






花费了很长时间整理编辑,转载请标明出处。
前言
平时工作经常需要大批量处理文档数据。有一次要将上千个比较大的表格(.csv 为后缀的文档)合并到一起,写了个Python Merge Function。程序运行了半个多星期,中途因为自己一个不小心,把运行一半的程序关掉了。当时简直要抓狂了。后来觉得不是办法,就花了一整天时间研究了现有的提高程序运行速度的方法。重新改了程序,半天就运行出来了,真的是事半功倍。好东西和大家一起分享,所以有了这篇博文。今天的主人公--Dask,简单,容易上手,用起来实在是太友好了。
为什么选用Dask
现如今在进行海量数据处理的时候,我们可能经常陷入数据太大,电脑内存不够的窘境。如果你经常使用Pandas和Numpy,但有时要处理的数据很大但电脑内存有限,那么Dask绝对是首选。当然,Dask的并行处理功能也很好的提高了电脑运行速度。并行处理数据意味着更少的执行时间,更少的等待时间和更多的分析时间!Dask支持Pandas数据框和Numpy数组数据结构,并且可以在本地计算机或者扩展到集群上运行。更重要的是,Dask语句和我们平时用的Pandas和Numpy非常的相似。如果你不想花很多时间去学习像Hadoop或Spark这样的大数据工具,Dask是一个很好的选择。
熟悉的用户界面
通过对比Dask与我们熟悉的Pandas,Array等功能执行同样功能的语句,可以看出使用Dask简直不要太简单!
Dask DataFrame 模仿 Pandas - documentation
import pandas as pd import dask.dataframe as dd
df = pd.read_csv('2015-01-01.csv') df = dd.read_csv('2015-*-*.csv')
df.groupby(df.user_id).value.mean() df.groupby(df.user_id).value.mean().compute()Dask Array 模仿 NumPy -documentation
import numpy as np import dask.array as da
f = h5py.File('myfile.hdf5') f = h5py.File('myfile.hdf5')
x = np.array(f['/small-data']) x = da.from_array(f['/big-data'],
chunks=(1000, 1000))
x - x.mean(axis=1) x - x.mean(axis=1).compute()Dask Bag 模仿 iterators, Toolz, and PySpark -documentation
import dask.bag as db
b = db.read_text('2015-*-*.json.gz').map(json.loads)
b.pluck('name').frequencies().topk(10, lambda pair: pair[1]).compute()Dask Delayed 模仿 for loops and wraps custom code -documentation
from dask import delayed
L = []
for fn in filenames: # Use for loops to build up computation
data = delayed(load)(fn) # Delay execution of function
L.append(delayed(process)(data)) # Build connections between variables
result = delayed(summarize)(L)
result.compute()大家可以访问Dask的官方网页了解详细的功能介绍。这里我以数据处理中比较常用的Dask DataFrame和dask.delayed为例,介绍如何使用Dask提高数据处理速度和节省内存的使用。
Dask DataFrames函数具体介绍及Python程序示范
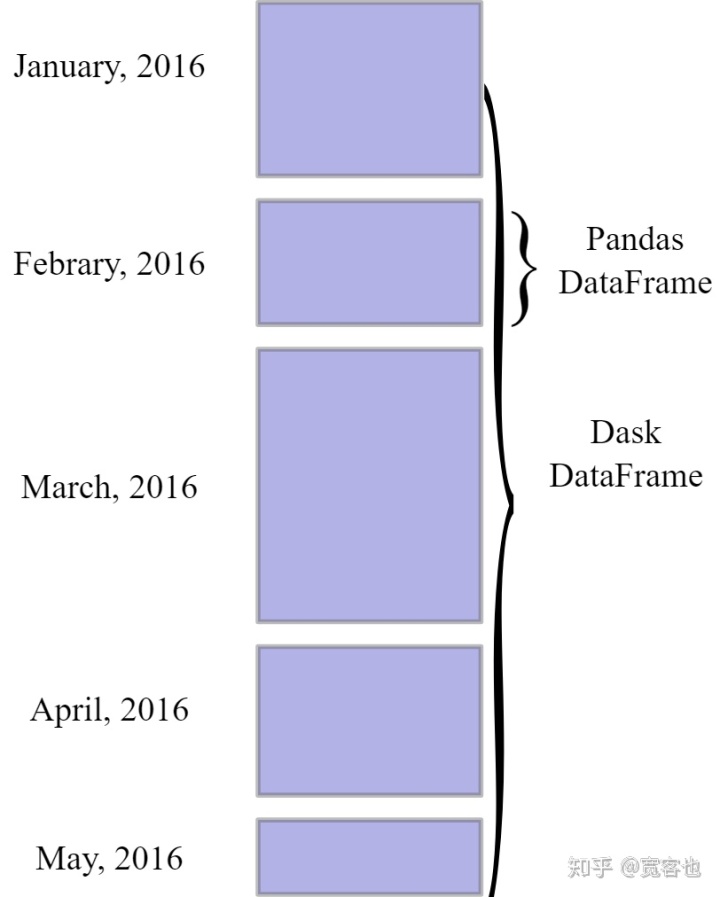
上图直观的表示了Dask与Pandas Dataframes的不同,Dask Dataframes可以通过一个索引来整合多个Pandas Dataframes。它们支持Pandas 大部分的API。
- 创建随机数据框
我们创建具有以下属性的随机数据时间序列:
- 它存储2000年每10秒的记录
- 它将数据按月份拆分并存储为单独的Pandas数据框保存
- 除日期时间索引外,它还具有名称,id和数字值的列
这是一个约240 MB的小型数据集。
import dask
import dask.dataframe as dd
df = dask.datasets.timeseries()与Pandas不同,Dask DataFrames并不显示具体数据,只显示列名和数据类型。
df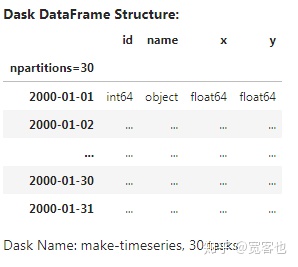
我们当然也可以通过以下操作来像Pandas Dataframe一样显示数据:
import pandas as pd
pd.options.display.precision = 2
pd.options.display.max_rows = 10
df.head(3)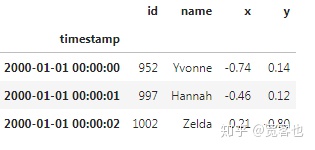
- 常用Pandas函数的操作
Pandas中大多数常见的操作在DASK中的操作是相同的,比如:
df2 = df[df.y > 0]
df3 = df2.groupby('name').x.std()
df3如果希望计算结果以Pandas dataframe表示的话,可以调用.compute():
computed_df = df3.compute()
type(computed_df)
computed_df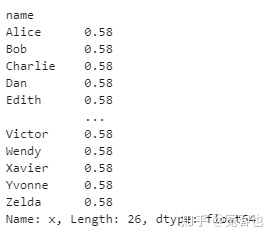
- 通过persist()函数提高运行速度
如果内存足够大的话,可以通过persist()函数将数据保留在内存中,这样可以提升以后的计算速度。
df = df.persist()因为数据有一个datatime索引,所以可以高效的进行时间序列操作
%matplotlib inline
df[['x', 'y']].resample('1h').mean().head()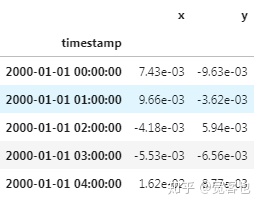
df[['x', 'y']].resample('24h').mean().compute().plot()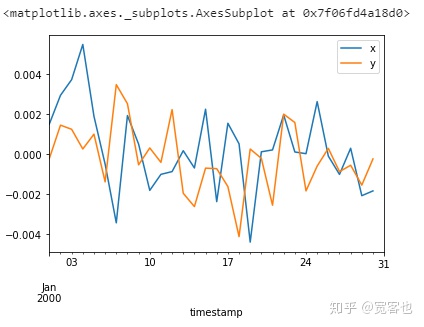
通过索引的随机访问速度也提高了很多:
%time df.loc['2000-01-05'].compute()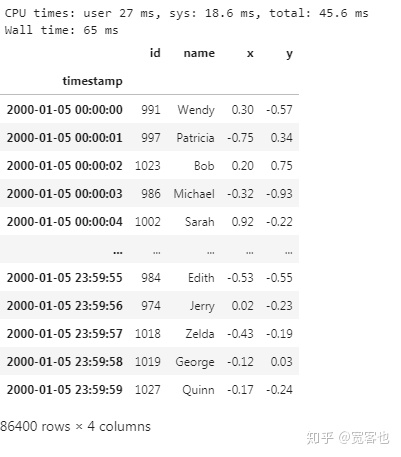
- 设定索引
将数据按索引列排序可以更快的访问,联接,实现groupby-apply等操作。但是对数据进行排序会花费比较多的时间,所以尽量减少数据排序的操作。
df = df.set_index('name')
df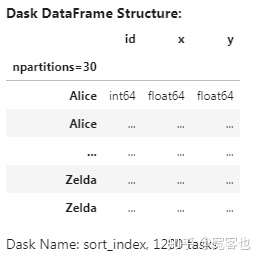
因为计算此数据集的成本很高,当我们有足够的内存时,我们可以将数据集持久存储到内存中以提高运行速度。
df = df.persist()通过persist()函数,Dask知道所有数据存放位置及索引。随机访问这样的操作就变得非常快捷
%time df.loc['Alice'].compute()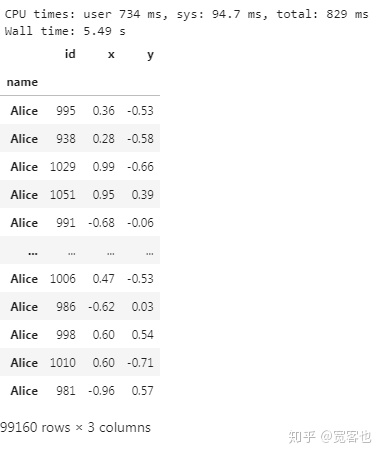
- Groupby和Scikit-Learn的结合使用
通过按照名称对数据进行排序,可以轻松地进行诸如对名称的随机访问或使用自定义函数进行groupby-apply的操作。
在这里,我们针对每个名称训练不同的Scikit-Learn线性回归模型。
from sklearn.linear_model import LinearRegression
def train(partition):
est = LinearRegression()
est.fit(partition[['x']].values, partition.y.values)
return est
df.groupby('name').apply(train, meta=object).compute()以上通过dataframe介绍了Dask的基本概念及功能,大部分资料都来自于Dask的官网。Dask官网也做得非常详细,里面包含了很多例子及在线的Jupyther Notebook。以下附上链接:
Dask - Dask 2.16.0 documentationdocs.dask.org使用dask.delayed并行化代码
Dask的另一个重要功能是并行化代码。这里介绍一下如何将简单的函数通过dask.delayed进行并行化处理。
我们首先设计几个基本函数(toy functions)
from time import sleep
def inc(x):
sleep(1)
return x + 1
def add(x, y):
sleep(1)
return x + y计算正常情况下运行需要多长时间:
%%time
x = inc(1)
y = inc(2)
z = add(x, y)
大概需要三分钟运行,因为每个函数都需要一分钟时间运行,我们依次调用了三个函数。
但是,我们发现前两个增量函数是可以并行处理的,因为它们完全彼此独立。以下,我们通过使用dask.delayed并行化代码:
from dask import delayed对每个函数加delayed装饰器:
%%time
x = delayed(inc)(1)
y = delayed(inc)(2)
z = delayed(add)(x, y)dask.delayed是类似于装饰器的作用,如下所示:
@delayed
def inc(x):
sleep(1)
return x + 1
@delayed
def add(x, y):
sleep(1)
return x + y注意,到这步为止,z对象是延迟的Delayed 对象。程序并没有做任何计算。
通过使用.visualize()可视化此值的任务图:
z.visualize()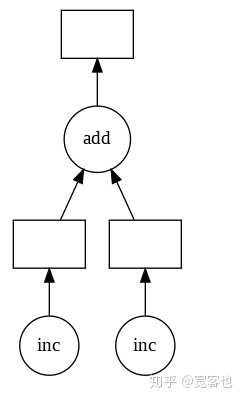
我们可以通过调用compute来计算并得到最终结果。通过并行计算可以提高代码运行速度。
%%time
z.compute()
接下来我们并行化for循环
data = [1, 2, 3, 4, 5, 6, 7, 8]普通循环及所需时间
%%time
results = []
for x in data:
y = inc(x)
results.append(y)
total = sum(results)
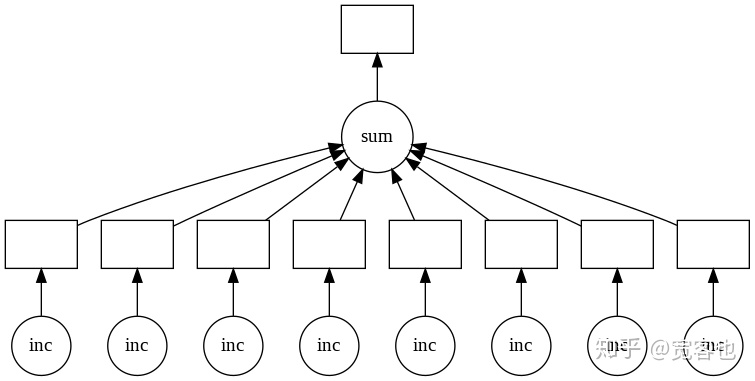
通过delayed进行并行处理及所需时间
results = []
for x in data:
y = delayed(inc)(x)
results.append(y)
total = delayed(sum)(results)
total.compute()
通过visualizae()实现并行处理可视化:
Reference:
Dask DataFrames — Dask Examples documentation:https://examples.dask.org/dataframe.html
Dask in 15 minutes: https://nbviewer.jupyter.org/github/danbochman/Open-Source-Spotlight/blob/master/Dask/Dask.ipynb















 1787
1787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









