





在上一期5分钟学会使用支持向量机 (Using SVM)的文章中,我们讲述了LibSVM的基本用法,那个时候我们针对的分类问题是二分类。实际上,svm经过合适的设计也可以运用于多分类问题,sklearn中的svm模块封装了libsvm和liblinear,本节我们利用它进行多分类。
01
—
SVM回顾
SVM算法最初是为二值分类问题设计的,当处理多类问题时,就需要构造合适的多类分类器。目前,构造SVM多类分类器的方法主要有两类
(1)直接法,直接在目标函数上进行修改,将多个分类面的参数求解合并到一个最优化问题中,通过求解该最优化问题“一次性”实现多类分类。这种方法看似简单,但其计算复杂度比较高,实现起来比较困难,只适合用于小型问题中;
(2)间接法,主要是通过组合多个二分类器来实现多分类器的构造,常见的方法有one-against-one和one-against-all两种。
02
—
一对多法(one-versus-rest,OVR SVMs)
训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
03
—
一对一法(one-versus-one,OVO SVMs)
做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。
假设有四类A,B,C,D四类。在训练的时候我选择A,B; A,C; A,D; B,C; B,D;C,D所对应的向量作为训练集,然后得到六个训练结果,在测试的时候,把对应的向量分别对六个结果进行测试,然后采取投票形式,最后得到一组结果。
投票是这样的:
A=B=C=D=0;
(A,B)-classifier 如果是A win,则A=A+1;otherwise,B=B+1;
(A,C)-classifier 如果是A win,则A=A+1;otherwise, C=C+1;
...
(C,D)-classifier 如果是A win,则C=C+1;otherwise,D=D+1;
The decision is the Max(A,B,C,D)
04
—
层次支持向量机(H-SVMs)
层次分类法首先将所有类别分成两个子类,再将子类进一步划分成两个次级子类,如此循环,直到得到一个单独的类别为止。
05
—
svm.SVC参数说明
多分类调用的核心函数为sklearn中的svm.SVM,现就其用法做简要说明。
函数原型:
sklearn.svm.SVC(C=1.0, # 惩罚参数,默认为 1.0 kernel='rbf', # 核函数 degree=3, # 多项式poly函数的维度,默认是3,选择其他核函数时会被忽略 gamma='auto', # ‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features coef0=0.0, # 核函数的常数项。对于‘poly’和 ‘sigmoid’有用 shrinking=True, # 是否采用shrinking heuristic方法,默认为true probability=False, # 是否采用概率估计,默认为False tol=0.001, # 停止训练的误差值大小,默认为1e-3 cache_size=200, # 核函数cache缓存大小,默认为200 class_weight=None, # 类别的权重,字典形式传递。设置第几类的参数C为weight*C verbose=False, # 允许冗余输出 max_iter=-1, # 最大迭代次数,-1为无限制 decision_function_shape=None, # ovo’, ‘ovr’ or None random_state=None) # 数据洗牌时的种子值主要调节的参数有:C、kernel、degree、gamma、coef0,其中:
C 越大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱;C越小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
kernel:核函数,默认是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
gamma 越大,支持向量越少,gamma 越小,支持向量越多。支持向量的个数影响训练和预测的速度。
06
—
核函数
在用SVM处理问题时,如果数据线性不可分,希望通过将输入空间内线性不可分的数据,映射到一个高维的特征空间内,使数据在特征空间内是线性可分的,这个映射记作 ϕ(x),之后优化问题中就会有内积ϕi⋅ϕj,这个内积的计算维度会非常大,如果在高维空间中进行计算则耗费算力和资源非常大。引入了核函数,我们可以很快地做一些计算。
核函数形式 K(x, y) = ,其中 x, y 为 n 维,f 为 n 维到 m 维的映射, 表示内积。
常见核函数归纳如下:
线性核,主要用于线性可分的情况,我们可以看到特征空间到输入空间的维度是一样的。在原始空间中寻找最优线性分类器,具有参数少速度快的优势。对于线性可分数据,其分类效果很理想。因此我们通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的。
优点:
1. 方案首选,奥多姆剃刀定理
2. 简单,可以快速解决一个QP问题
3. 可解释性强:可以轻易知道哪些feature是重要的
限制:
只能解决线性可分问题
多项式核,基本原理是依靠升维使得原本线性不可分的数据线性可分,将低维的输入空间映射到高维的特征空间。多项式核适合于正交归一化(向量正交且模为1)数据,属于全局核函数,允许相距很远的数据点对核函数的值有影响。参数d越大,映射的维度越高,计算量就会越大。
优点:
1. 可解决非线性问题
2. 可通过主观设置Q来实现总结的预判
缺点:
多项式核函数的参数多,当多项式的阶数d比较高的是,由于学习复杂性也会过高,易出现“过拟合”现象,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算。
高斯核,其可以将一个样本映射到一个更高维的空间内,该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能,而且其相对于多项式核函数参数要少,因此大多数情况下在不知道用什么样的核函数的时候优先使用高斯核函数,高斯径向基核对数据中存在的噪声有着较好的抗干扰能力。
优点:
可以映射到无线维
决策边界更为多样
只有一个参数,相比多项式核容易选择
缺点:
可解释性差(无限多维的转换,无法算出W)
计算速度比较慢(当解决一个对偶问题)
容易过拟合(参数选不好时容易overfitting)
Sigmoid核来源于神经网络,被广泛用于深度学习和机器学习中。采用Sigmoid函数作为核函数时,支持向量机实现的就是一种多层感知器神经网络,应用SVM方法,隐含层节点对输入节点的权重都是在设计(训练)的过程中自动确定的。而且支持向量机的理论基础决定了它最终求得的是全局最优值而不是局部最优值,也保证了它对未知样本的良好泛化能力而不会出现过学习线性。
吴恩达给出的选择核函数的方法
1. 如果特征的数量大道和样本数量差不多,则选用LR或者线性核的SVM
2. 如果特征的数量小,样本的数量正常,则选用SVM+ 高斯核函数
3. 如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况
07
—
实验
为了验证SVM的性能,选取120组数据(已经过正规处理)作为训练集和测试集。数据说明如下:
1-30组数据为0类数据,31-60组数据为1类数据,61-90组数据为2类数据,91-120组数据为3类数据。其中选取每类数据的前20组作为训练集(总计80组),剩下40组为测试集。
遍历C值的精度变化:
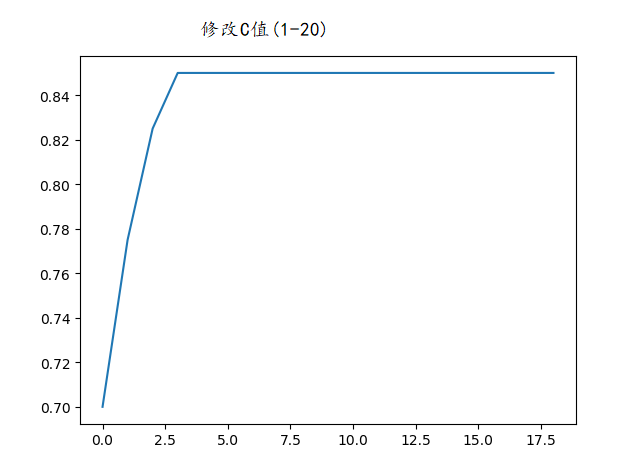
加入gamma参数影响下的精度变化:
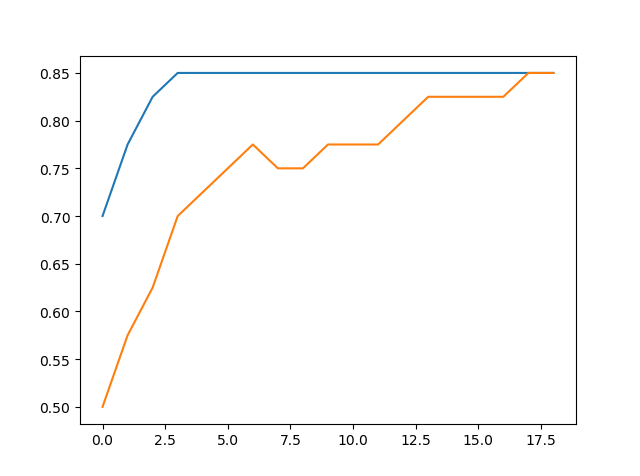
这种情况下,修改gamma参数还不如直接设auto效果好,因此在本数据集下确定重要参数C=3.2。
核心代码:
from sklearn import svmimport joblibpath = r'\xadata.csv'X, Y = gettraindata(path) # 读数据,返回的分别是一个矩阵和列表# X为raw data,Y为标签数据,共80组model = svm.SVC(decision_function_shape='ovo', C=3.2)model.fit(X, Y)joblib.dump(model, r'\model.pickle')# model = joblib.load('model.pickle') 读取用print(testaccuracy(path, model)) # 准确率为0.85















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









