






———————————学无止境———————————
前言:大家好,我的每篇文章都是自己用心编写,算不上精品但是足够用心分享我所学的知识,希望大家能够指正我,互相学习成长。转载请注明:
ZXPXBB:Pyhton网络爬虫实例_豆瓣电影排行榜_BeautifulSoup4方法爬取zhuanlan.zhihu.com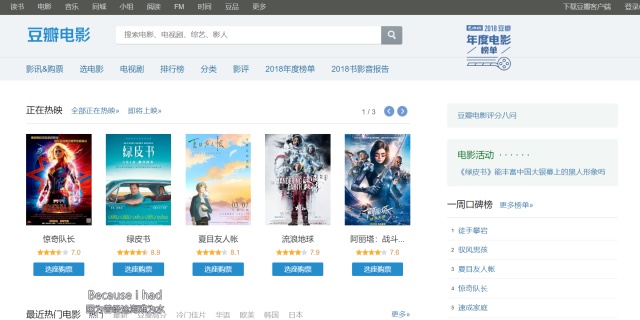
——————————学无止境————————————
前言:大家好,我的每篇文章都是自己用心编写,算不上精品但是足够用心分享我所学的知识,希望大家能够指正我,互相学习成长。
转载请注明:https://www.cnblogs.com/wyl-pi/p/10510397.html
很多小伙伴可定都是喜欢看电影的,比如特效炫酷逼真的好莱坞大片,情节感人真挚的爱情电影,打斗激情四射的动作电影,,,,
所以我相信大家都有一个通问,我想看电影,但是呢到底什么电影好看啊!!有没有什么推荐之类的,比如排行榜之类的还不是很多的,
10个左右的(多了看不完还挺难受,但太多的话根本没时间看完啊,有木有....)
So,我们找一个大家都耳熟能详的豆瓣影评,其在业内还是较有权威的,嗯,,
For example:
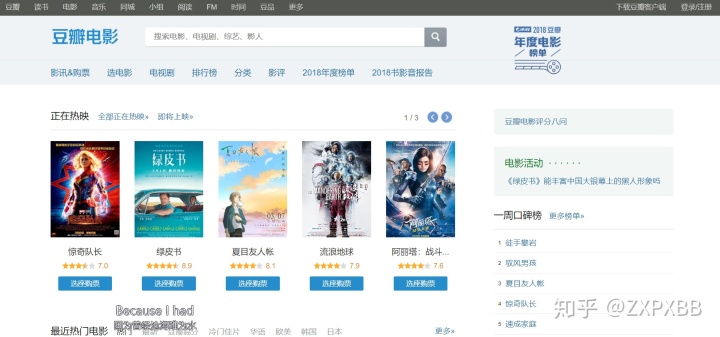
大家应该看到了右下角的 "一周口碑榜 " 没错这个小排名我喜欢,就是说我们想要找的,管你网页其他地方做得再华丽,宣传的多么天花乱坠还是没有咱这个口碑榜实在啊!!!
So,我们的活来了,盘它,哦不,是爬它。
玩笑归玩笑,言归正传,可能有的同志会说为什么你要爬虫直接看不就好了?!我会微微一笑:“这么没技术含量的操作,请问有意思么?”(虽说我承认我这篇随笔的技术水平也不高,
可以毫不忌讳地说,很低,But!我相信自己的水平和技术含量会越爱越高的,毕竟我绝不甘心与此。再者说就是他这个更新一周一周的,自己每次上网也去查我是觉得挺麻烦的,不如
做个爬虫直接代码运行,麻烦一次方便以后,好吧如果你说我强词夺理那就是吧,随便喽。)
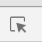
打开网页后,F12,点击这个按钮,然后定位到下图这个框找到它属于<table>标签下的<tbody>标签;这位后面我们的爬取打下了铺垫。(当然这是方法之一)

方法之二:
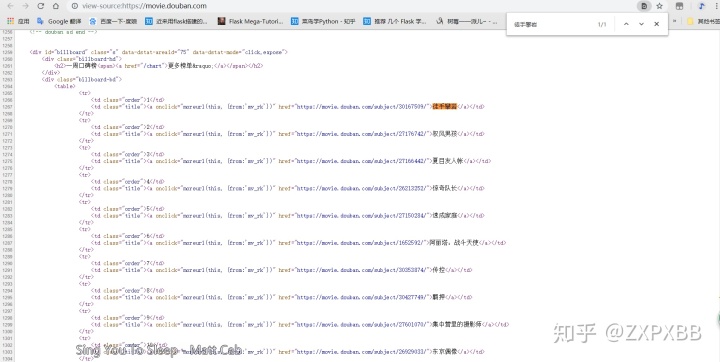
直接快捷键Ctrl+U或者右键 “ 查看网页源代码 ” ,然后Ctrl+F查找 “ 徒手攀岩 ” ;
这下我们就知道了我们所要爬取网页的基本框架是什么样的了,从而进行后续的操作。
import requests
from bs4 import BeautifulSoup
import bs4
def getHtmlText(url):
try:
r = requests.get(url,timeout = 30)
print("raise_stsus = {}".format(r.raise_for_status()))
print("获取状态完毕")
r.encoding = r.apparent_encoding
return r.text
except:
print("get information with error!")
def movieSoupList(movielist,demo):
try:
soup = BeautifulSoup(demo,"html.parser")
tables = soup.find_all("table")
#print("tables is {}nn".format(tables))
tab = tables[1]
#if isinstance(tab,bs4.element.Tag):
# print("yaoxi!!!!!!!!")
#print("tab is {}nn".format(tab)) #tags = tab.find("tr")
#print(type(tags)) #print("tags = {}n".format(tags))
tags = tab.contents #print("tages {} ".format(tab.contents))
# ***** .contents 方法 *****
#print(type(tab.contents)) #//<class'list'> #i = 0
for tr in tags:
#i = i+1 #print("i = {}n".format(i))
#print("transfor finished")
if isinstance(tr,bs4.element.Tag):
tds = tr("td")
# ***** tr("td")这步也很关键 *****
#print("tds {}".format(tds))#print("list is ok")
movielist.append([tds[0].string,tds[1].string])
#print("transfor finished")
#print("movielist is {}".format(movielist))
except:
print("transfor error")
def printMovieList(movielist,num):
model = "{0:^10}t{1:^20}"
print(model.format("排名","影片名",chr(12288)))
try:
for i in range(num):
m = movielist[i]
print(model.format(m[0],m[1],chr(12288)))
except:
print("printMovieList errorn")
def main():
num = 10
url = 'https://movie.douban.com/'
movielist = []
demo = getHtmlText(url)
movieSoupList(movielist,demo)
#print("movielist is n{}nn".format(movielist))
printMovieList(movielist,num)
if __name == '__main__':
main()我在代码里的注释也很清楚了,如果还不懂可以评论或私信我,里面有我当时调试的测试代码
删除了一部分,剩下的大部分都注释掉了。如果有的童鞋们想试试可以像我这样测试,然后一步
步接近自己想要的样子,直至完成项目。
运行结果就是这样:
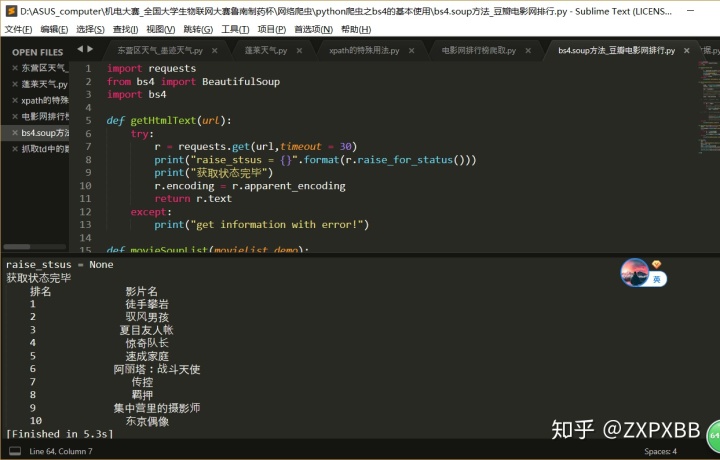
总结:
这个方法的可编辑性较高容易理解很简单,但相对应的短板就是代码冗长编写麻烦费时如果出错不好修改,
总之中规中矩,下一篇文章我将带您欣赏一下Python的Xpath方法的魅力所在。
如果觉得我的文章还不错,关注一下,顶一下 ,我将会用心去创作更好的文章,敬请期待。















 893
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









