





之前做的python数据分析项目(天气预测),最近整理了一下当时的报告,也算小小复习一下,用的jupyter notebook,附件在文章的最下方~
第一部分:数据分析处理
(1)问题背景与建模:
本次内容所选取的数据集来源于机器学习平台Kaggle网站weather-dataset-rattle-package,主要内容是澳大利亚气象站的每日天气观测数据。旨在通过分析气象数据,预测第二天是否会下雨。该模型的建立可用于气象预测,增强预测的准确度。
1. 数据读入
weather=pd.read_csv("data/weatherAUS.csv")
weather.head() #查看前五行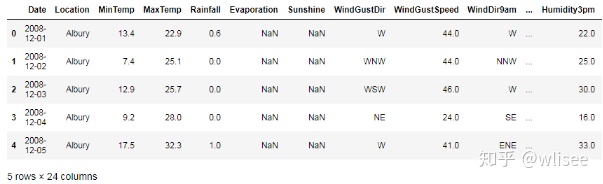
2. 初步观察
weather.info()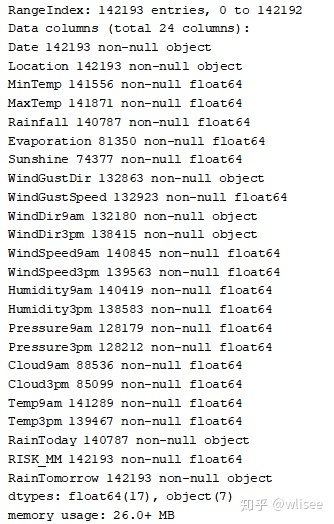
可以看到本数据集共142193行数据,共24个属性,约26MB。主要包括气压、气温、风速、风向、日照时间等气象信息。其中float类型数据17个, object类型数据7个,之后需对其进行处理。
3. 初步分析:
查看最大最小值、均值标准差等
weather.describe()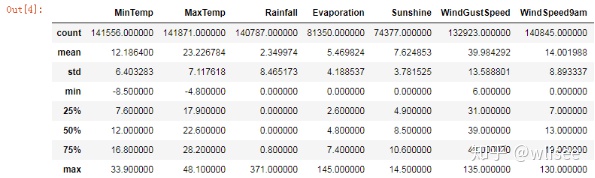
经过初步读入查看、属性描述和简要分析确定问题属于二分类问题,后期需使用分类模型分析。
(2)数据预处理:
为了运用机器学习算法分析,数据集的属性必须是数字格式。不采用此格式的属性应转换或删除。
1. 缺失值处理
主要使用dropna函数过滤缺失值:
weather2=weather.dropna(axis = 0)2. 异常值处理
通过相关知识判定并寻找替换:
temp=weather2['MaxTemp']
temp[temp>48]=48
weather2['MaxTemp']=temp3. 时间属性处理
通过以下语句提取月份等信息并存储为CSV格式文件。
from datetime import datetime
weather2['Date']=pd.to_datetime(weather2['Date'])
weather2['Month'] = pd.DatetimeIndex(weather2['Date']).month(3)可视化分析:
使用Matplotlib、seaborn库绘图,更加直观地查看数据构成和关系、为之后的分析打下基础。以下列举5例:
1. 下雨天数统计
a = weather2['RainTomorrow'].value_counts()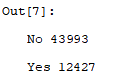
df = pd.DataFrame([45361,12729],index=['No', 'Yes'])
df.plot.bar(title="下雨统计")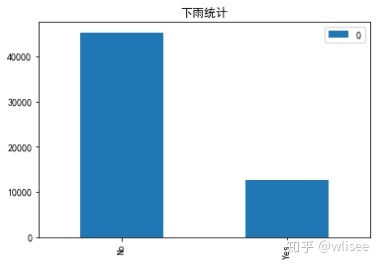
可见下雨与不下雨天数差距较大,因此之后需进行均衡化处理
2. 今明两天下雨关系
rain_0 = weather2.RainTomorrow[weather2.RainToday == 'No'].value_counts()
rain_1 = weather2.RainTomorrow[weather2.RainToday == 'Yes'].value_counts()
df=pd.DataFrame({u'下雨':rain_1, u'未下雨':rain_0})
df.plot(kind='bar', stacked=True)
plt.title(u"今明两天下雨关系")
plt.xlabel(u"今日")
plt.ylabel(u"明日")
plt.show()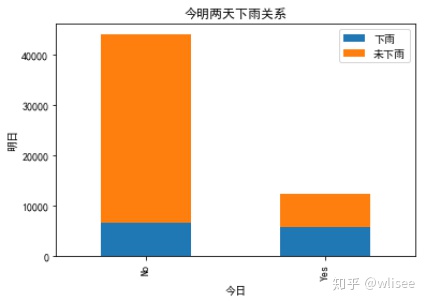
3. 月份对于降雨量的影响
sns.barplot(weather2['Month'],weather2['Rainfall'])
plt.title("The influence of month")
plt.show()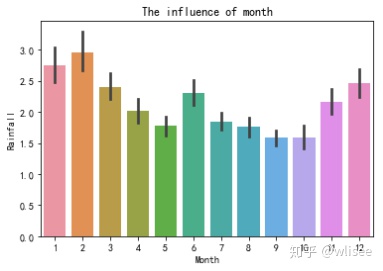
4. 查看下午三点气压与湿度分布及相关关系(蜂窝图)
with sns.axes_style("white"):
sns.jointplot(x=weather2['Pressure3pm'], y=weather2['Humidity3pm'], kind="hex", color="k")
plt.show()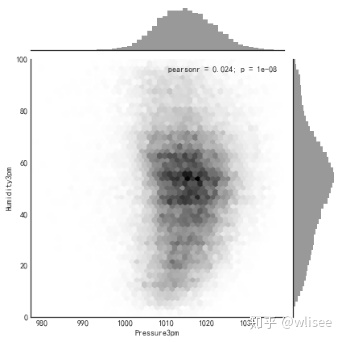
5. 属性间的相关关系:
sns.heatmap(weather2.corr())
(4)特征工程:
主要包括字符型数据和分类属性处理、特征合并和删除、特征选择、数据均衡化与标准化。
1. 字符型数据处理
编码方式采用one hot编码,避免顺序编码数字大小对于预测结果造成影响:
dum1=pd.get_dummies(weather2['WindGustDir'],prefix='WindGustDir')2.分类型特征进行离散/因子化
从Python序列直接创建pandas.Categorical
today=weather2['RainToday']
my_categories = pd.Categorical(today)
weather2['RainToday']=my_categories.codes3. 使用join和drop进行特征的合并和删除
weather2=weather2.join(dum2)
weather3=weather2.drop(["Date","Location","RISK_MM",'WindGustDir','WindDir9am','WindDir3pm'], axis=1)4. 特征选择方面:
主要有过滤法(卡方检验但由于数据存在负数不可用、方差选择)、包装法、内嵌法等方法。因此本报告选择内嵌法,并根据各因素影响程度和Xgboost图像显示,综合以上内容选择了20各主要特征,生成新的数据集。
查看属性相关关系
correlation = weather3.corr()
influence_order=correlation['RainTomorrow'].sort_values(ascending=
False)
influence_order_abs ==abs(correlation['RainTomorrow']).sort_values
(ascending=False)
print(influence_order)
print(influence_order_abs)
内嵌法的使用:
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
#GBDT作为基模型的特征选择
selector = SelectFromModel(GradientBoostingClassifier()).fit(feature,label)
data = selector.transform(feature)
a1=selector.estimator_.feature_importances_
df=pd.DataFrame({'b':b,'a1':a1})
df=df[df.a1>0.01]
df.sort_values(by='a1' ,ascending = False) #排序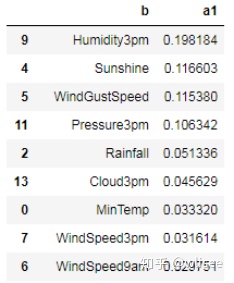
Xgboost画图
from sklearn.ensemble import GradientBoostingClassifier
import xgboost
from xgboost import XGBClassifier
xgb = XGBClassifier(n_estimators=20)
xgb.fit(feature,label)
xgboost.plot_importance(xgb)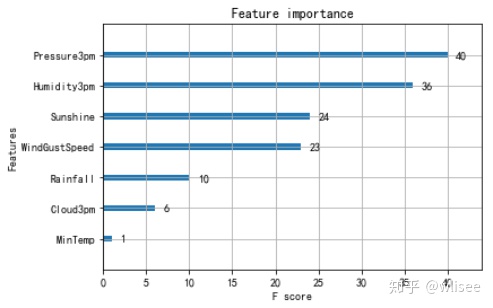
综合以上特征选择的方法,选取了20个重要特征。
#feature=['Humidity3pm','Sunshine','Cloud3pm','Cloud9am','RainToday','Humidity9am','Pressure9am','Rainfall','Pressure3pm','WindGustSpeed', 'Temp3pm','MaxTemp','Evaporation','MinTemp','WindSpeed3pm','WindSpeed9am','WindDir9am_N','WindDir9am_E','WindDir3pm_WNW','Temp9am','RainTomorrow']5. 数据均衡化处理:
由于之前可视化发现下雨天数和不下雨天数相差较大,直接计算会导致效果很差。 为了使结果更为准确,对两类样本数量进行均衡化。解决方法主要有如下两种:1.下采样(undersample):随机选择和异常样本一样多的正常数据和异常数据一同进行训练进行。2.过采样(oversample):利用生成算法,生成和正常样本一样多的异常样本。本方案采取下采样方法,随机选取与下雨天数相同数量的不下雨记录并整合索引,生成最终数据集under_sample_df。
number_yes = len(weather4[weather4['RainTomorrow'] == 1]);number_yes12427
random_no_indices = np.random.choice(no_indices, number_yes, replace=False)
#随机选取相同数量的下雨和不下雨(和下雨相同)记录
under_sample_indices = np.concatenate([yes_indices, random_no_indices])
under_sample_df = weather4.iloc[under_sample_indices, :]
# 整合两类样本及索引6. 标准化:
由于不属于同一量纲(即特征的规格不一样)不能够放在一起比较,因此运用无量纲化可以解决这一问题。主要方法有Stanardscaler基于高斯分布,MinMaxScaler基于最大最小值缩放(受极端值影响大),Normalization基于文本处理。本数据集数据大多属于高斯分布,因此选择Stanardscaler标准化方法。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_undersample)
X_undersample2=scaler.transform(X_undersample)7.降维处理:
PCA是一种无监督的学习方式,是一种很常用的降维方法。在数据信息损失最小的情况下,将数据的特征数量由n,通过映射到另一个空间的方式,变为k(k<n)。
from sklearn.decomposition import PCA
pca = PCA(n_components=15)
X_undersample3= pca.fit(X_undersample).transform(X_undersample)(5)存储:
将逐步处理的生成的新数据集和矩阵分别保存为CSV合适和NPZ格式。
1. 将特征和标签分别存储
feature=X_undersample2
label=y_undersample
np.savez('data/weather_rain.npz',feature=feature,label=label)2. 矩阵存储
weather_matrix=under_sample_df.as_matrix();weather_matrix
np.save('data/weather_matrix',weather_matrix)第二部分:机器学习应用
由于本数据集问题属于分类问题,因此需选择分类算法。本报告选择模型共8个:DecisionTree决策树,RandomForest随机森林,GBDT模型,Xgboost模型,KNN K近邻模型,NB朴素贝叶斯模型,Logistic逻辑回归和SVM支持向量机。下面展示以随机森林为例:
(1) 划分数据集:
由于树模型不需要进行数据的标准化,而其他模型需要,因此分别将标准化之前和之后的数据集都进行划分。使用如下语句调用划分:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(feature,label,
test_size=0.3, random_state=0)(2)模型选择:
调用随机森林模型,对数据进行拟合。
from sklearn.ensemble import RandomForestClassifier #调用
model2 = RandomForestClassifier(criterion='gini', max_depth=2, n_estimators=5)
model2.fit(X_train2, y_train)(1)指标评估:
对训练集进行预测,并进行指标评估,指标主要包括准确率(accuracy),精确率(precision),召回率(recall),F1值(F1 measure),Log loss损失,AUC和ROC曲线,并绘制混淆矩阵直观展现模型结果。
y_pred2 = model2.predict(X_test2)准确度:对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。
a = metrics.accuracy_score(y_test, y_pred2)
print("Accuracy : %f" % a)精确率:查准,就是预测出来为正样本的结果中,有多少是正确分类。
p = metrics.precision_score(y_test, y_pred2)
print("Precision : %f" % p)召回率:真实为正样本的结果中,有多少是正确分类。
r = metrics.recall_score(y_test, y_pred2)
print("Recall : %f" % r)F1值:精确率与召回率的调和平均值,它的值更接近于Precision与Recall中较小的值
f = metrics.f1_score(y_test, y_pred2)
print("F1 : %f" % f)Log loss:对数损失通过惩罚错误的分类,实现对分类器的准确度(Accuracy)的量化. 最小化对数损失基本等价于最大化分类器的准确度。
l = metrics.log_loss(y_test, y_pred2)
print("Log loss : %f" % l)Accuracy : 0.748290
Precision : 0.724855
Recall : 0.802248
F1 : 0.761590
Log loss : 8.693871
混淆矩阵:
TP(True Positive): 真实为0,预测也为0
FN(False Negative): 真实为0,预测为1
FP(False Positive): 真实为1,预测为0
TN(True Negative): 真实为0,预测也为0
confMatrix = confusion_matrix(y_test, y_pred1)
seaborn.heatmap(confMatrix, annot=True, fmt="d")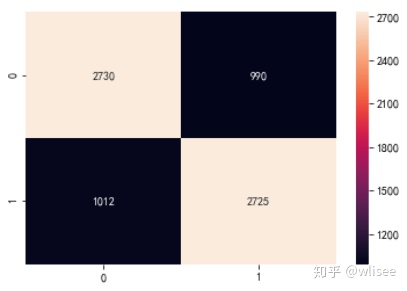
AUC(Area Under roc Curve)是一种用来度量分类模型好坏的一个标准。首先AUC值是一个概率值,当随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
y_pred_score = model2.predict_proba(X_test2)
fpr21, tpr21, thresholds21 = roc_curve(y_test, y_pred_score[:, 1])
roc_auc21 = auc(fpr21,tpr21)
print("AUC Score : %f"% roc_auc21)AUC Score : 0.822603
ROC曲线:全名叫做Receiver Operating Characteristic,其主要分析工具是一个画在二维平面上的曲线——ROC curve。平面的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR)。对某个分类器而言,我们可以根据其在测试样本上的表现得到一个TPR和FPR点对。这样,此分类器就可以映射成ROC平面上的一个点。调整这个分类器分类时候使用的阈值,我们就可以得到一个经过(0, 0),(1, 1)的曲线,这就是此分类器的ROC曲线。曲线距离左上角越近,证明分类器效果越好。
此图与其他模型对比分析,绘制结果见下文。
(2)模型优化:
针对部分模型的部分参数进行参数选择和模型优化,以达到更高的水平。但由于电脑运行能力限制,只进行初步选择。利用网格超参数搜索GridSearchCV。
针对随机森林进行如下两个参数的选择:
1.max_features: 随机森林允许单个决策树使用特征的最大数量。 Python为最大特征数提供了多个可选项。下面是其中的几个:Auto/None :简单地选取所有特征,每颗树都可以利用他们。这种情况下,每颗树都没有任何的限制。sqrt :此选项是每颗子树可以利用总特征数的平方根个。例如,如果变量(特征)的总数是100,所以每颗子树只能取其中的10个。“log2”是另一种相似类型的选项。
2.n_estimators: 在利用最大投票数或平均值来预测之前,想要建立子树的数量。 较多的子树可以让模型有更好的性能,但同时让代码变慢。应该选择尽可能高的值,只要处理器能够承受的住,因为这使预测更好更稳定。
#设置待选的参数
from sklearn.ensemble import RandomForestClassifier
from sklearn.grid_search import GridSearchCV
RandomForest_classifier = RandomForestClassifier()
parameter_grid = {'max_depth':[None,1,2,3,4,5],
'n_estimators':[50,100,120]}
#将不同参数带入
gridsearch = GridSearchCV(RandomForest_classifier,
param_grid = parameter_grid,)
gridsearch.fit(X_train2,y_train)
#得分最高的参数值,并构建最佳的决策树
best_param = gridsearch.best_params_
model2_best= RandomForestClassifier
(max_depth=best_param['max_depth'],n_estimators=best_param['n_estimators'])
model2_best.fit(X_train2, y_train)
由输出的结果可以找到目前阶段最佳的参数,通过检验可发现各个指标结果有所提升。
Accuracy : 0.808770
Precision : 0.804962
Recall : 0.816163
F1 : 0.810524
Log loss : 6.604920
AUC Score: 0.892860
(3)模型保存和预测
1.使用joblib库保存
from sklearn.externals import joblib
joblib.dump(model2_best, "model/w_randomforest_best.m")['model/w_randomforest_best.m']
2.调用保存的模型并预测
clf2_best=joblib.load("model/w_randomforest.m")
predict=[[63,5.9,7,7,0,71,1008.6,0,1006.2,56,27.3,30.7,8,21.8,19,24,1,0,0,24.4]]
if clf2_best.predict(predict)[0]==0: print("不下雨")
else: print("下雨")下雨
至此,完成了一个模型从调用、训练、应用、评价、保存、调优到预测的全过程。按照如上流程,使用8种模型(DecisionTree决策树、RandomForest随机森林、GBDT模型、Xgboost模型、KNN K近邻模型、NB朴素贝叶斯模型、Logistic逻辑回归和SVM支持向量机)分别进行处理。
(4)算法比较:
通过Pandas二维数据结构DataFrame对各个模型各个指标进行排序和比较:
1. 精确度
accuracy=pd.DataFrame({
'Model':['DecisionTree','RandomForest','GBDT','Xgboost','KNN','NB','LogisticRegression','SVM'],
'Accuracy':[a1,a2,a3,a4,a5,a6,a7,a8]})
accuracy.sort_values(by='Accuracy' ,ascending = False) #降序排列
2. 精度

3. 召回率

4. F1值
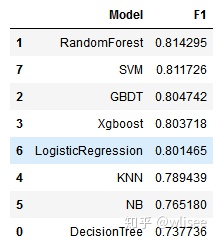
5. Log Loss
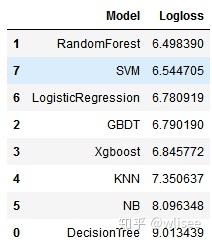
6. AUC
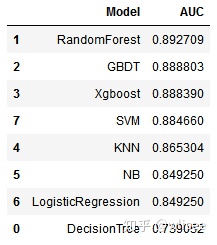
7. ROC曲线

(5)结论
综上所述,经过模型训练、预测和评价,对于本数据集而言支持向量机和随机森林效果最好。下面对两个模型的优缺点进行总结。
1. 随机森林
优点:
(1)在当前的很多数据集上,相对其他算法有着很大的优势,表现良好
(2)它能够处理很高维度(feature很多)的数据,并且不用做特征选择(因为特征子集是随机选择的)
(3)在训练完后,它能够给出哪些feature比较重要
(4)在创建随机森林的时候,对generlization error使用的是无偏估计,模型泛化能力强
(5)训练速度快,容易做成并行化方法(训练时树与树之间是相互独立的)
(6)在训练过程中,能够检测到feature间的互相影响
(7)实现比较简单
(8)对于不平衡的数据集来说,它可以平衡误差。
(9)如果有很大一部分的特征遗失,仍可以维持准确度。
缺点:
(1)随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟
(2)对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。
2.SVM
优点:
(1)非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射;
(2)对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思想是SVM方法的核心;
(3)支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量。
(4)SVM 是一种有坚实理论基础的新颖的小样本学习方法。它基本上不涉及概率测度及大数定律等,因此不同于现有的统计方法。
(5)SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
(6)少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。
缺点:
(1)SVM算法对大规模训练样本难以实施
(2)用SVM解决多分类问题存在困难
(8)模型保存和预测
1.保存
from sklearn.externals import joblib
joblib.dump(model2_best, "model/w_randomforest_best.m")['model/w_randomforest_best.m']
2.调用保存的模型并预测
clf2_best=joblib.load("model/w_randomforest.m")
predict=[[63,5.9,7,7,0,71,1008.6,0,1006.2,56,27.3,30.7,8,21.8,19,24,1,0,0,24.4]]
if randomforest.predict(predict)[0]==0: print("不下雨")
else: print("下雨")下雨
至此,对于本数据集的整个数据分析处理与机器学习模型应用全部完成。找到了相对较优的算法并进行预测。未来还可以对模型进行更深度的优化,以提高预测的准确度和速度。
第三部分:其他尝试
1. 无监督学习:聚类算法Kmeans
from sklearn.cluster import KMeans
clt = KMeans(n_clusters=2, random_state=1)
clt.fit(features)array([0, 1, 1, ..., 0, 0, 0])
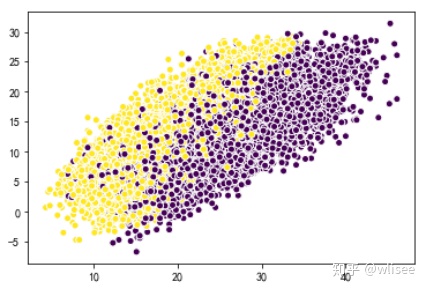
2. 深度学习:神经网络算法
利用tensorflow搭建神经网络架构较为复杂,这里简单使用sklearn库中的神经网络算法进行尝试。sklearn库中nerual_network提供3种神经网络算法函数:
1.BernoulliRBM:伯努力受限玻尔兹曼机神经网络算法
2.MLPClassifier:多层感知器神经网络算法
3.MLPRegressor:多层感知器神经网络回归算法。
这里使用MLPClassifier:多层感知器神经网络算法进行分类尝试并评价。
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier()
mlp.fit(X_train,y_train)评价:
Accuracy : 0.800992
Precision : 0.804049
Recall : 0.797164
F1 : 0.800591
Log loss : 6.873558
与上方八种分类算法比较可见,神经网络算法也是处理本数据集的一种相对较好的模型。
附件:
链接:https://pan.baidu.com/s/1ED0G3tonhj4ZE2_eSoVB8w
提取码:gv6u















 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









