






Java和C#中没有头文件的概念。常见的概念是在头文件中对函数进行声明,但是在后面的学习中会发现,有些概念必须需要头文件。
关于头文件中的函数声明,因为如果产生了对当前cpp文件外的函数的调用,那么必须在当前文件中声明该函数,否则编译的过程中会报错。同时,头文件中不能有函数的定义,否则在链接的时候会发现有重复定义。所以,必须通过头文件,只进行声明,不进行定义。
在头文件中会有#pragma once,这个是预处理,目的是告诉编译器,这个头文件只需要也只能包含一次。因为之前说过,#include的作用就是把文件的内容直接拷贝粘贴,如果不小心粘了两次,那么在编译的时候就能够发现同一个名字重复声明了两次,所以是一定要防止的。
什么情况下会出现在一个cpp文件中重复include两次同一个头文件呢?很简单,如果有一个头文件负责包括多个头文件便于程序员使用,那么就有可能。所以要防患于未然。
在#pragma once之前经常使用的是
#ifndef _XXX_h
#define _XXX_h
#endif效果和#pragma once差不多,但是#pragma once要简洁多了。而且大部分的编译器也支持#pragma once,所以尽管放心使用。
在#include的时候的 <>和""的区别。<>引用的是编译器的类库路径里面的头文件,""程序目录的相对路径中的头文件。但是“”包括的更广点,如果"iostream"使用起来没问题,但是如果是自己的头文件使用<>会报错。所以还是区分着点比较好。
还有一点,C中的头文件都是有.h后缀的,但是iostream就没有,大概是C++标准库的编写者想用来区分C头文件和C++头文件的。
这两段其实逻辑关联不是很强,Cherno自己也很惆怅视频的顺序——就按照视频来好了。
调试首先就是要设断点,设了断点程序在运行到这一行的时候就会暂停,然后程序员可以查看程序当前的内存,从而发现错误所在。内存中的信息反映的就是程序的状态,变量当前的值,下一步执行的代码等等。调试时,程序员还可以跟踪程序执行的每一步。
VS当中,在debug模式下只要点击代码左侧,就可以设置断点了。如果实在release模式下,编译器可能会调整和优化代码,使得断点可能会被忽略。工具栏中有各种按钮,如F11是一句一句跟踪 step into,F10是一个过程一个过程跟踪 step over,基本思路和gdb差不多。不过是图形化界面。
可以通过一个简单的例子来看一下查看内存。这个代码很简单,
#include <iostream>
int main() {
int a = 8;
a++;
const char* string = "hello";
for (int i = 0; i < 5; i++)
{
const char c = string[i];
std::cout << c << std::endl;
}
std::cin.get();
}运行结果:
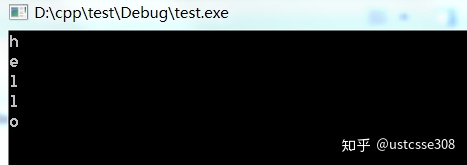
接下来一步一步运行看一下。首先在a=8的地方设一个断点。这样的话,在将要把a赋值为8之前就会停下来。F5开始调试。
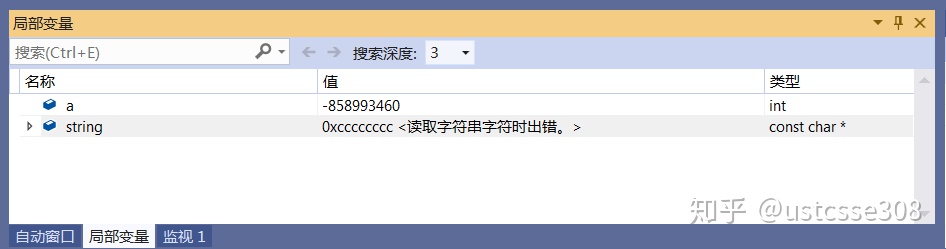
此时因为a还没有赋值,所以是一个随机数。这里也可以在监视1中输入自己想观测的其他变量。还可以通过
查看程序整个的内存。

可以看到有很多的cc,这里主要是debugger提示程序员这里都是没有被初始化的栈空间。
通过逐句执行,我们就可以看到变量的变化。
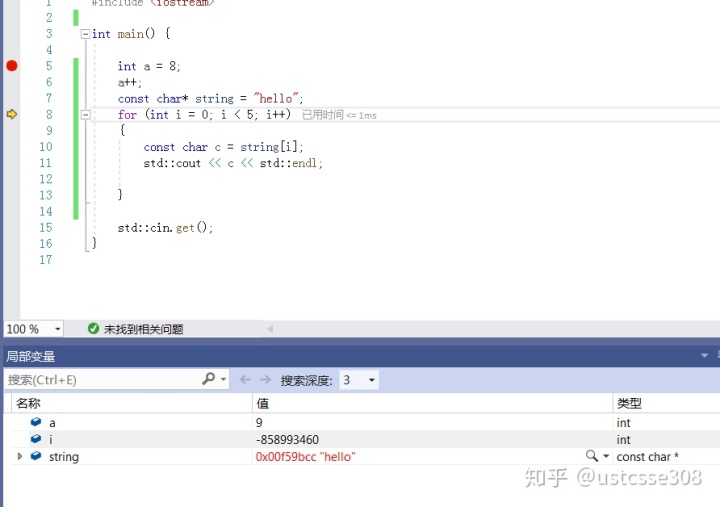
嗯,简单的debug就这么多......















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









