





目录(2018-12-30版)
- 方案试验的配置介绍
- 服务器系统安装
- 深度学习基础环境搭建
- 快速配置Jupyter远程交互环境
- 服务器用户分配与DL环境共用
- 用户定制个人DL环境并切换
- DL环境的高效克隆复现
先啰嗦一把,本文是年初写好但是一直没有整理发出,这是第一篇:非docker版的解决方案;后续写第二篇:Docker版的解决方案。
背景:当时带我的小姐姐拉开一个纸箱,展示了一台电脑在我面前,说:“这个小服务器就交给你了,你给自己和每个组员(人数不多)都设个非root账号,实现每个组员都能用公用DL环境和个人DL环境并方便切换的解决方案,我出差过两天回来”,于是当时没太经常使用linux的小白Licko度过了痛并快乐着的三天... 磕磕绊绊可算弄好了,写得不够好,但是大体都写出来了,分享一下!
需求:
- 公用深度学习环境(非重度使用者)和个人深度学习环境之间方便切换;
- 每个用户自己的环境方便克隆和复现;
- 分系统盘和数据盘存放公用数据以及个人较大的数据;
一. 本次教程实践配置介绍
硬件配置
- 主机:超微4028 GR-TR服务器
- GPU:Nvidia Titan XP pascal * 4
- CPU:Intel E5-2678 V3 * 2,2.5G主频,12核24线程
- 内存:64G DDR4 RECC * 4
- SSD :Intel S4500 960G 企业级SSD * 1
- 硬盘:希捷 2TB SATA3 企业级硬盘 * 5
软件配置
- 系统:Ubuntu 16.4(本次主讲16.04,也在18.04测试过有效)
- 驱动:NVIDIA driver 415.13-BETA版 或 NVIDIA driver 410.78
- DL环境:CUDA 9.0 + cuDNN 7.0.5 + Tensorflow-gpu1.5 + Pytorch 1.0.0
百度云盘
- 百度云盘提供本教程所需安装包:链接在这里,密码:3efp
二. 服务器Ubuntu 16.04 系统安装
制作U盘启动盘并进行 Ubuntu 系统的安装,这里选择的是Desktop版,当时没有准备server版,安装过程基本和百度教程一致,为了节省篇幅本文略过。
- 安装过程参考:服务器上安装乌班图ubuntu16.04.3的详细步骤。
- 安装镜像下载:ubuntu-16.04-desktop-amd64.iso
系统安装过程也有一些问题,主要问题在于:Ubuntu分区方案选择、多硬盘合并挂载问题
Ubuntu分区方案选择
该问题,是服务器各目录具体如何分配空间的问题,需要了解清楚各类分区在系统中所起到的作用。当时我们随便分了一下,仅供参考,以1T SSD为例,实用大小960G多,当时分区方案利用率比较低,后来改成如下是:
/home = 余下所有 # 存放各用户个人文件的地方
/usr = 50G # Unix Software Resource,用于linux系统存放软件,如果安装的软件多,需要大点
/ = 20G # 整个目录结构的起始点 ,所有其它文件和目录都在它下面
/var = 40G # Variable files,软件运行所产生的数据存放目录,如日志、数据库文件、缓存文件
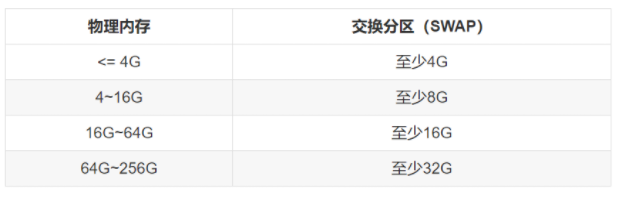
/swap = 32G # 交换分区,虚拟内存
/boot = 0.5G # 存放开机文件,一般100M~300M
/tmp = 10G # Temporary files,用于存放临时文件,对于多用户系统很重要其中,关于设置合适交换分区swap大小规则,看下图,来自Red Hat Enterprise Linux
当然,分区方案需要根据自己的需求来分,具体最好参考以下链接:(推荐先看第一篇再看第二篇)
Linux 分区指南《Ubuntu Server 最佳方案》blog.csdn.net Ubuntu分区方案(菜鸟方案、常用方案和进阶方案) - 顺瓜摸藤 - 博客园www.cnblogs.com多硬盘合并挂载问题
应该不少同学也会有这样的需求:我们组的需求是后面需要做一个小型数据库,存放一些训练样本集,所以要将另外5个硬盘合并一起方便使用。
解决方案就是使用硬件阵列卡RAID或者软件RAID实现。我们目前尝试过软RAID方案,但是只能实现同时挂3个硬盘,而且加之软RAID没有硬RAID那么安全(毕竟人家硬RAID可以有备用电池保证数据安装),所以我们组目前倾向于前者,当时采购没有买RAID卡,目前还在购置..
后来购置了没配置电池的硬RAID卡,后来技术人员说,两张盘以上才能做RAID卡,所以我们当时的960G SSD应该换成两块大概500G SSD,然后加RAID,抗风险能力更好,可以去谷歌补一下RAID卡的知识,我也忘了,待补充..
当时这部分不是我操作的,是服务器公司专业技术人员过来拆机装进去的,所以就没有相关图片,抱歉,不过可以给出一些参考连接(后面补)
三. 深度学习基础环境搭建
- 安装ssh
这步是为了实现后续安装完所有环境后,我们能通过ssh工具远程连接使用服务器进行命令行操作。
sudo apt-get install openssh-server 常用的SSH工具有:Xshell、puTTY、MTpuTTY等,两个工具都不错,大同小异,带我的小姐姐使用Xshell,我使用的是MTpuTTY(听说有个十分强大的工具:mobaxterm),后来我也用Xshell去了..
2. 安装Vim、Wget
VIM是Ubuntu强大的文字编辑器,Ubuntu自带的是vi,更新到VIM会比较好,不然可能会出现编辑文档时按不了左右上下。VIM的安装与配置
sudo apt-get install vim #安装VIM
vim --version #查看VIM版本Wget,可用于下载东西,用法 :wget -c http://xxxxxxxxxx.com,可实现断点续传和后台下载等,类似于axel,可自行百度。
apt-get update #先检查更新
apt-get install wget #安装wget
wget --version #检查wget版本3. 安装Nvidia Titan XP (pascal)显卡驱动
a. 删除ubuntu默认自带的驱动。许多人忽略了这一步,就直接安装自己的显卡驱动,导致许多问题的出现。通过下面命令删除默认驱动。
sudo apt-get purgenvidia*b. 添加Graphic Drivers PPA
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-getupdatec. 自动搜索合适的驱动版本。这一步使用在线下载的方式下载英伟达显卡驱动,当然也可以通过官网离线下载,或者浏览开头我给出的百度链接下载.
ubuntu-drivers devices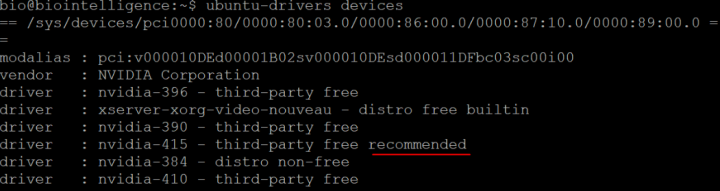
Licko备注:很纳闷,为什么没有显示GPU型号,通过命令" lspci | grep -i vga"也看不到,不过影响不大,提了采购单后确认是4个TITAN xp的GPU
通过搜索结果,ubuntu推荐的是nvidia-415驱动,当时我所参考的那篇教程,使用的命令是nvidia-driver-415,对我来说无效,需要改成如下:
sudo apt-get install nvidia-415
Licko吐槽:当时查了不少教程,很多博客命令都是用的
nvidia-driver-415,真不知道他们原文直接复制粘贴到自己博客有什么意思。我当时一直显示失败,然后我就在这里卡了许久,一直在纠结是不是显卡的型号没有选择正确,我把它推荐的所有型号都手动尝试了一次,我无奈只能尝试离线下载。最后狗血的场面出现了,焦急等待之际,我尝试性地把driver去掉,居然成功了,真是又气又喜!
d. 安装成功后需要重启服务器(电脑)
sudo reboot重启完毕后,查看驱动信息
nvidia-smi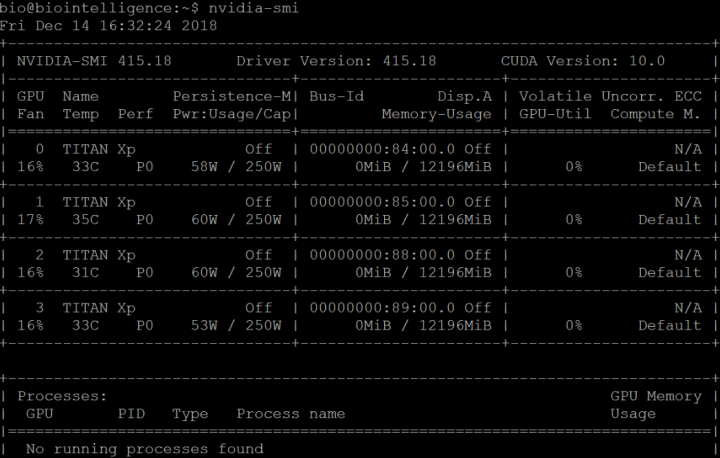
Licko备注:可以看到风扇开启程度、GPU型号、温度、性能等级、功率、内存、利用率等,具体看这里
4. 安装必要依赖库
安装所需的一些依赖库,后续也是基本跟着教程来,都没有什么报错,一行命令:
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-devlibgl1-mesa-glx libglu1-mesa libglu1-mesa-dev5. GCC版本下调
这一步是为了适应CUDA 9.0,要求的是版本5.xx或者是6.xx,需要通过以下命令进行下调与替换,使用合适版本
# 版本安装:
sudo apt-get install gcc-5
sudo apt-get install g++-5
# 替换之前的版本
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 50
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-5 506. 安装CUDA 9.0
备注:下载地址如下:点这里,选择linux--x86-64,Ubuntu--16.04,runfile(local),同样也放在了文章开头给出的百度云盘。我当时下载只有一个文件cuda_9.0.176_384.81_linux.run。
a. 下载之后进入文件所在目录,执行以下命令:
sudo sh cuda_9.0.176_384.81_linux.run注意:安装过程中会用英文提示“是否需要安装对应驱动”,一定要选择no,后面几个都是选择yes,有个同学实力踩坑。。。
b. 设置环境变量
这里需要特别提出下面两点:
一、对于需要考虑多个服务器用户使用公用深度学习环境的同学,在/etc/profile中添加CUDA的路径。
二、对于不需要考虑上述问题的同学,只需要在.bashrc中添加CUDA的路径即可。
使用vi/vim打开/etc/profile
sudo vi /etc/profile使用vi/vim打开~/.bashrc(普通同学,一般不动/etc/profile这个系统变量文件,用bashrc用户变量文件就行)
sudo vi ~/.bashrc进入后,移到最后,添加以下内容:
export LD_LIBRARY_PATH=LD_LIBRARY_PATH:/usr/local/cuda-9.0/lib64/Licko备注:在这里也有一个坑,我之前参考的教程并不是这样的,经过查阅并且多次实践,以上输入内容是稳定有效的。参考在这里
c. 更新环境变量设置
source /etc/profile #考虑多用户公用环境的特殊同学
source ~/.bashrc #不考虑上述问题的普通同学Licko备注:通常更新后就能使其设置生效,我实测有效。但不排除部分意外,所以 最好是关闭开启的所有服务器窗口,重新登陆,当然,直接 重启服务器最稳妥。
重启后,测试CUDA是否安装成功
cd ~/NVIDIA_CUDA-9.0_Samples/1_Utilities/deviceQuery
make -j4
sudo ./deviceQuery若会输出相应的显卡性能信息,Result = PASS,表明CUDA安装成功。
7. 安装CuDNN 7.0.5
本来选用7.4版本,后来遇到问题,所以选择7.0.5版本,问题具体参考点这里,还有这里
注意:cuDNN的下载比较麻烦,需要注册账号并且登陆,还要加入开发者计划什么的,所以这里我直接把我下载好的放在百度网盘,你们自行下载,链接在这里,密码:3efp
下载会有点麻烦,需要登陆后同意协议,具体下载地址,当然我也放在了百度云盘中。这里下载的是:Download cuDNN v7.0.5 [Dec 5, 2017], for CUDA 9.0

下载后文件名为cudnn-9.0-linux-x64-v7.tgz,之后安装非常简单,就是解压然后拷贝到相应的系统CUDA路径下:
#解压
tar -zxvf cudnn-9.0-linux-x64-v7.tgz
#复制
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
#复制
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
#复制与修改权限
sudo chmod a+r/usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*没有报错就是安装成功了.
Licko备注:我当时最后一句出错了,具体截图找不到了,大致意思为修改不成功,理解命令作用后,简单尝试修改后成功,暂时还没有出现什么问题,待大神们指正,改为以下:
sudo cp /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib648. 安装Tensorflow-gpu 1.5
a. 安装anaconda3/miniconda3集成科学计算库
这里推荐安装Anaconda3,或者是体量更小的miniconda3。
有些文章说“都8012年了还无脑推荐别人安装Anaconda?”,这个问题仁者见仁智者见智。我当时选择的miniconda3,现在想想还是应该装anaconda3,后面很多模块不用装, 我的考虑是,后续我需要为服务器中的各个普通user(给小组内各成员用的)提供深度学习环境,他们有用到Jupyter notebook的习惯,而anaconda3能够集成很多模块,为满足不同需求,后续不用太麻烦,直接装anaconda3更好。
这里我们下载Python 3.7 64bit 的Anaconda3-5.3.0-Linux-x86_64.sh,直接安装即可
bash Anaconda3-5.3.0-Linux-x86_64.shb. 创建带有python 3.6 的环境
因为tensorflow-gpu暂时不支持python 3.7,而我们安装的anaconda自带的是3.7,所以要用python 3.6,有两种方式解决,一种是将python3.7降级为3.6,另一种是创建带有python 3.6 的虚拟环境。我采用的是方法一,因为要满足部分服务器用户不想进激活环境就能使用深度学习环境的需求,虽说进环境也很容易,都没问题。
方法①:将python 3.7 降为python 3.6(你们可以选择主流的方法:创建带有python 3.6 的虚拟环境)
pip install --upgrade python==3.6方法②:创建带有python 3.6 的虚拟环境(下面说的都是虚拟环境的方式)
conda create--name tf python=3.6 #创建名为tf的虚拟环境Licko备注:虚拟环境常用命令如下:
source activate tf #激活tf环境
source deactivate tf #退出tf环境
conda remove --name tf --all #删除tf环境(全部删除)两种方法没有本质区别,只是方法一在base环境安装tensorflow-gpu,而方法二在新虚拟环境安装罢了。
c. 修改源,使用pip和conda的国内下载源,下载模块更快
更改pip的源为阿里源
mkdir ~/.pip
cat > ~/.pip/pip.conf << EOF
[global]
trusted-host=mirrors.aliyun.com
index-url=https://mirrors.aliyun.com/pypi/simple/
EOF更改conda的源为清华大学源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yesd. 安装Tensorflow-gpu 1.8
我使用的是指定版本为1.8,若没有指定,自动装下来装的是1.12,出现与cuda版本不匹配的问题,继而出现import tensorflow时失败,修改为1.8才成功,仅供参考:
pip install--ignore-installed --upgrade tensorflow-gpu==1.8将会自动安装如下组件:numpy 、wheel 、tensorflow-tensorboard 、six、protobuf 、html5lib 、markdown、werkzeug 、bleach、setuptools
e. 测试tensorflow-gpu是否安装成功
source activate tf #进虚拟环境,方法一就不用进
python #进python
#测试代码如下
import tensorflow as tf
hello= tf.constant('Hello, TensorFlow!')
sess= tf.Session()
print(sess.run(hello))f. 安装Keras
tensorflow-gpu装在tf虚拟环境的,就进tf装。
pip install keras9. 安装Pytorch1.0
前一两星期Facebook推出了pytorch 1.0版本,不指定版本会自动安装最新版
#不指定版本会自动安装最新版 1.0.0
conda install pytorch torchvision -c pytorch
#指定0.4.1版本会安装旧版 0.4
conda install pytorch==0.4.1 torchvision -c pytorch测试pytorch是否安装成功
source activate tf #进虚拟环境,方法一就不用进
python #进python
import keras #测试keras
import torch #测试pytorch
print(torch.cuda.is_available())没有报错,且返回True就是没问题 。
四. 配置Jupyter远程交互环境
- 进入刚刚创建好的虚拟环境中(你也可以在conda的base环境中装好jupyter进行配置,都一样),生成
.jupyter文件
source activate myenv
jupyter notebook --generate-config --allow-root2. 获取登陆jupyter所需要的密码(为了安全)
# 进入python,输入以下,得到sha值
from notebook.auth import passwd
passwd()3. 会输出一串sha值,复制sha值,用于后续填入`c.NotebookApp.password`中,接着exit()退出python,输入以下,修改jupyter配置文件:
vim ~/.jupyter/jupyter_notebook_config.py修改jupyter配置文件,参数设置含义依次为:
c.NotebookApp.ip='*'
c.NotebookApp.password = u'sha:xxxxxxxxxxxxxxxxxxxxxxx'
c.NotebookApp.open_browser = False
c.NotebookApp.port =8888
c.NotebookApp.allow_root = True
c.NotebookApp.allow_remote_access = True
#c.NotebookApp.notebook_dir = '/home'设置为"*"意思是支持任何ip地址连接,也可以修改成自己(宿主机IP);
设置登陆jupyter的密码转成的sha值;如果不设置就会自动生成一堆token值,也可以的;
设置为禁止自动启动浏览器,因为服务器中没有浏览器,为了避免错误而设;
设置port接口为8888,自己设置的端口号,别与已有端口号冲突即可;
设置支持root权限登陆
设置支持远程连接,否则可能出现不能远程连接的报错
4. 后台启动jupyter,并把log日志记录在当前文件夹下的nohup.out文件中,在浏览器中输入以下即可,http://<宿主IP>:8888
nohup jupyter notebook &
# 在浏览器中输入以下即可,http://xxx.xx.xx.xx:8888
http://xxx.xx.xx.xx:8888
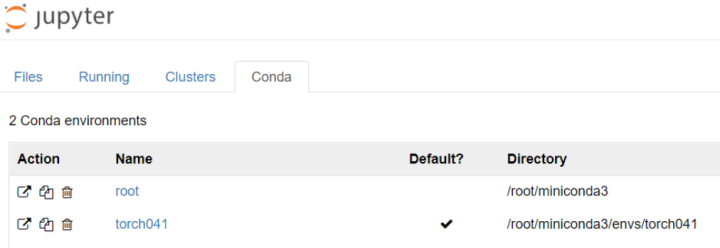
具体参考如下:
服务器 配置 Jupyter notebook 远程访问 (Ubuntu 1blog.csdn.net五.服务器用户分配与DL环境共用
当时带我的小姐姐拉开一个纸箱,展示了一台大机器在我面前,说:“服务器就交给你了,你给每个组员都设个非root账号,每个组员都能用公用的深度学习环境和个人DL环境方案,我出差过两天回来”,于是小白Licko度过了痛并快乐着的三天...
这一步是为了实现各个组员能够用上服务器,能够用上搭建好的深度学习环境,并且保护搭建好的深度学习环境不被破坏。主要分为两步,设置非root用户,将深度学习环境的路径添加进系统环境变量(/etc/profile)中。
- 分配普通用户、设置密码并设置用户分组
先设置非root权限服务器用户,这步是为了每个人都能在服务器上拥有自己的一片小天地,而不打扰其他人的小天地。在这里,大家可以存放自己的东西,大家也可以相互查看大家的一些学习资料代码等等,当然也可以修改哪些可以被其他组员看到、被复制等等。
现在有一个拥有root权限、名为bio的root用户,以下步骤进入bio进行操作。假设现在有五个组员,需要分别为他们设置名为AA、CC、GG、TT、UU(碱基大家庭hhh)的普通服务器用户,并且设置一个名为BI的组,没有root权限,只能在自己对应目录下进行活动,但是也是可以在看其他用户的文件等等。
下面创建一个属于BI组别、名为AA的用户,并创建同名目录,设置shell为bash。
sudo groupadd BI
#创建一个名为BI的普通组
sudo useradd -m AA -g BI -s bash
#创建一个属于BI组别、名为AA的用户,并创建同名目录,设置shell为bash
sudo passwd AA
#会进入密码口令设置,输入、确认。Licko备注:这里 一定要设置shell为bash,否则进入该用户后,出现按不了上下左右等等问题。具体参考:
常用操作
- 添加文件夹的用户 sudo useradd -m AA -g bioUser -s /bin/bash
- 添加用户密码 sudo passwd AA
- 查看是否添加成功 cat /etc/passwd 或 grep AA/etc/passwd
- 删除用户和其目录 sudo userdel -r AA
- 修改用户属性 usermod [-c -d -e -f -g -G -l -s -u] AA
- 添加用户组账号 groupadd bioUser
- 删除用户组账号 groupdel bioUser
- 查询用户组账号 grep bioUser /etc/group
- 修改用户的组别 usermod -g users user1 将用户user1的组改为users组
具体参考如下:
Ubuntu用户及用户组管理命令blog.csdn.net2. 设置各非root用户可共用深度学习环境
这一步,是为了让每个非root的普通用户能够用到已搭建好的深度学习环境,让刚刚创建的每个用户,不用去求管理员要root权限来搭建自己的DL环境,不然的话,你需要考虑面临以下问题:
- 怎么安装anaconda
- 怎么安装CUDA等让人头疼的环境
- 更可怕的是,没有root权限,你辛苦百度到的常规安装方法统统不管用!
现在,只需要简单一行,就能让各非root用户使用深度学习环境,欢快地将CIFAR-10的案例跑起来!(我等小白,硬生生卡了一天才完整实现下来,是有点糗)
只需要设置环境变量即可,在 /etc/profile中添加CUDA的路径,具体如下:
a. 使用vi/vim打开/etc/profile
sudo vi /etc/profileb. 进入后,在末尾添加以下内容:(注意:自己把xxxx改成你们的主用户名)
# adde the path of anaconda3
export PATH="/home/xxxx/anaconda3/bin:$PATH"
# add the path of CUDA 9.0
export LD_LIBRARY_PATH=LD_LIBRARY_PATH:/usr/local/cuda-9.0/lib64/c. 更新环境变量设置
source /etc/profiled. 查看是否添加成功
进入某个用户中,输入
conda info -e # conda info --envs
你就可以实现:不用自己安装环境也能用,还看到主用户bio下安装好的基础conda环境、虚拟环境等等。
六.用户个性化DL环境定制并切换
上述方式可以实现每个人都能用到公用的深度学习环境环境(在bio创建好的),而且也不会相互打扰,但是!!同样也带来了麻烦,不能对该深度学习环境进行添加与修改,除非公用环境拥有大量各种各样的模块(不太现实啦,100个用户有100种需求呢),否则,意味着我要用新的模块装不了,更用不了。
所以为了解决上述问题,可以采用以下方案,实现用户个性化DL环境定制:
Licko补充:当时完全不知道Docker的概念,哈哈,其实可以用docker的方式解决,后面重装系统之后也使用了这种方式,会接着出第二篇,详情参见Deepo,感谢评论区提醒!
- 创建用户独立的conda环境
- 使用公用的CUDA框架环境
- 用户自己安装所需模块
步骤如下:
- 创建自己想要的conda环境(miniconda等)
跟前面提到的安装anaconda环境一致,不再赘述。
2. 在用户下的~/.bashrc添加自己的conda环境路径
安装完anaconda等环境时,会询问是否在该用户下的bashrc写入conda环境的路径,选择y即可,无需做什么操作,就能用自己的环境了。
3. 个人DL环境与公用DL环境的切换
这里需要搞清楚优先级问题,若系统环境变量中和用户环境变量中都有conda环境,系统会优先使用用户自己安装的环境。
系统级别的环境变量存放在`/etc/profile`中,用户环境变量存放在`~/.bashrc`中,
如果想要使用自己本身的DL环境,保证`~/.bashrc`中conda的路径是激活的即可
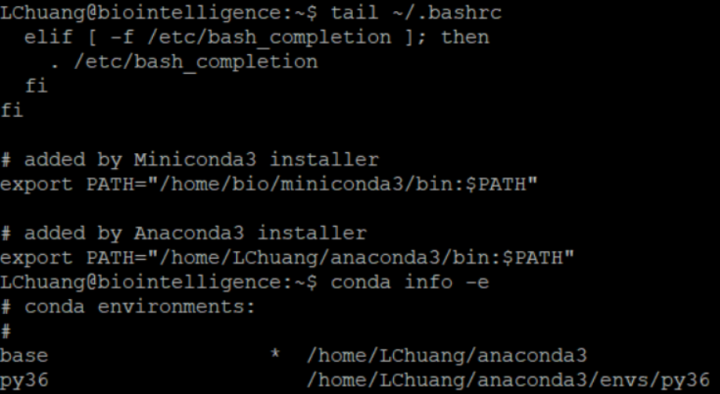
比如:现在查看系统环境变量,bio有miniconda3环境,查看某用户环境变量,某用户有anaconda3环境,系统会优先使用用户创建的anaconda3环境,如下图:
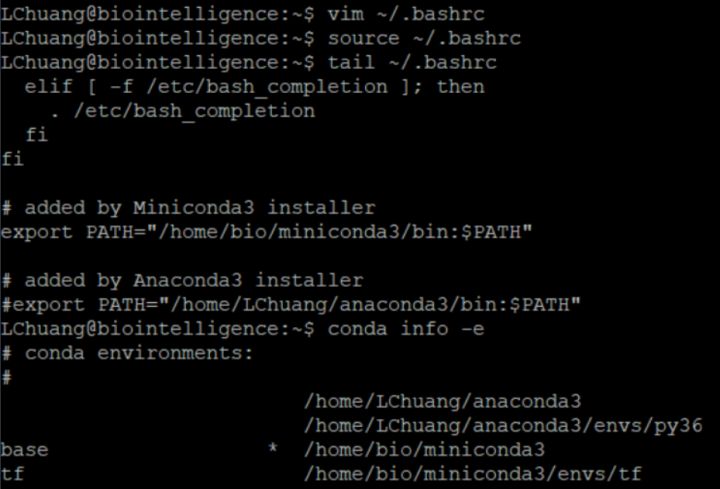
如果我将用户自己的环境路径用#来注释掉,
# 1.进入用户环境变量文件中进行修改
vim ~/.bashrc
# 2.使用"#"将"export PATH="/home/LChuang/anaconda3/bin:$PATH""注释
# added by Anaconda3 installer
# export PATH="/home/LChuang/anaconda3/bin:$PATH"
# 3. 保存并退出vim,更新用户环境变量文件(非常重要)
source ~/.bashrc结果如下:
所以借助设置环境变量路径以及系统的这个优先级关系,用户可以自己选择使用自己的环境还是公用的环境,岂不美哉!
需要注意的是:安装完anaconda3环境,最好使用tail ~/.bashrc,查看用户环境变量文件中是否写入了环境的路径,或者是路径格式是否为如下:
# added by Anaconda3 installer
export PATH="/home/LChuang/anaconda3/bin:$PATH"如果不是,不能说一定出错,但可能出错,前两天帮Doctor解决问题,弄到最后才发现,是这个路径格式出问题了。
3. 设置公用CUDA框架路径不变
在有root权限的bio用户下搭建的CUDA框架当时是将路径加入了系统环境变量文件中的,所以如果有做这一步,在这里是不需要再进行什么修改,就可以用自己的conda环境,使用公用的CUDA框架,进行GPU加速运算。只需要使用“less /etc/profile”,翻到最后,查看系统变量中是否有这一行即可。
export LD_LIBRARY_PATH=LD_LIBRARY_PATH:/usr/local/cuda-
9.0/lib64/4. 用户自行安装自己想要的tensorflow版本等等模块
具体前面提到,不再赘述。
七.DL环境的高效克隆复现
- 同机DL环境克隆
比如AA用户不想使用公用深度学习环境了,因为公用环境存在诸多不便,比如:不给安装新模块,不给更新等等。AA想要一个自己的深度学习环境,他可以自己选择基于公用深度学习环境创建虚拟环境(这种治标不治本)、新装anaconda环境(就是上述方法可行但可能麻烦)
上述方法可以实现用户DL环境个性化定制,用户有自己的权限去修改自己的环境,只是需要花点时间安装模块罢了。但是!!
问题一:用户个性化定制DL环境,这种方式是非常不错,但是它需要一个一个慢慢安装,如果我需要极速复现这个环境呢?
问题二:有时我在朋友的环境可以跑这个代码,在自己的环境跑同样的代码却不可以,检查来检查去,也没有发现什么不同,唯一不同的就只有模块版本不同。
综上,有时候模块版本不同,依赖不同,会导致很多代码不能复现结果,如果我能够拥有当时跑代码的那个环境就好了,没问题!!经过查阅多种方法,多种方法的多次采坑、多种方式的测试,最后确定了一种高效的DL环境克隆解决方案。
只需要一行命令,就可以自动克隆环境,不用烦恼依赖问题,不用担心原用户路径绑定问题,而且克隆过程非常快(有时候不一定,比如我在becca和DL姐那里是极速克隆,我自己的却等了好久,重启一下就可以了)
在尝试并验证了三种方法后,最终选择了以下方案,基本完美克隆原环境,且可以摆脱原用户的环境路径“枷锁”。比如现在在同一台服务器(已有CUDA公用框架)新建了一个新用户,想要克隆bio的环境:
conda create -n pytest --clone /home/bio/miniconda3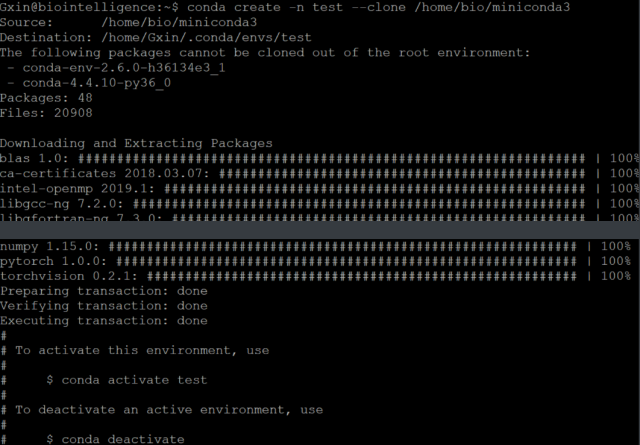
整个过程只用了1分钟左右(有时不一定,若是全新用户,很多需要重新装,若是本身有其他环境,一些共用的模块不会再次安装)。后续进行过多天测试代码使用,均未发生问题。
值得一提的是:这种方式还可以实现同机克隆,也可以实现异机环境复现,采用yaml的方式
- 异机DL环境复现
这次来补坑(2018-12-30)。
如果有新的服务器需要配置深度学习环境,如何快速、高效、准确地安装上自己想要的环境呢?
通过在yaml文件中列出想要安装的集成模块、指定版本、安装方式,自动让conda去根据现有环境下载安装所需依赖模块,更加灵活,而且可以根除直接克隆可能所带来的旧用户依赖问题。
a. 创建yaml文件
可以根据自己的需求去确定安装哪些模块,指定想要的模块版本,指定安装环境名字,指定安装的镜像等等,推荐比较大的集成模块还是在conda中安装,比如pytorch,好处是能够灵活根据现有CUDA环境,自动匹配所需的依赖模块。
channels:
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free
- defaults
dependencies:
- python=3.6
- jupyter=1.0.0
- matplotlib=2.2.2
- pandas=0.23.2
- numpy=1.15.4
- pytorch=0.4.1
- torchvision=0.2.1
- pip:
- tensorflow-gpu==1.8
- keras==2.2.0
- mxnet==1.5.0b20181215
- d2lzh==0.8.11
- sklearn b. 根据yaml文件,创建虚拟环境
先进入yaml文件的放置位置,执行:
conda env create -n xxxxx -f environment-Gxin_backup.yaml 安装成功后,source activate xxxxx,进入命令行进入python,import测试一下即可。
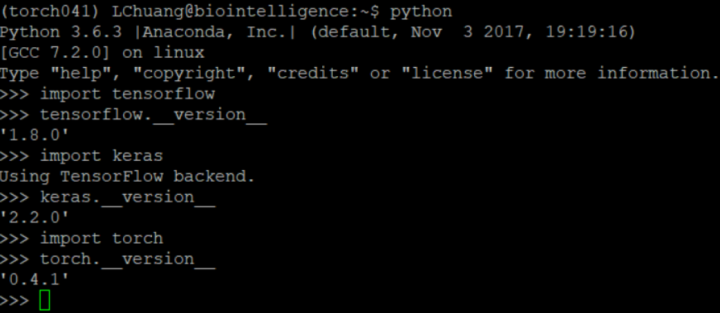
因为这个过程是全新下载安装,而不是快速克隆,所以需要一定的时间。如果出现网络中断导致一些模块未安装完旧进入下一个模块安装,只需要等待最终结束的时候再执行一次同样的命令即可,conda可以断点续传,会自动安装上次未安装好的模块。
再不幸一点,它提示已存在该env,最多就conda remove -n xxx --all移除这个环境重新安装即可,问题不大的。
八. 总结
以上就是我这一周的小成果啦!(草稿)















 2996
2996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









