





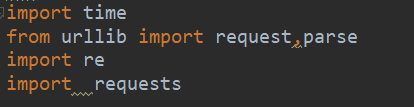
 本文教你如何使用Python爬虫从电影天堂网站获取电影下载链接。通过分析网页结构,利用requests、re等库,实现电影链接的自动抓取,避免手动下载的繁琐。注意不要过度抓取,以免给服务器带来负担。
本文教你如何使用Python爬虫从电影天堂网站获取电影下载链接。通过分析网页结构,利用requests、re等库,实现电影链接的自动抓取,避免手动下载的繁琐。注意不要过度抓取,以免给服务器带来负担。
点击上方“IT共享之家”,进行关注
回复“资料”可获赠Python学习福利
【一、项目背景】
相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态。
今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来。
【二、项目准备】
首先 我们第一步我们要安装一个Pycharm的软件。Pycharm软件安装可以看这篇教程:Python环境搭建—安利Python小白的Python和Pycharm安装详细教程。
电影天堂网的网址:
https://www.ygdy8.net/html/gndy/dyzz/list_23_1.html
我们需要下载几个库,怎么下载呢?首先打开Pycharm点击File再点开setting。
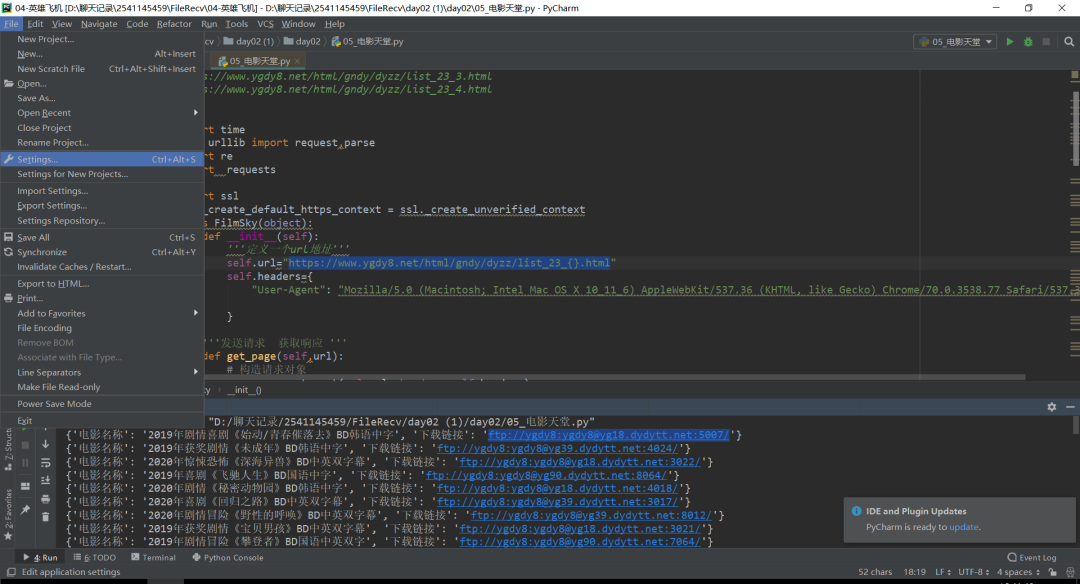
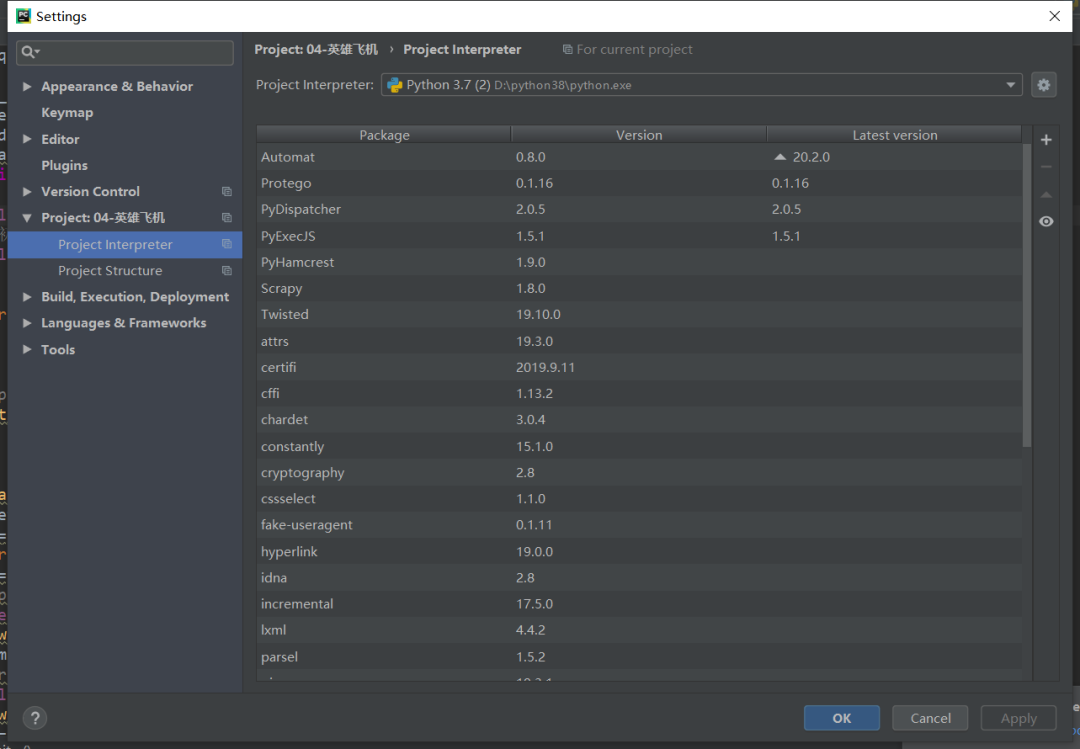
打开后会出现这个界面点击你的项目名字(project:(你的项目名字))project interpreter点击加号下载我们需要的库本项目需要(requests,requests,time,re模块),如下图所示。
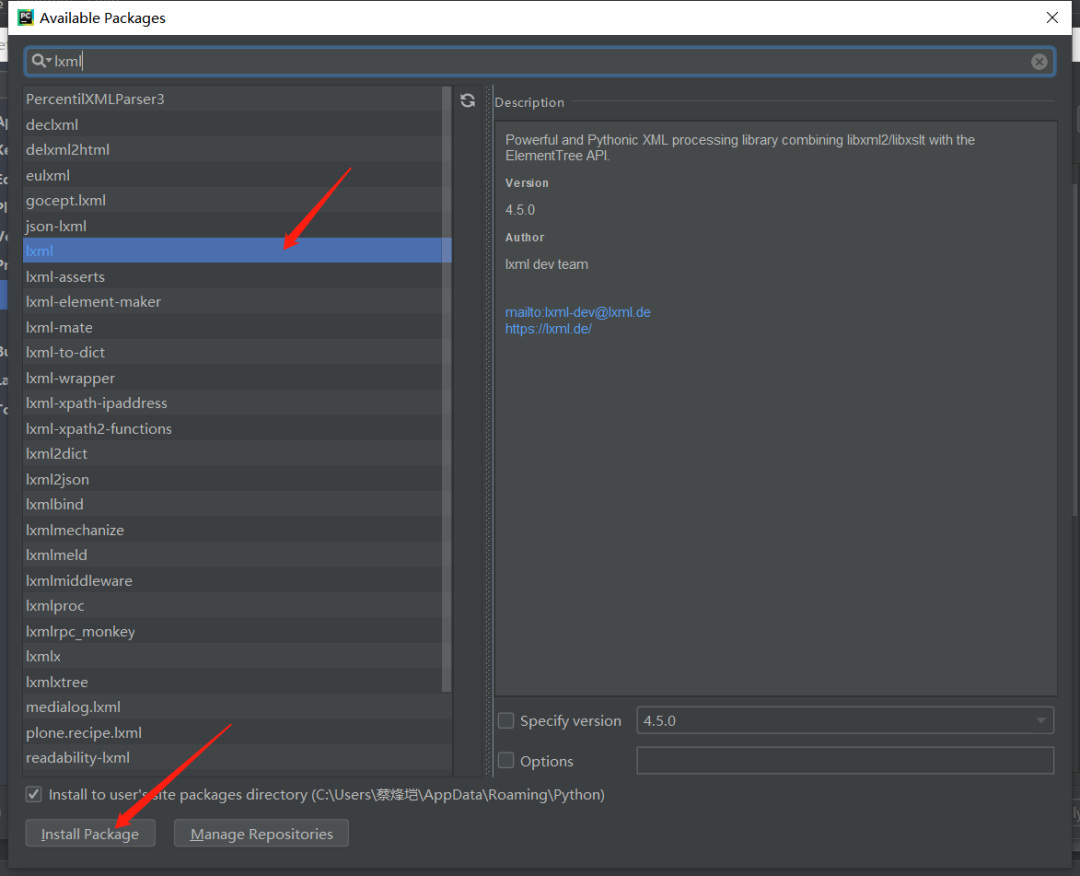
如果还缺少相应库的话,可以按照如下方式进行下载和安装。
【三、项目实施】
我们需要(requests,requests,time,re模块 ),如下图所示。
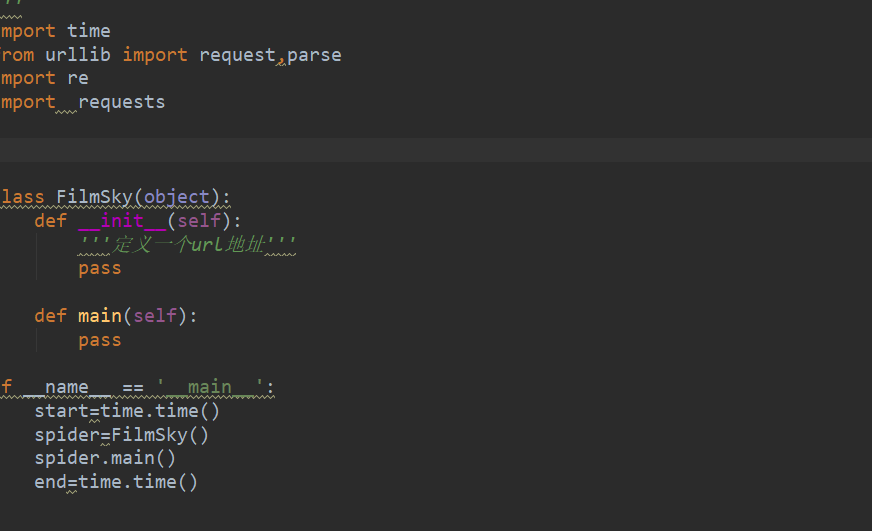
用封装方法去实现各个部分功能。首先要写一个框架 :构造一个类FilmSky 然后定义一个—init方法里继承(self),再定义一个主方法(main)。最后实现这个main方法。代码如下:
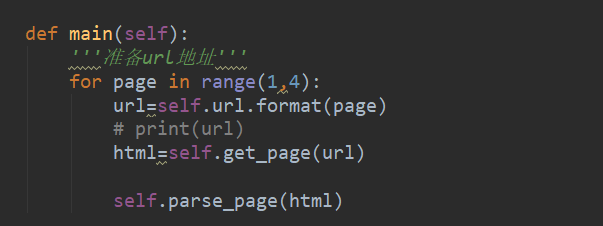
这个time是用于防止反爬,设置的时间延时。
首先我们来分析一下这个网址下一页得到特点。
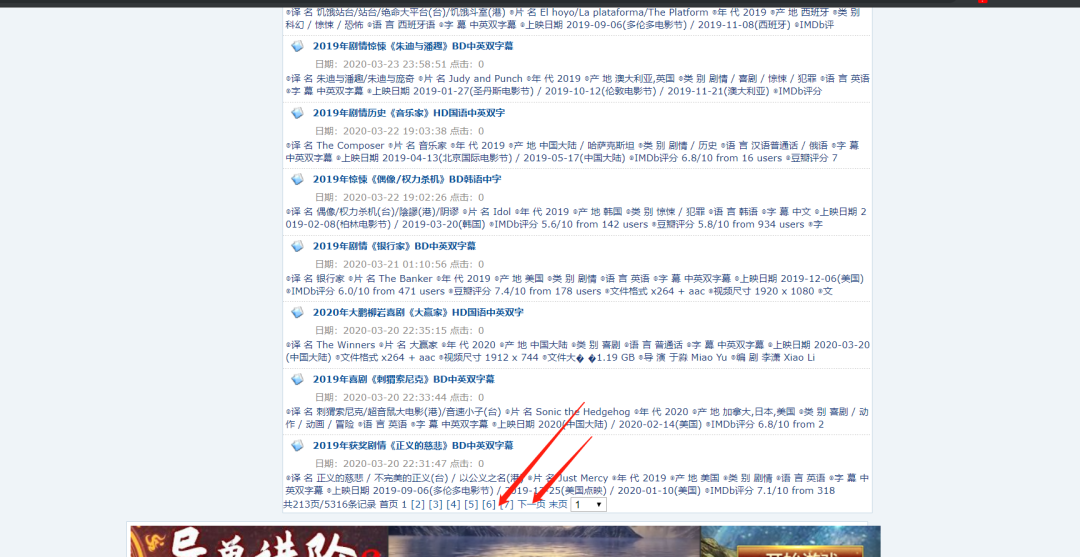
通过点击了三页我们会发现地址都是在原有的基础上“23—3,4,5”这样的变化。
我们可以用{}去代替变化的值就像这样:
https://www.ygdy8.net/html/gndy/dyzz/list_23_{}.html
这样我们在inti方法初始化url地址和构造请求头。

在主方法main函数里边用for循环实现遍历网址。
得到下图这样的结果:
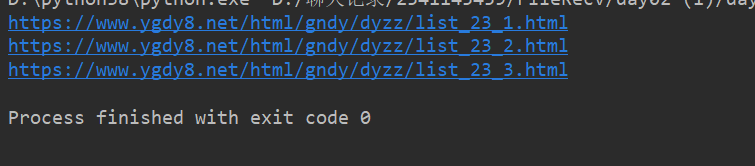
说明你已经成功一半了加油!!
现在我们需要对这些网址发生请求,为了更直观的看出来,我们用一个类写。
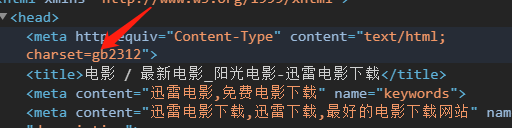
我们用requests发生请求 这个网站的编码是gbk (怎么看网站的编码?)。
打开一个网站右键检查在header的标签,以这个网站为例,可以看到charset=“gb312”。
这个gb2312就是编码 我们常见的编码方式有2种(utf_8, gbk)。
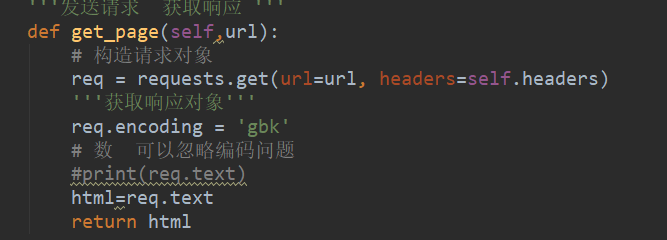
我们可以验证一下是不是真的请求到了。使用Print(html)看到这个结果(一个完整的html网页)说明请求成功。
我们再定义这个方法(对我们的网页代码进行解析)。
我们用正则表达式 来解析数据 我们右键检查可以看到我们要的网站在table里面的
标签的标签的href。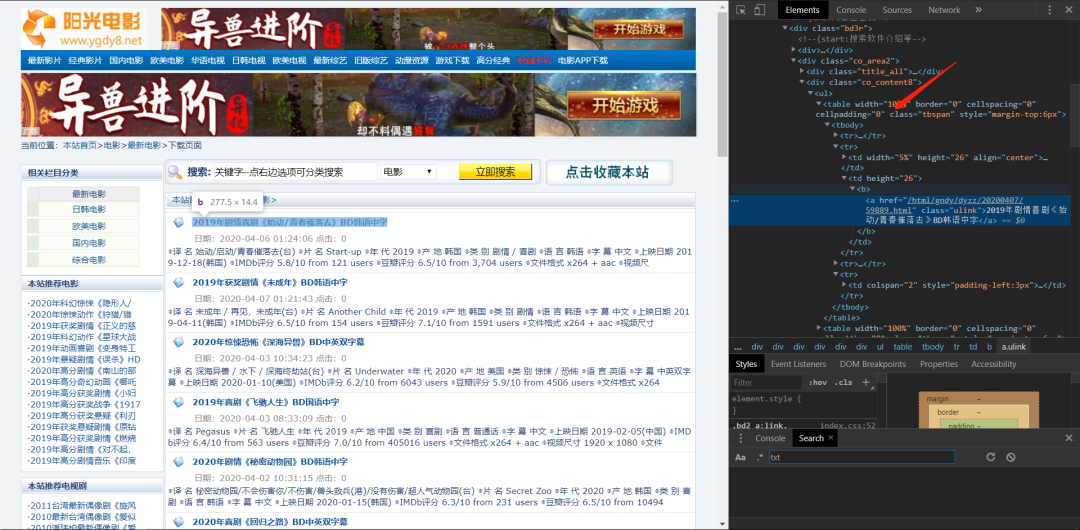
所以我们可以先找到table,一层一层的去找,可以参考一下下面的图。

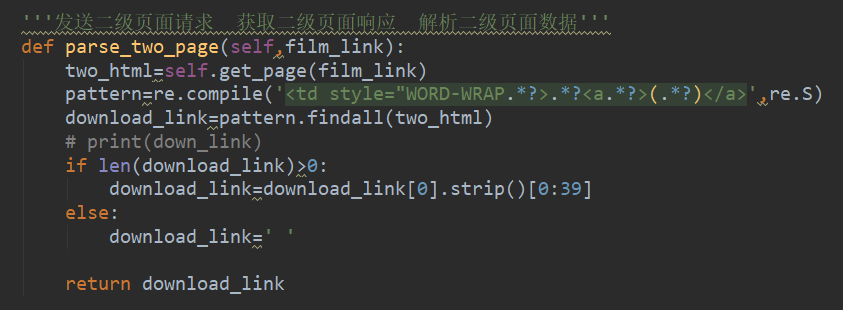
正则表达式就是(.*?)里面就是你想要得到的内容,“.*?”就是可以省略其中的标签,取到你想要地区那一层。for循环遍历得到每个网址,点击这些网址我们要对二级页面发生请求,并解析它。
因为在网页网址上的链接有一些是空的 ,所有这样会导致电影下载的链接不匹配。所以我们要加个判断,如果下载链接的长度大于0那么就照常显示,否则就给它一个空值,这样就不会不对应了。最后返回这个结果,如下图所示。
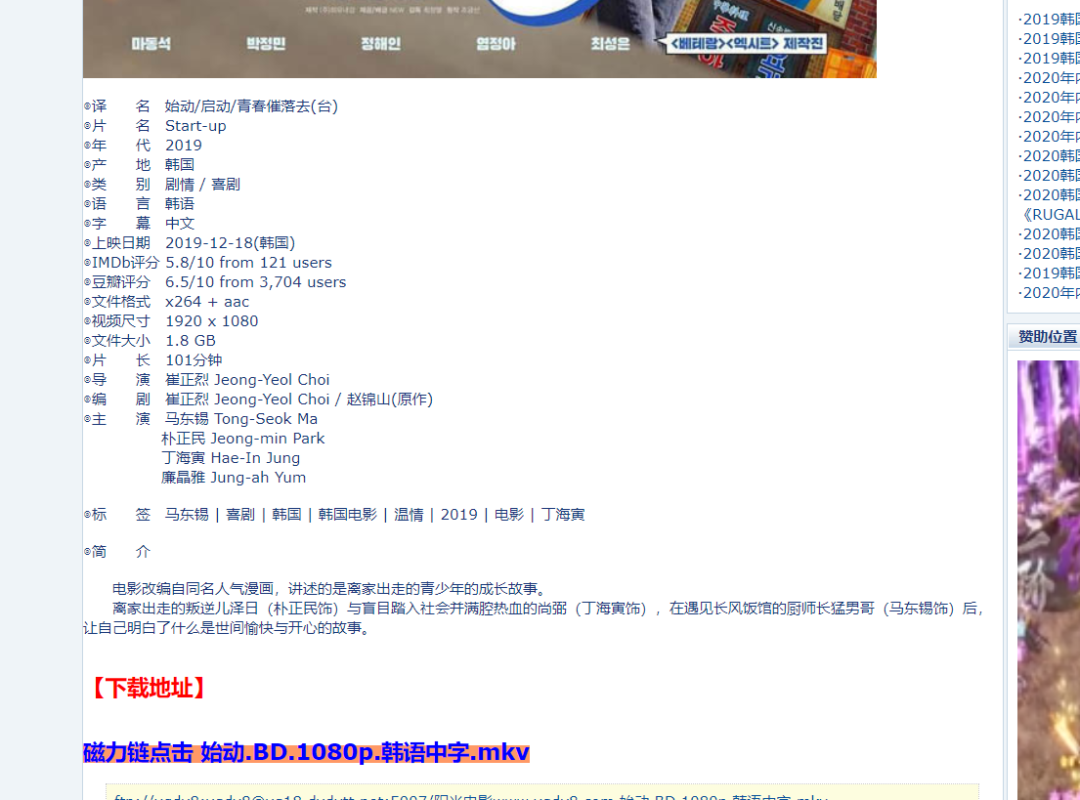
点开第二级页面如图右键点击下载链接,如下图所示:
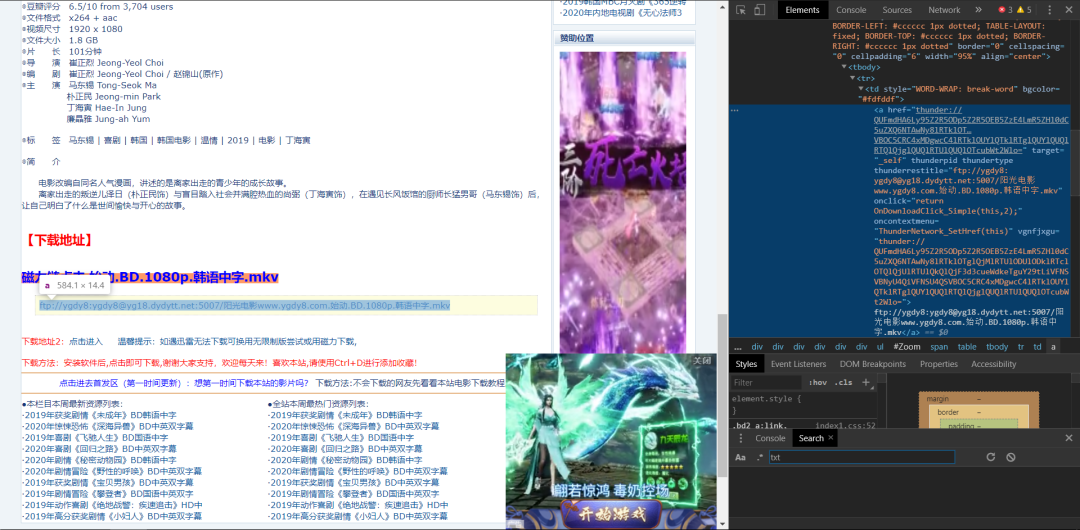
我们用正则表达式解析 得到我们下载链接地址,如下图所示:
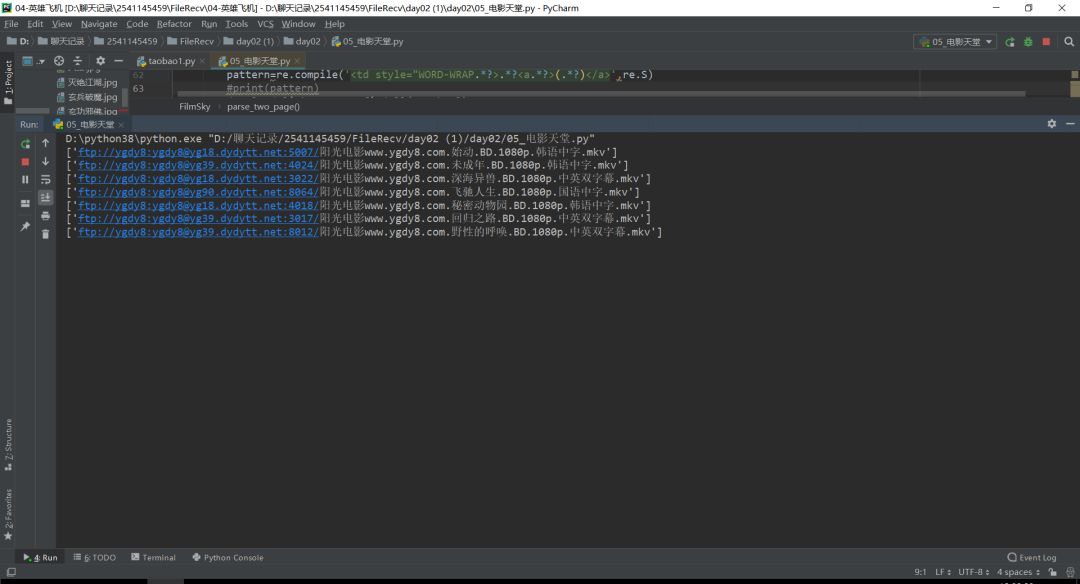
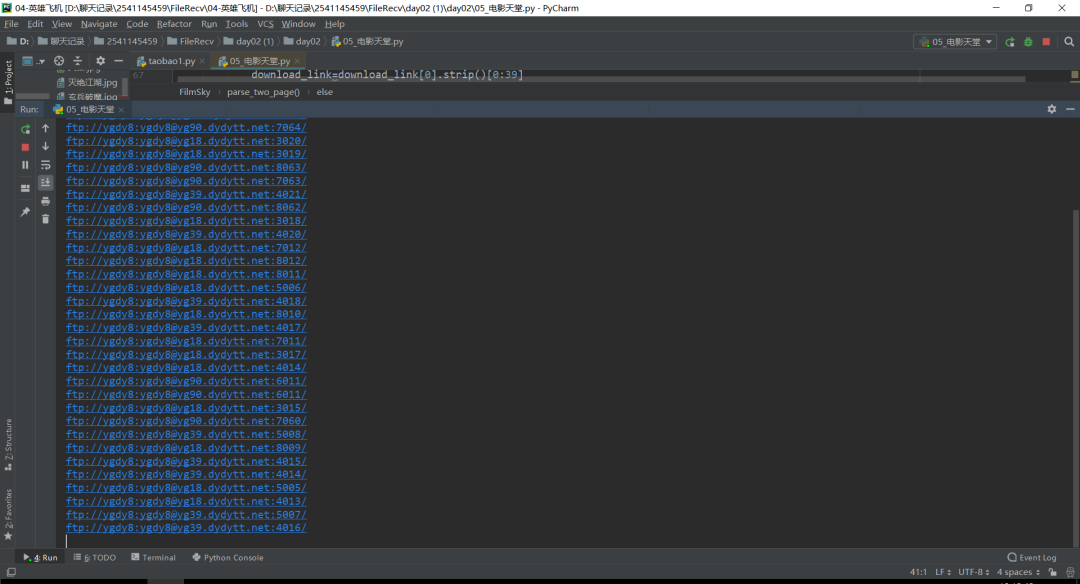
看去了不是很美观,我们把链接处理一下,如下图所示:

得到结果,如下图所示:
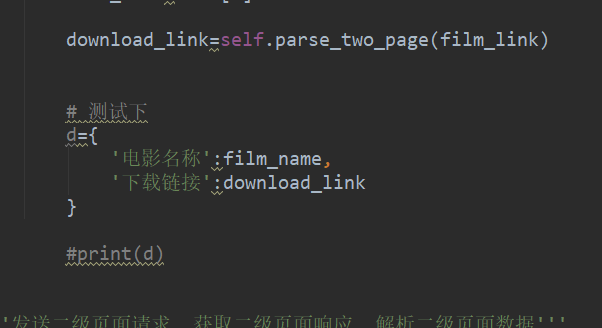
最后我们用把数据保存在一个字典加上下载链接和电影名字:
最后我们优化一下请求的代码有点重复 我们优化一下;
用一个值去保存说明请求头的内容以后请求我们只有调用这个方法进行请求就好,如下图所示:

程序运行之后可以看到效果图,如下图所示:
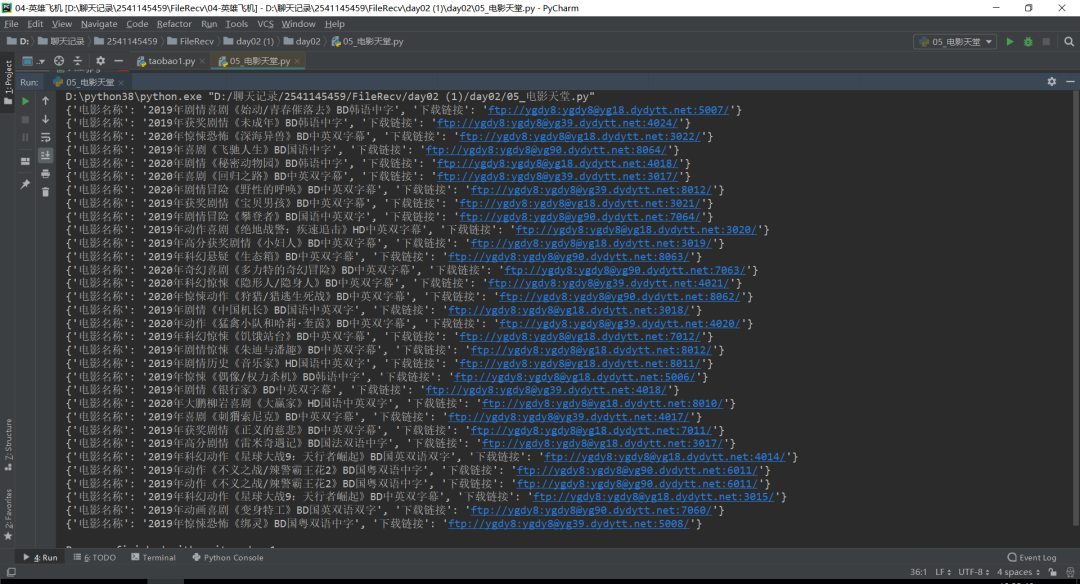
点击蓝色的链接就可以这个下载(要下载迅雷 迅雷下载更快哇)
这样是不是能够更直观的看出你要电影啦?点击即可下载噢!
【五、总结】
1.本文基于Python网络爬虫技术,提供了一种更直观的去看自己喜欢的电影并且方便下载的方式。
2. 不建议抓取太多,容易使得服务器负载。
3. 需要本文代码的话,后台回复“电影天堂”四个字即可获取。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】

------------------- End -------------------
往期精彩文章推荐:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









