果:
E:\Python19\venv\Scripts\python.exe E:/Python19/DAY01/t1.py
loop 1
loop 2
loop 3
loop 4
loop 5
loop 95
loop 96
loop 97
loop 98
loop 99
loop 100
loop 101
-----out of while loop ------
Process finished with exit code 0
2.8.3、while...else
在Python当中还有一个while ... else...语句
while后面的else的作用:当while循环正常执行完毕,中间无berak终止的话,就会执行else后面的语句。
#!/usr/bin/python
# -*- coding:utf-8 -*-
count = 0
while count < 5:
count += 1
print("Loop",count)
else:
print("The loop is over.")
print("------while loop is exitd------")
执行结果:
Loop 1
Loop 2
Loop 3
Loop 4
Loop 5
The loop is over.
------while loop is exitd------
从上面可以看到,循环过程中没有break,会自动去执行else后面的语句。当执行过程被break终止了,就不会再去执行else后面的语句,如下:
#!/usr/bin/python
# -*- coding:utf-8 -*-
count = 0
while count < 5:
count += 1
if count == 3:break
print("Loop",count)
else:
print("The loop is over.")
print("------while loop is exitd------")
执行结果:
Loop 1
Loop 2
------while loop is exitd------
2.9、练习题
1、使用while循环输入 1 2 3 4 5 6 8 9 10
count = 0
while count < 10:
count = count + 1
if count == 7:
print(' ')
else:
print(count)
2、求1-100的所有数的和
count = 1
sum = 0
while count <= 100:
sum = sum +count
count = count + 1
print(sum)
3、输出 1-100 内的所有奇数
#方法一:
count = 1
while count < 101:
print(count)
count += 2
#方法二:
count = 1
while count <= 100:
num = count % 2
if num != 0:
print(count)
count = count + 1
4、输出 1-100 内的所有偶数
count = 1
while count <= 100:
num = count % 2
if num == 0:
print(count)
count = count + 1
5、求1-2+3-4+5 ... 99的所有数的和
sum = 0
count = 1
while count < 100:
if count % 2 == 0:
sum -= count
else:
sum += count
count += 1
print(sum)
6、用户登陆(三次机会重试)
i = 0
while i < 3:
username = input('Please input your username:')
password = input('Please input your password:')
if username == 'kimi' and password == '123123':
print('Login sucess!!')
else:
print('Login Failed,Please retry again!')
i += 1
2.10、格式化输出
现有一需求,问用户的姓名、年龄、工作、爱好,需要按以下格式打印个人信息
------------ info of Kimi Li -----------
Name : Kimi Li
Age : 26
job : sales
Hobbie: football
------------- end -----------------
如果使用字符拼接的方式,还是相对来说比较难实现这样的格式化输出的。为此Python当中有一种格式化输出的方法。
只需要把打印的格式准备好,并使用占位符(% s d),再将字符串的占位符和外部的变量进行映射即可。如下:
#!/usr/bin/python
# -*- coding:utf-8 -*-
name = input("Please input your name:")
age = input("Please input your age:")
job = input("Please input your job:")
hobbie = input("Please input your hobbie:")
info = '''
---------- info of %s ----------#这里的每个%s就是一个占位符,本行的代表 后面拓号里的 name
Name : %s #代表 name
Age : %s#代表 age
Job : %s#代表 job
Hobbie : %s#代表 hobbie
------------ end ---------------
''' %(name,name,age,job,hobbie)# 这行的 % 号就是 把前面的字符串 与括号 后面的 变量 关联起来
print(info)
执行结果:
E:\Python19\venv\Scripts\python.exe E:/Python19/DAY01/format.py
Please input your name:Kimi
Please input your age:26
Please input your job:sales
Please input your hobbie:football
---------- info of Kimi ----------
Name : Kimi
Age : 26
Job : sales
Hobbie : football
------------ end ---------------
Process finished with exit code 0
%s就是代表字符串占位符,除此之外,还有%d,是数字占位符, 如果把上面的age后面的换成%d,就代表你必须只能输入数字啦
#!/usr/bin/python
# -*- coding:utf-8 -*-
name = input("Please input your name:")
age = input("Please input your age:")
job = input("Please input your job:")
hobbie = input("Please input your hobbie:")
info = '''
---------- info of %s ----------
Name : %s
Age : %d#换成%d的数字占位符,该变量必须是一个数字,否则会报错
Job : %s
Hobbie : %s
------------ end ---------------
''' %(name,name,age,job,hobbie)
print(info)
当我们输入age的值是一个字符串或者是数字时,会报以下错误:
Traceback (most recent call last):
File "E:/Python19/DAY01/format.py", line 16, in
''' %(name,name,age,job,hobbie)
TypeError: %d format: a number is required, not str
这是为什么的???要知道的是input接收的所有输入默认都是字符串格式!!此时就需要进行类型转换。
age = int(input("Please input your age:"))#使用int对age的输入值,str转换成init类型
现在有这样的一行代码:
msg = "我是%s,年龄%d,目前学习进度为50%" %('Kimi',26)
print(msg)
执行结果:
Traceback (most recent call last):
File "E:/Python19/DAY01/format.py", line 19, in
msg = "我是%s,年龄%d,目前学习进度为50%"%('Kimi',26)
ValueError: incomplete format
因为在格式化输出里,出现%默认为就是占位符的%,但是想在上面一条语句中最后的80%就是表示80%而不是占位符,怎么办?
msg = "我是%s,年龄%d,目前学习进度为50%%" %('Kimi',26)
print(msg)
这样就可以了,第一个%是对第二个%的转义,告诉Python解释器这只是一个单纯的%,而不是占位符。
2.11、编码
电脑的传输,还有储存的实际上都是0101010101。我们在硬盘上看到的多少GB甚至TB的存储量,实际在计算机中的具体表示都为二进制。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。

从上面的编码表格上知道,在编码的最左边一位全部都是0。最初设计者使用7位的二进制已经足够表示所有的英文、特殊字符等,然而设计者为了拓展,于是预留出1位的。于是就有2**8=256种方式对英文进行表示。那对于编码的单位有以下的规则:
8位(bit)表示1个字节(byte)
1024字节 = 1kb
1024kb = 1MB
1024MB = 1GB
1024GB = 1TB
由于计算机的发展,最初美国设计的ascii码无法满足世界的通用。比如ascii码无法满足对中文的编码。为了解决这个全球化的文字问题,创建了 一个万国码--unicode。
我们知道1个字节,可以表示所有的英文和特殊字符以及数字等等。那么1个中文需要多少个字节来表示中文呢?最初开始使用2个字节表示1个中文,但是远远不够。于是unicode编码一个中文使用32位来表示,那么一共会有2**32=4294967296。这样就显得太过于浪费,针对这种的现象,于是对unicode进行升级。则出现了utf-8的编码方式:一个中文用3个字节去表示,即:2**24=16777216,这样就可以包含了所有的语言表示。
还有一种编码方式是GBK,是属于国内自创的一种编码方式,仅供国内使用。一个中文用2个字节表示。但是无法包含所有的中文。
2.12、运算符
Python语言支持以下类型的运算符:
算术运算符
比较(关系)运算符
赋值运算符
逻辑运算符
位运算符
成员运算符
身份运算符
运算符优先级
算术运算符
以下假设变量a为10,变量b为21:
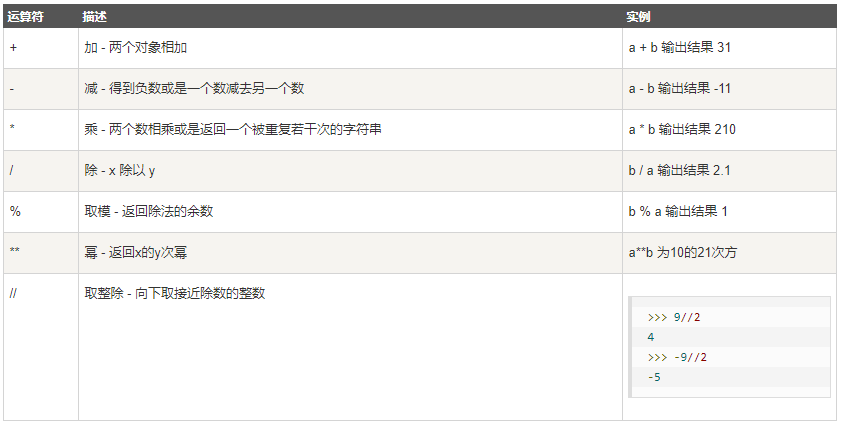
比较运算符
以下假设变量a为10,变量b为20:
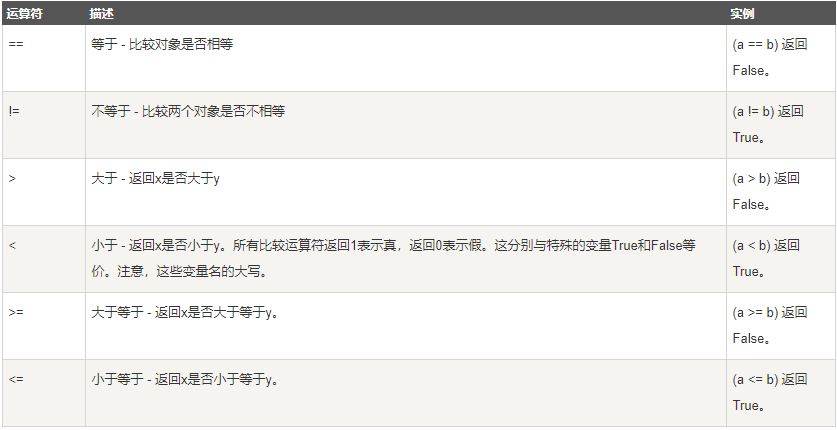
赋值运算符
以下假设变量a为10,变量b为20:
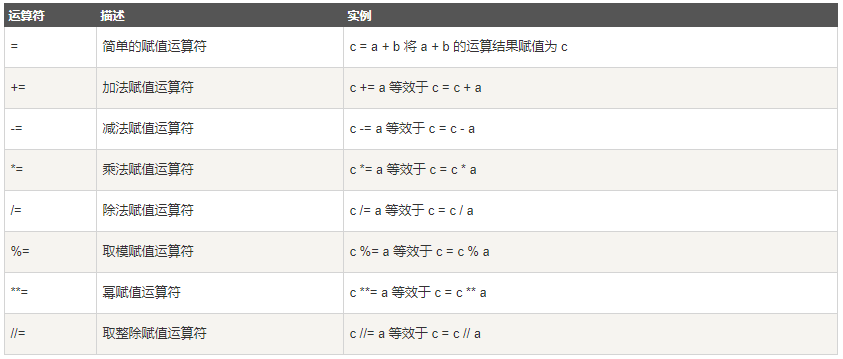
逻辑运算符
以下假设变量 a 为 10, b为 20:

针对逻辑运算符,需要有以下的了解:
1、在没有()的情况下,not优先级高于and,and优先级高于or,即优先级关系为:()> not > and > or,同一优先级从左往右计算。如下例题:
#!/usr/bin/python
# -*- coding:utf-8 -*-
print(3>4 or 4<3 and 1==1) #False
print(1 < 2 and 3 < 4 or 1>2) #True
print(2 > 1 and 3 < 4 or 4 > 5 and 2 < 1) #True
print(1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8) #False
print(1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6) #False
print(not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6) #False
print(not 2 < 1) #True
2、x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。
'''x or y x为True,则返回x; x 为False,则返回Y'''
print(1 or 2) # x为非0,为True,返回1
print(3 or 2) # x为非0,为True,返回3
print(0 or 2) # x为0,为False,返回2
print(0 or 100) # x为0,为False,返回100
print(2 or 100 or 3 or 4) # 从左往右,一次计算,返回2
'''x and y x为True,则返回y;x为False,则返回x'''
print(1 and 2)# x为非0,返回2
print(0 and 2)# x为0,返回0
print(2 or 1 < 3)#先比较1< 3为False,即为0;2 or 0 返回2
***********or 和 and 混合***********
print(3 > 1 or 2 and 2)#优先级计算and,为2;1 or 2 ,返回1;3 > 1,返回True
成员运算
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。

#!/usr/bin/python
# -*- coding:utf-8 -*-
a = 10
b = 20
list = [1, 2, 3, 4, 5 ];
if ( a in list ):
print ("1 - 变量 a 在给定的列表中 list 中")
else:
print ("1 - 变量 a 不在给定的列表中 list 中")
if ( b not in list ):
print ("2 - 变量 b 不在给定的列表中 list 中")
else:
print ("2 - 变量 b 在给定的列表中 list 中")
# 修改变量 a 的值
a = 2
if ( a in list ):
print ("3 - 变量 a 在给定的列表中 list 中")
else:
print ("3 - 变量 a 不在给定的列表中 list 中")
执行结果:
E:\Python19\venv\Scripts\python.exe E:/Python19/DAY01/逻辑运算符.py
1 - 变量 a 不在给定的列表中 list 中
2 - 变量 b 不在给定的列表中 list 中
3 - 变量 a 在给定的列表中 list 中
2.13、数据类型
Python中常用的数据类型有很多种,如下:
类型
用途
int
整型,数字,主要用于运算,如1,2,3
bool
布尔型,用于判断真假,True 和 False
str
字符串,简单少量的存储数据,并进行相应的操作。name = 'kimi'
list
列表,大量有序数据存储,比如[1,2,3,'123',[4,5,6],'tiger']
tuple
元祖,相当于一个只读列表,无法更改,比如(1,2,3,'第三方')
dict
字典,大量有关联性比较强的数据,比如{'name':'kimi','age':'20'}
set
集合,工作中几乎用不到。{1,2,3,'abc'},面试可能用到
2.13.1、int(整型)
整型是常见的数据类型,主要有用于计算,所以针对数字可以使用的方法除了运算以外,并没有什么常用的方法,python中提供了一种方法,用于快速计算证书在内存中占用的二进制码的长度:bit_length()
#!/usr/bin/python
# -*- coding:utf-8 -*-
num = 10
print(num.bit_length())
#运行结果:4
2.13.2、bool(布尔型)
布尔值就两种:True和False,反应条件的正确与否。再看看int str bool三者数据类型的转换
# int --> bool
i = 10
print(bool(i))#True,非0即是True
a = 0
print(bool(a))#False,0即是False
#bool --> int
t = True
print(int(t))# 1 True--> 1
t = False
print(int(t))#0 False --> 0
#int --> str
i = 100
print(str(i))#'100'
#str --> bool
s1 = '中国'
s2 = ''
print(bool(s1))#True,非空就是True
print(bool(s2))#False
#bool --> str
t = True
print(str(t))#'True'
2.13.3、str(字符串)
Python中凡是用引号引起来的数据可以称为字符串类型,组成字符串的每个元素称之为字符,将这些字符一个一个连接起来,然后在用引号起来就是字符串。
1、字符串的索引和切片
组成字符串的字符从左至右,依次排列,他们都是有顺序的。索引即下标,就是字符串组成的元素从第一个开始,初始索引为0以此类推。看下面的例子:
a = 'ABCDEFGHIJKLMN'
print(a[0])#A
print(a[1])#B
print(a[4])#E
print(a[7])#H
切片就是通过索引(索引:索引:步长)截取字符串的一段,形成新的字符串(原则就是顾头不顾尾),如下:
a = 'ABCDEFGHIJKLMN'
print(a[0:3])#ABC
print(a[2:5])#CDE
print(a[:])#ABCDEFGHIJKLMN,默认到切片从头到尾
print(a[:-1]) #ABCDEFGHIJKLM,-1 是列表中最后一个元素的索引,但是要满足顾头不顾尾的原则,所以取不到K元素
print(a[:5:2])#ACE,从0到5,加步长为2,
print(a[-1:-5:-2])#NL,反向加步长
2、字符串的常用方法
方法
描述
capitalize()
将字符串的第一个字符转换为大写
upper()
转换字符串中的小写字母为大写
lower()
转换字符串中所有大写字符为小写
swapcase()
将字符串中大写转换为小写,小写转换为大写
center(width, fillchar)
返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。
expandtabs()
把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。
len()
返回字符串长度
startswith()
检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。
endswith()
检查字符串是否以 某个字符 结束,如果是,返回 True,否则返回 False.
find()
检测 str 是否包含在字符串中,如果包含返回开始的索引值,否则返回-1
index()
跟find()方法一样,只不过如果str不在字符串中会报一个异常
strip()
在字符串上执行 lstrip()和 rstrip()
rstrip()
删除字符串字符串末尾的空格
lstrip()
截掉字符串左边的空格或指定字符
count()
返回 str 在 string 里面出现的次数
split()
以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串
format()
格式化字符串
replace()
把 将字符串中的 str1 替换成 str2,如果 max 指定,则替换不超过 max 次。
title()
返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写
实践出真知:
####大小写转换
s = 'i am come from China'
print(s.capitalize())#I am come from china字符串第一个字符转换成大写
print(s.upper()) #I AM COME FROM CHINA字符串所有小写字母转换成大写
print(s.lower())#i am come from china字符串所有的大写字母换成小写
#大小写转换,可以用在验证码阶段,如:
s_str = 'aEbF'
code_input = input('请输入验证码,不区分大小写:')
if s_str.upper() == code_input.upper():
print('验证码通过')
else:
print('请重新输入')
####一次大小写转换
print(s.swapcase())#I AM COME FROM cHINA字符串中大写变小写,小写变大写
####特殊字符相隔后首字母大写
s = 'alex*egon-wusir'#特殊字符隔开后的单词首字母大写
print(s.title())#Alex*Egon-Wusir
####字符居中,填充,主要用于表格制作
s = 'ChinaStyle'#将s的字符以20个字符居中,不够20用$进行填充,默认是空格填充
print(s.center(20,'$'))#$$$$$ChinaStyle$$$$$
s = 'China*&Style_Bei6Jing_TianAnMen'
print(s.title())#China*&Style_Bei6Jing_Tiananmen
####统计字符串长度
print(len(s))#31 计算字符长度
####判断以什么开头和结尾
print(s.startswith('C'))#True,判断s字符串是否以C开头,为真返回True,否则返回False
print(s.endswith('N'))#False,判断s字符串是否以N结尾
print(s.endswith('*',1,6))#True,也可以指定切片长度进行判断
####通过元素找索引,find找不到返回-1,index找不到直接报错
print(s.find('S'))#查看字符串中的S,返回索引值为7,如果找不到该字符,会返回-1
print(s.find('K'))#-1,同样还可以通过index进行查找,但是index在找不到情况下会报错
print(s.index('S'))#7
print(s.index('K'))#ValueError: substring not found
####删除空格或指定字符
s = ' %%cHina_Style &Bei Jing '
print(s.strip())#%%cHina_Style &Bei Jing ,默认删除字符串两边的空格
s = '%%cHina_Style &Bei Jing &'
print(s.strip('%'))#cHina_Style &Bei Jing &,也可以指定删除字符
print(s.rstrip('&'))#%%cHina_Style &Bei Jing
print(s.lstrip('%'))#cHina_Style &Bei Jing &
#应用在输入用户名或验证码时,错误输入多个空格的情况,如下
username = input('请输入名字:').strip()
if username == "kimi":
print("welcome kimi!")
执行结果:
请输入名字:kimi #输入时增加空格
welcome kimi!
####字符串统计
s = 'China*&Style_Bei6Jing_TianAnMen'
print(s.count('an'))#1,统计字符串出现的次数
####字符串切割,可以指定切割符号
print(s.split('_'))#['China*&Style', 'Bei6Jing', 'TianAnMen'],切割字符串,指定切割符号为_,切割后会生成一个列表
####字符串format的三种格式化输出,比%s和%d好用
s = '我的名字是{},今年{}岁,来自{}'.format('kimi',20,'广东')
print(s)#我的名字是kimi,今年20岁,来自广东
s = '我的名字是{0},今年{1}岁,来自{2}'.format('kimi',20,'广东')
print(s)#我的名字是kimi,今年20岁,来自广东
s = '我的名字是{name},今年{age}岁,来自{city}'.format(name='kimi',age=20,city='广东')
print(s)#我的名字是kimi,今年20岁,来自广东
####replace替换字符
s = '我们都是祖国的花朵,花朵开得正旺盛!'
print(s.replace('花朵','huaduo'))#默认会把字符中的花朵全部替换成huaduo
print(s.replace('花朵','huaduo',1))#仅替换一个花朵
####is系列,判断字符串的组成,可用在用户输入判断
s = 'I want to go buy something for 123'
print(s.isdigit())#False,判断s是否只由数字组成
s1 = 'tian123'
print(s1.isalnum())#True,判断字符串由字母或数字组成
print(s1.isalpha())#False,字符串只由字母组成
print(s1.isdecimal())#False,字符串只由十进制组成
练习题:content = input('请输入内容') 如 5+9进行计算
content = input('请输入:').strip()
index = content.find('+')
a = int(content[0:index])
b = int(content[index+1:])
print(a + b)
2.13.4、list(列表)
我们现在已经学过的数据类型有:数字,布尔值,字符串,大家都知道数字主要用于计算,bool值主要是条件判断,只有字符串可以用于数据的存储,这些数据类型够用么?对于一门语言来说,肯定是不够用的。就说字符串:
(1)字符串只能存储少量的数据,对于大量的数据用字符串操作不方便也不易存储。
(2)字符串存储的数据类型太单一,只能是字符串类型。
例如:‘1 True alex’ 像这样的字符串,我如果通过切片或者其他方法将1 True alex 取出来,他也只能是字符串,但是我想要得到数字的1,布尔值的True,必须还要转化,是不是很麻烦。
所以python给咱们也提供了一类数据类型,他能承载多种数据类型,这类数据类型被称作容器类数据类型可以存储大量的数据。列表就属于容器类的数据类型。
这个数据类型就是list列表。
列表是python的基础数据类型之一 ,其他编程语言也有类似的数据类型.比如JS中的数 组, java中的数组等等. 它是以[ ]括起来, 每个元素用' , '隔开而且可以存放各种数据类型: 列表是python中的基础数据类型之一,其他语言中也有类似于列表的数据类
型,比如js中叫数组,他是以[]括起来,每个元素以逗号隔开,而且他里面可以存放各种数据类型比如:
li = [‘alex’,123,Ture,(1,2,3,’wusir’),[1,2,3,’小明’,],{‘name’:’alex’}]
列表相比于字符串,不仅可以储存不同的数据类型,而且可以储存大量数据,32位python的限制是 536870912 个元素,64位python的限制是 1152921504606846975 个元素。而且列表是有序的,有索引值,可切片,方便取值。
1、列表的创建
# 创建一个列表有三种方式:
# 方式一:(常用)
l1 = [1, 2, 'kimi']
# 方式二:(不常用)
l1 = list() # 空列表
# l1 = list(iterable) # 可迭代对象
l1 = list('123')
print(l1) # ['1', '2', '3']
# 方式三:列表推导式
l1 = [i for i in range(1,5)]
print(l1) # [1, 2, 3, 4]
2、列表的常用方法
以该列表为主进行操作:li = ['kimi','AD','China']
列表使用
方法
举例
结果
描述
增加
append
li.append('HongKong')
['kimi', 'AD', 'China', 'HongKong']
在列表末尾添加新的元素
插入
insert
li.insert(1,'g')
['kimi', 'g', 'AD', 'China']
将对象插入列表,需要指定在哪个元素前进行插入,通过索引值进行标识
迭代
extend
li.extend([1,2,3])
['kimi', 'AD', 'China', 1, 2, 3]
在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
元素删除
pop
li.pop() li.pop(1)
['kimi', 'AD'] ['kimi', 'China']
移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
remove
li.remove('China')
['kimi', 'AD']
移除列表中某个值的第一个匹配项
清空
clear
li.clear()
[]
清空列表
列表删除
del
del(li)
name 'li' is not defined
删除列表,删除列表后进行打印就会报错
列表复制
copy
l2 = li.copy() print(l2)
['kimi', 'AD', 'China']
复制列表
更改
按索引
li[2] = 'KK'
['kimi', 'AD', 'KK']
根据索引进行修改元素
切片修改
li[0:1] = [1,2,3]
[1, 2, 3, 'AD', 'China']
根据切片进行修改,这里修改第一元素,更改的元素会进行拆分填充
查询
索引查询
print(li[0])
kimi
根据元素索引查询
切片查询
print(li[0:2])
['kimi', 'AD']
切片查询
查询每个元素
for i in li: print(i)
kimi
AD
China
通过for循环进行迭代查询
统计
len
print(len(li))
3
统计列表元素个数
计数
count
print(li.count('AD'))
1
统计某个元素在列表中出现的次数
索引值
index
print(li.index('kimi'))
0
从列表中找出某个值第一个匹配项的索引位置,并返回索引值
排序
sort
li = [19,3,4,21,5,6] li.sort() print(li)
[3, 4, 5, 6, 19, 21]
对原列表进行排序
倒序
sort(revers=True)
li = [19,3,4,21,5,6] li.sort(reverse=True) print(li)
[21, 19, 6, 5, 4, 3]
对原列表排序后倒序
反转
reverse
li = [19,3,4,21,5,6] li.reverse() print(li)
[6, 5, 21, 4, 3, 19]
反转列表中元素














 5247
5247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









