





28 计算机网络
第一个计算机网络出现在1950-1960年代,通常在公司或研究室内部使用,方便信息交换,称为球鞋网络(Sneakernet),第二个好处在于共享物理资源,比如多台计算机可以共享一台打印机,并且早期网络也会共享存储空间,因为为每台计算机都配存储器太过昂贵。
计算机近距离构成的小型网络称为局域网(Local Area Network,LAN),局域网能小到是同一间房间内的两台计算机,或者大到校园内的上千台电脑。
其中最著名和成功的局域网技术是1970年代的以太网(Ethernet),以太网最简单的形式是一条以太网电线连接数台计算机,当一台计算机要传数据给另一台计算机时,它以电信号形式,将数据传入电缆中,由于电缆是共享的,所以连接在同一个网络里的其他计算机都能看到数据,但是所有计算机都不知道这些数据是给自己的还是给别人的。为了解决这个问题,以太网需要每台计算机有唯一的媒体访问控制地址(Media Access Control Address,MAC Address),然后将MAC地址作为数据的前缀发送到网络中,所以计算机只需要监听以太网电缆,只要看到自己的MAC地址,才去接收处理数据。现在制造的每台计算机都自带唯一的MAC地址,用于以太网和无线网络。
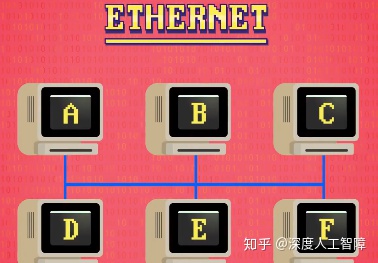
这种多台电脑共享一个传输媒介(比如上面例子中共享的以太网电线)的方法称为载波侦听多路访问(Carrier Sense Multiple Access,CSMA),这里的Carrier指的是传输数据用的任意共享传输媒介,比如以太网的载体就是铜线,WiFi的载体就是传播无线电波的空气。许多计算机可以同时侦听相同的载体,因此使用Sense和Multiple Access。而载体传输数据的速度称为带宽(Bandwidth)。
但是共享载体有个很大的弊端:当网络流量比较小时,计算机可以等待载体清空,然后再传输他们的数据。但随着网络流量上升,两台计算机想同时写入数据的概率也会上升,这称为冲突(Collision),就会使得传输的数据混乱。幸好计算机能够监听电线里的信号来检测冲突,最简单的解决方案就是看到冲突就停止传输,等待网络空闲后再试一次,问题是其他计算机也是这样打算的,其他等待的计算机可能在任何停顿间隙就闯入开始传输数据,这就导致了越来越多的冲突。
以太网的解决方法是:当计算机检测到冲突后,就会在重传之前等待一小段时间,并且要保证所有计算机等待时间都不相同,所以就会让计算机等待1秒叫上一个随机时间,来相互避开。
当然这个并不能完全解决问题,还需要用到另一个技巧。如果一台计算机在传输数据期间检测到冲突,就等待1秒加上一个随机时间,但是如果再次发生冲突,就表明有网络拥塞,就让计算机等待2秒加上一个随机时间,以此类推,直到成功传输。因为计算机的退避,冲突次数会大幅减少,使得数据能够再次流动起来,网络就变得顺畅了。这种指数级增加等待时间的方法称为指数退避(Exponential Backoff),很多以太网和WiFi都用到这个技术。
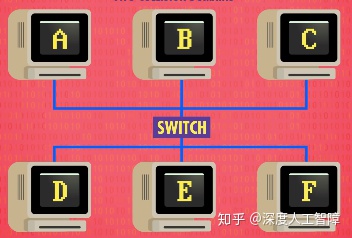
但是即使有了以上的技术,想用一根网线连接整个大学的计算机还是不可能的,为了减少冲突同时提高效率,我们需要减少同一载体中设备的数量,载体和其中的设备总称为冲突域(Collision Domain)。以之前以太网为例,一根电缆连接了6台计算机,这个称为一个冲突域。为了减少冲突,我们可以用交换机(Switch)将它拆成两个冲突域。交换机位于两个更小的网络之间,在必要时才在两个网络之间传输数据,并且交换机会记录一个列表,写着哪个MAC地址位于哪边网络,所以当MAC A想要传数据给MAC C,交换机就不会将数据传到另一边的网络,同理如果MAC E传输数据给MAC F,交换机也不会将数据传到上面的网络,这使得两边的传输能同时进行。但是如果MAC F想传数据给A,数据就会通过交换机,使得两个网络都会被短暂占用。
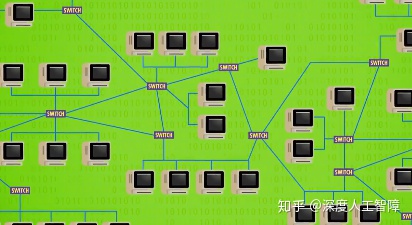
即使最大型的网络——互联网(Internet)也是这样构建起来的,本质还是多个连在一起的稍小一点的网络,使得不同网络间可以传递数据。而大型网络有一个特点,从一台主机到另一台主机通常有多条线路(解决的主要问题),这就引出了另一个话题——路由(Routing)(用来选择合适路线的方法)。
连接两台相隔遥远的计算机或网络,最简单的方法是分配一条专门的通信线路,早期的电话系统就是这样运作的,这种方法称为电路交换(Circuit Switching),因为是对整个电路进行修改,来连接到正确目的地,所以这种方法不灵活且价格昂贵,并且总有闲置的路线。但是好处是你可以最大限度随意使用,无需共享。因此军队、银行和其他一些机构依然会购买专门线路来连接数据中心。
传输数据的另一种方法是报文交换(Message Switching),就像邮政系统一样。不像之前A和B之间有一条专有线路,这里消息会经过好几个站点,就类似于邮寄信封,信封会通过一个个中转站最终到达收件人手中,每个站点都知道下一站要发往哪里,因为站点都有自己一个表格,用来记录到达各个目的地,信件要如何传递。报文交换的好处是,你可以用不同的路由,使得通信更可靠。比如如果其中一个城市由于降雪无法接收邮件时,就能换到另一个城市继续传递数据。这里,城市就相当于网络中的路由器一样。
交换机是连接若干个主机的机器,用来解决冲突域问题。路由器是连接主机、路由器或交换机的机器,用来构建数据传输的线路。
信息沿着路由跳转的次数称为跳数(Hop Count),通过记录跳数,可以分辨出路由问题。比如当路由A认为到达目的地最快的下一个路由是B,就将信息传递给路由B,而路由B则认为到达目的地最快的下一个路由是A,又将信息传递回给了路由A,这就使得信息在路由A和B之间踢皮球,但是这种错误可以通过在信息中实时记录的跳数来解决,如果某条信息的跳数很大,就说明路由有出问题,这个称为跳数限制(Hop Limit)。
而报文交换的缺点之一就是当报文较大时,会堵塞网络,因为这里要求将整个报文从一个路由传到下一个路由后,才能继续传递其他报文,当传输大报文时,其他报文要么等待它传递完,要么选择另一条效率较低的路线。解决方法就是将大报文分成很多小块,称为数据包(Packet)。和报文交换一样,每个数据包都有网络中的目的地址,因此路由器知道要发送到哪里,这个地址的具体格式由互联网协议(Internet Protocol,IP)定义。每个联网的计算机都需要一个IP地址(IP Address),例如172.217.7.238。
MAC地址用来标识每条计算机,而IP地址是对数据包而言的。
路由器会平衡与其他路由器之间的负载,来确保传输可以快速可靠,称为拥塞控制 (Congestion Control)。有时候一个报文的多个数据包会经过不同线路,使得到达顺序也可能不相同,这对一些软件来说是存在问题的。幸运的是,在IP之上还有其他协议,比如TCP/IP可以解决乱序问题。
将数据拆分成多个小数据包,然后通过灵活的路由传递,非常高效且容错率高,这种方法称为分组交换(Packet Switching)。它的好处是可以去中心化,就没有单点失败问题。
如今全球的路由器协同工作,找出最高效的线路,用各种标准协议传输数据,比如因特网控制信息协议(Internet Control Message Protocol,ICMP)和边界网关协议(Border Gateway Protocol,BGP)。
29 互联网
任意计算机都和一个巨大的分布式网络连接在一起,称为互联网(Internet)。
当你在家中通过计算机观看网上视频时,你的计算机首先需要连接到局域网LAN,这个局域网是由家里WiFi路由器连接的所有设备组成的。然后家里的局域网再通过路由器连接到广域网(Wide Area Network,WAN),广域网的路由器一般属于你的互联网服务提供商(Internet Service Provider,ISP)。在广域网里,首先会有一个区域性路由器,比如覆盖你所在街区的一个路由器,然后该路由器会连接到一个更大的广域网中,比如覆盖你所在的城市,可能再跳跃几次,最终会到达互联网主干,一般由一群超大型、带宽超高的路由器组成。
即首先会连接到你家里的WiFi路由器构建的局域网,然后该路由器再连接到ISP提供的广域网中,该广域网是由很多层层递进的路由器构成的。
比如要从YouTube中获得视频,数据包首先会到达互联网主干,沿着主干到达对应保存该视频文件的YouTube服务器,可能这里会跳4次到达互联网主干,然后跳两次穿过互联网主干,最终再跳4次到达YouTube服务器,所以总共会跳跃10次。
我们可以通过traceroute来看跳跃了几次:
Windows上的Traceroute
1.按开始按钮
2.输入“ CMD”,然后按“ Enter”
3.在命令提示符下,键入“ tracert dftba.com”
在Mac上的Traceroute
1.点击“转到”下拉菜单
2.点击“实用程序”
3.打开终端
4.键入“ traceroute dftba.com”
Linux上的Traceroute
1.通过键入CTRL + Alt + T打开终端
2.输入:“ traceroute dftba.com”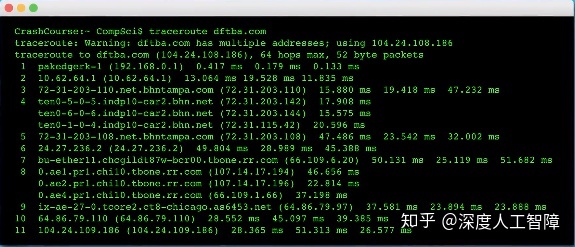
但是数据包到底是怎么传递过去的呢?如果传输时数据包丢失了,会发生什么?当我们在浏览器中输入网址时,浏览器怎么知道服务器的地址是什么呢?
就像上节介绍的,互联网是一个巨大分布式网络,如果要发送的数据较大,分组传输就会将数据拆成一个个较小的数据包进行传输。其中数据包要想在互联网上进行传输,就要符合互联网协议(Internet Protocol,IP)。类似于邮寄手写信一般,每封信都需要一个地址,并且地址必须是唯一的,并且信的大小和重量也是有限制的,否则信件就无法送达。IP数据包也是如此,因为IP是一个非常底层的协议,数据包的头部只包含目标地址(IP地址),意味着当数据包到达对方电脑时,计算机不知道要把数据包交给哪个程序(比如QQ或微信),因此需要在IP之上,开发更高级的协议。
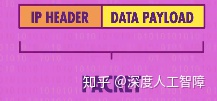
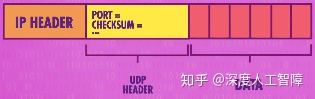
最简单常见的协议称为用户数据报协议(User Datagram Protocol,UDP)。UDP也有头部,位于data payload里面,在data之前。UDP头部里面包含了很多有用的信息,其中之一就是端口号(Port Number),每个想访问网络的程序都要向操作系统申请一个端口号。所以当数据包到达时,接收方的操作系统会读取UDP头部里的端口号,来确定该数据包是要交给哪个软件的。
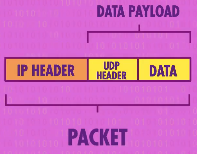
IP协议通过IP地址把数据包送到正确的计算机内;UDP通过数据包里的端口号送到正确的程序。
同时UDP的头部中还有校验和(Checksum),通过对数据求和来检查数据是否正确。假设UDP数据包里原始数据是89 111 33 32 58 41, 最简单的计算校验和的方式就是,在发送数据包之前,计算机会把所有数据加在一起,计算出校验和364。在UDP中,校验和是以16位形式存储的,如果计算出来的和超过16位能表示的最大值,则高位数会被丢弃,只保留低位。当接收方计算机接收到这个数据包时,也会重复以上过程,如果计算出来的校验和和UDP中保存的校验和相同,代表数据是正常的,否则数据是出错的。

但是,UDP不提供数据修复或数据重发机制,当接收方知道数据损坏后,一般只是丢弃这个数据包。并且当发送方使用UDP协议发送数据包时,是无法得知数据包是否到达目的地的。
有些程序并不在意以上问题,因为UDP十分简单且快速。比如视频通常使用UDP协议,当数据包丢失时,也就造成视频卡顿。
但是有些数据不能接受数据包丢失的问题,比如发送电子邮件时,所有数据必须到达,所以就需要传输控制协议(Transmission Control Protocol,TCP)。和UDP一样,它的头部也保存在数据之前,人们通常将IP协议和TCP协议统称为TCP/IP协议。TCP的头部中也包含端口号和校验和,并且TCP协议还提供更高级的功能:
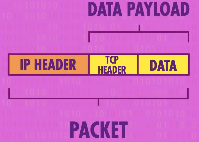
- TCP的数据包是有序号的,使得接收方可以通过这个序号将数据包排成正确顺序,即使到达时间不同。
- TCP要求接收方的电脑收到数据包并校验和检查无误后,需要给发送方发送一个确认码(Acknowledgement,ACK),代表数据包已经正确接收。当发送方接收到确认码后,就知道上一个数据包成功抵达了,发送方就会发送下一个数据包,如果这次发送方过了一段时间没有接收到确认码,则会重新发送一次。即使这里只是由于确认码延迟了,使得接收方那里有重复的数据包,但是通过序列号,可以直接删除重复的数据包。
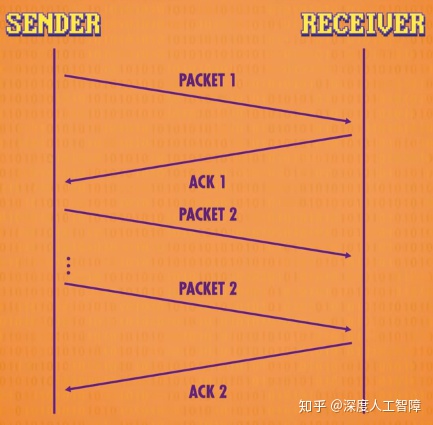
并且数据包并不会一个个数据包进行传输,而是同时发送多个数据包,同时接收多个确认码,这将大大提高效率,不用浪费时间等待确认码。并且通过确认码的成功率和来回时间,我们可以推测网络的拥塞程度,TCP通过这个信息,来调整同时发包数量来解决拥塞问题。
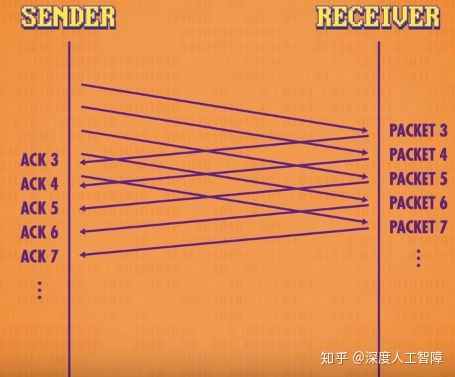
简而言之,TCP可以处理乱序和丢包问题,并且可以根据拥塞情况自动调整传输率。但是由于确认码数据包的存在,使得TCP需要传输的数据包数量翻了一倍,并且并没有传输更多信息,这对时间要求很高的程序代价太高,所以这类程序就会使用UDP协议。
当计算机访问一个网站时,需要两个东西:IP地址(目标网站的地址)和端口号(对应于你使用的计算机浏览器)。但是通过IP地址访问网站十分不方便,所以互联网提供一个特殊服务,来将域名(Domain Name)和IP地址一一对应,称为域名系统(Dimain Name System,DNS),一般DNS服务器都是由ISP提供的。当你在浏览器中输入网站域名时,浏览器就会去访问DNS服务器,DNS就会去查表,如果域名存在,则会返回浏览器对应IP地址,然后浏览器就会给这个IP地址发送TCP请求。
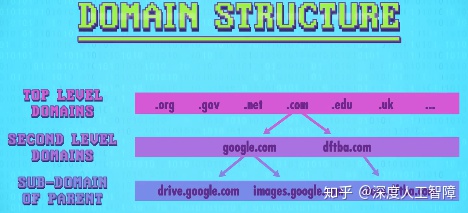
因为当前域名特别多,所以DNS不会将其保存成列表形式,而是将其保存成树状结构。最顶层是顶级域名(Top Level Domain,TLD),比如.com和.gov;下一层是二级域名(Second Level Domain), 比如google.com和dftba.com;再下一层是子域名(Sub-domain),比如images.google.com等等。由于这个树结构特别大,因此这些数据分布在很多DNS服务器上,不同服务器负责树的不同部分。
总结上两节的内容,其实计算机网络分成很多层次,接下来从最底层到最高层:
- 物理层(Physical Layer),比如线路中的电信号,以及无线网络中的无线信号。
- 数据链路层(Data Link Layer)负责操控物理层,其中包含MAC地址、冲突检测、指数回退以及其他一些底层协议。
- 网络层(Network Layer)负责各种报文交换和路由技术。
- 传输层(Transport Layer)负责在计算机之间进行点到点的传输,还会检测和修复错误,比如UDP和TCP协议。
- 会话层(Session Layer)会使用TCP和UDP来创建连接,传递信息,然后关掉连接。
以上是开放式系统互联通信参考模型(Open System Interconnection model,OSI)下的5层,这个框架将网络通信划分成了很多层,每一层处理各自的问题。这种抽象可以使得分工改进多个层,而无需考虑整体复杂性。并且OSI还有额外两层:表示层(Presentation Layer)和应用层(Application Layer),在下一节中进行介绍。
30 万维网
前两节介绍的东西共同组成了互联网,这一节将向上抽象一层,来讨论万维网(World Wide Web)。万维网和互联网的概念完全不同,万维网是运行于互联网之上的,还有其他比如Skype、Instagram等也是运行在互联网之上的。互联网是用来传输数据的管道,各种程序都会使用到,其中传输最多数据的程序就是万维网,我们可以使用特殊的程序——浏览器(Web Browser)来访问万维网。
万维网的最基本单位是单个页面,里面包含内容,也有访问其他页面的链接,这些链接称为超链接(Hyperlink)。这些超链接形成巨大的互联网络,这也是万维网名字的由来。
并且由于文字超链接的强大,它有一个特殊的名字——超文本(Hypertext)。如今超文本最常指向的是另一个页面,这些页面会被获取并由浏览器进行渲染。
为了使网页能够互相连接,每个网页需要一个唯一的地址,这个地址称为统一资源定位器(Uniform Resource Locator,URL),比如thecrashcourse.com/courses就是一个页面URL。
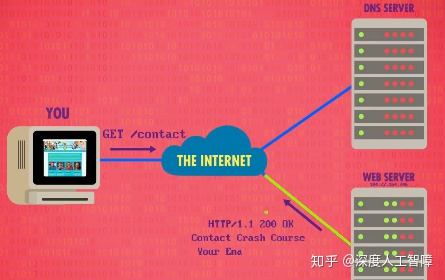
当你访问thecrashcourse.com网址时,计算机首先会进行DNS查询,这里输入一个域名,然后DNS就会返回给浏览器对应的计算机IP地址。然后浏览器就会打开一个TCP连接到这个IP地址对应的计算机上,而这个计算机运行着一个特殊的软件——网络服务器(Web Server),网络服务器的标准端口是80。此时,你的计算机就连接到了thecrashcourse.com对应的服务器了,下一步是向服务器请求courses 页面,这里就会用到超文本传输协议(Hypertext Transfer Protocol,HTTP)。
HTTP的第一个标准是1991年创建的HTTP 0.9,只有一个指令GET 。因为这里我们想要获取courses页面, 我们可以直接向服务器发送指令GET/courses, 该指令以ASCII编码发送到服务器,服务器会返回该网址对应的页面,然后浏览器就会将其渲染到屏幕上。如果用户点击了另一个链接,计算机就会重新发送一个GET请求。
在之后的版本中,HTTP添加了新的状态码,会将其放在请求页面的前面,比如状态码200表示网页被正确找到了,状态码400-499代表客户端出错。
因为超文本的存储和发送都是以普通文本形式进行的,编码可能是ASCII或者UTF-8,这样就无法表明什么是链接,什么只是普通的文本了,所以必须开发一种标记方法,因此出现了超文本标记语言(Hypertext Markup Language,HTML),第一代HTML创建于1990年的0.8版本,有18种指令。

综上,网络浏览器可以和网络服务器沟通,不仅获取网页和媒体,并且还负责显示。
随着后期万维网日益繁荣,人们越来越需要搜索。起初人们会维护一个目录,来链接到其他网站,但是随着网络越来越大,人工编辑目录变得很不方便,所以开发了搜索引擎。
最早的搜索引擎是JumpStation,它有3个部分:1. 通过爬虫来将新链接添加进自己的列表中。2. 不断扩张的索引,用来记录访问过的网页上出现了哪些词。3. 查询索引的搜索算法,比如输入了某个关键字,则包含这个关键字的网页就会显示出来。早期的搜索引擎的排名方式直接取决于搜索词在页面上的出现次数,但是有的网页会通过在页面中重复该关键字来提高排名。Google成名的很大原因就是提出了一种算法来解决这个问题,与其信任页面上的内容,搜索引擎会看其他网页有没有连接到这个网页。
最后提一个概念——网络中立性(Network Neutrality),它指的是要对所有数据包都平等对待,速度和优先级都应该一样。















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









