






 本文介绍了Stata中的倾向得分匹配(PSM)分析,包括PSM的基本概念、分析过程、模型设定、假设条件、一般步骤,以及如何在Stata中进行实例操作。通过PSM方法,可以解决非随机观察研究中的选择偏差问题,以评估政策效应。文章还提供了匹配样本的回归分析和Stata命令实例。
本文介绍了Stata中的倾向得分匹配(PSM)分析,包括PSM的基本概念、分析过程、模型设定、假设条件、一般步骤,以及如何在Stata中进行实例操作。通过PSM方法,可以解决非随机观察研究中的选择偏差问题,以评估政策效应。文章还提供了匹配样本的回归分析和Stata命令实例。
NEW!连享会·推文专辑:Stata资源 | 数据处理 | Stata绘图 | Stata程序结果输出 | 回归分析 | 时间序列 | 面板数据 | 离散数据交乘调节 | DID | RDD | 因果推断 | SFA-TFP-DEA文本分析+爬虫 | 空间计量 | 学术论文 | 软件工具
连享会学习群-常见问题解答汇总:
? WD 主页:https://gitee.com/arlionn/WD
? 连享会主页:lianxh.cn

Stata 暑期班:9天直播
? 时间:2020.8.1-8.7
? 提示:初级班已经开班,不再接受报名
? 嘉宾:连玉君 (中山大学) | 江艇 (中国人民大学)
? 主页:https://gitee.com/arlionn/PX | ? 微信版「基础不牢,地动山摇……」

作者:占云 (华侨大学)
邮箱:953185016@qq.com
目录
1. PSM 简介
2. PSM 的分析过程
2.1 PSM 模型设定
2.2 PSM 的假设条件
2.3 PSM 一般步骤
3. PSM 的 Stata 实例
4. PSM 匹配样本的回归
参考文献
1. PSM 简介
在经济学中,我们通常希望评估某项公共政策实施后的效应,为此,我们构建 "处理组" 和 "控制组" 以评估「处理效应 (treatment effect)」。然而,我们的数据通常来自非随机的观察研究中,处理组和控制组的初始条件不完全相同,故存在「选择偏差 ( selection bias)」问题。「倾向得分匹配 (PSM)」法使用倾向得分函数将多维向量的信息压缩到一维,然后根据倾向得分进行匹配。这样可以在既定的可观测特征变量下,使得处理组个体和控制组个体尽可能相似,因而可以缓解处理效应的选择偏差问题。
2. PSM 的分析过程
2.1 PSM 模型设定
对于个体 ,根据是否进行某项处理可以分为两种结果:
- 表示个体 是否进行某项处理,即 1 表示处理,0表示未处理;
- 表示个体进行处理的结果;
- 表示个体未进行处理的结果。
在给定可观测特征变量 情况下,个体 进入处理组的条件概率为:
根据式 (1) 和 (2) 可得参与者的平均处理效应 (ATT) 为:
2.2 PSM 的假设条件
共同支撑假设 (Common Support Assumption)
对于 的任何可能取值,都有 $0
平行假设 (Balancing Assumption)
给定 ,则 独立于 。此假定意味着,对于给定的 ,处理是随机的,即在接受处理之前,处理组和控制组之间没有差异,处理组产生的效应完全来自处理。
2.3 PSM 一般步骤
选择协变量 :尽可能涵盖影响 与 的相关变量;
获取 PS 值:可以使用 probit 或 logit 模型估计;
检验平行假设是否满足:使得 在匹配后的处理组均值和控制组均值较接近,保证数据平衡;
根据 PS 值将处理组个体和控制组个体进行配对:匹配的方法有最近邻匹配、半径匹配、核匹配等;
根据匹配后样本计算 ATT 。
3. PSM 的 Stata 实例
PSM 可通过下载非官方命令 psmatch2 来实现:
*-安装命令
ssc install psmatch2, replace
首先,导入数据并对数据集进行描述,这里我们研究的处理变量为 first,结果变量为 piatm56,一共 3100 个观测值:
*-数据下载地址
*https://gitee.com/arlionn/data/blob/master/data01/nlsy.dta
*-数据描述
use nlsy.dta, clear
describe
Contains data from nlsy.dta
obs: 3,100
vars: 29 20 Oct 2004 15:03
-----------------------------------------------------------------------------------------------------------------------------------------------------
storage display value
variable name type format label variable label
-----------------------------------------------------------------------------------------------------------------------------------------------------
row_names float %9.0g
hispanic float %12.0g hispanic hispanic
black float %9.0g black black
white float %9.0g white white
momrace float %9.0g momrace mother's race
female float %9.0g female female
b_marr float %9.0g b_marr mom married at birth?
pr0 float %12.0g pr0 was household in poverty the year before child was born?
lths float %9.0g mom's ed is less than high school
hs float %9.0g mom is hs grad
ltcoll float %9.0g mom attended some college
college float %9.0g mom finished college
momed float %21.0g momed mom's education level when she gave birth
lnfinc_a0 float %9.0g logged family income in the year before the child was born
age float %9.0g child's age (in months) on 1/1/90
momage float %9.0g
afqt float %9.0g mom's score on the armed forces qualifying test
brthwt float %9.0g birthweight of child (oz)
brorddum float %10.0g brordum first born?
preterm float %9.0g weeks preterm
rmomwk float %9.0g rmomwk did respondent's momther work while she was in high school?
work float %46.0g treat did mom work in the first 3 years?
ppvt float %9.0g peabody picture vocab test score at 36 months
piatm56 float %9.0g score on the piat math component at age 5 or 6
piatm78 float %9.0g score on the piat mathcomponent at age 7 or 8
piatr56 float %9.0g score on the piat reading component at age 5 or 6
piatr78 float %9.0g score on the piat reading component at age 7 or 8
notfirst float %9.0g
first float %9.0g
-------------------------------------------------------------
接下来,使用 psmatch2 进行倾向得分匹配,本文以最近核匹配方法为例进行演示:
*-psmatch2 匹配
global x "b_marr lths hs ltcoll pr0 lnfinc_a0 momage afqt brthwt brorddum preterm rmomwk"
psmatch2 first $x, kernel out(piatm56) comm
Probit regression Number of obs = 3,100
LR chi2(12) = 238.74
Prob > chi2 = 0.0000
Log likelihood = -1665.419 Pseudo R2 = 0.0669
------------------------------------------------------------------------------
first | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
b_marr | -.2223596 .0654868 -3.40 0.001 -.3507113 -.0940078
lths | -.4985053 .1307273 -3.81 0.000 -.7547261 -.2422846
hs | -.2806145 .1154503 -2.43 0.015 -.506893 -.054336
ltcoll | -.1677297 .1182472 -1.42 0.156 -.3994901 .0640306
pr0 | -.2622162 .0779939 -3.36 0.001 -.4150814 -.1093511
lnfinc_a0 | .1518044 .0332006 4.57 0.000 .0867325 .2168763
momage | .0237162 .0094355 2.51 0.012 .0052229 .0422095
afqt | .0032104 .0015551 2.06 0.039 .0001625 .0062583
brthwt | -.0007553 .0014355 -0.53 0.599 -.0035687 .0020582
brorddum | .033481 .0557905 0.60 0.548 -.0758665 .1428285
preterm | .0073301 .0169733 0.43 0.666 -.025937 .0405973
rmomwk | -.1820912 .0517634 -3.52 0.000 -.2835456 -.0806369
_cons | .4429969 .3761257 1.18 0.239 -.2941961 1.18019
------------------------------------------------------------------------------
----------------------------------------------------------------------------------------
Variable Sample | Treated Controls Difference S.E. T-stat
----------------------------+-----------------------------------------------------------
piatm56 Unmatched | 99.7904637 98.6314496 1.15901406 .538980148 2.15
ATT | 99.7236668 101.121726 -1.39805928 .623590775 -2.24
----------------------------+-----------------------------------------------------------
Note: S.E. does not take into account that the propensity score is estimated.
psmatch2: | psmatch2: Common
Treatment | support
assignment | Off suppo On suppor | Total
-----------+----------------------+----------
Untreated | 0 814 | 814
Treated | 17 2,269 | 2,286
-----------+----------------------+----------
Total | 17 3,083 | 3,100
估计结果包含 3 个部分,第 1 部分是 probit 回归的结果。第 2 部分是处理组和控制组在匹配前后的差异及其显著性,可以看出,匹配前处理组和控制组差异为 1.15901406,t 值为 2.15,匹配后处理组和控制组差异 -1.39805928,而 t 值为 -2.24。第 3 部分则汇报观测值共同取值范围情况。在 3100 个观测值中,除了处理组 17 个不在共同取值范围中,其余 3083 个均在共同取值范围中。
接下来,我们使用 pstest 命令来考察匹配结果是否较好地平衡了数据的差异性,即检验是否满足平行假设。
*-平衡性检验
pstest $x
------------------------------------------------------------------------------
| Mean | t-test | V(T)/
Variable | Treated Control %bias | t p>|t| | V(C)
------------------------+--------------------------+---------------+----------
b_marr | .73821 .75189 -3.0 | -1.06 0.291 | .
lths | .19877 .20155 -0.6 | -0.23 0.815 | .
hs | .46056 .46982 -1.9 | -0.63 0.532 | .
ltcoll | .23535 .23531 0.0 | 0.00 0.998 | .
pr0 | .19348 .19718 -0.8 | -0.31 0.753 | .
lnfinc_a0 | .62747 .58741 3.7 | 1.48 0.139 | 1.06
momage | 24.011 23.958 1.7 | 0.57 0.571 | 0.92
afqt | 65.467 64.939 2.7 | 0.91 0.365 | 1.06
brthwt | 118.09 117.85 1.2 | 0.40 0.688 | 0.98
brorddum | 1.4716 1.4542 3.5 | 1.17 0.242 | 1.01
preterm | .69451 .64465 3.0 | 1.02 0.306 | 1.17*
rmomwk | .3539 .3394 3.0 | 1.03 0.305 | .
------------------------------------------------------------------------------
* if variance ratio outside [0.92; 1.09]
----------------------------------------------------------------------
Ps R2 LR chi2 p>chi2 MeanBias MedBias B R %Var
----------------------------------------------------------------------
0.002 11.54 0.483 2.1 2.3 10.1 1.17 17
----------------------------------------------------------------------
* if B>25%, R outside [0.5; 2]
结果显示,匹配后所有变量的标准化偏差 ( % bias ) 均小于5 %,且所有 t 检验结果接受原假设「处理组与控制组无系统差异」,因此平行假设得到满足。
接下来,通过 psgraph 绘图直观显示倾向得分的共同取值范围:
*-共同取值范围
psgraph
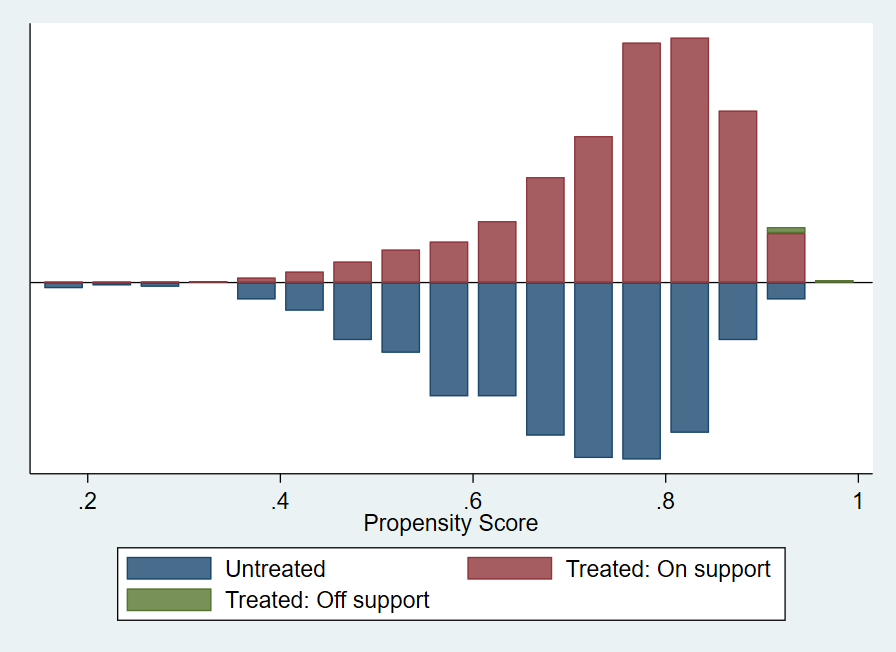
从图中可以直观地看出,控制组全部在共同取值范围内,处理组仅有少部分不在共同取值范围内 (Off support),在进行匹配时仅会损失少量样本,与我们之前的分析一致。
4. PSM 匹配样本的回归
在 psmatch2 运行后会默认生成样本权重变量 _weight,它能够表示某个观测值是否成功匹配以及匹配的重要性程度,因此可以使用样本权重代入回归方程 (在回归命令中加入 [pw=_weight]) 计算调整后的 ATT。
*-结果对比
regress piatm56 first $x
est store ols
regress piatm56 first $x [pw=_weight]
est store psm_ols
local m "ols psm_ols"
esttab `m', mtitle(`m') compress nogap ar2
------------------------------------
(1) (2)
OLS PSM_OLS
------------------------------------
first -1.298** -1.619***
(-2.51) (-2.76)
b_marr -0.405 0.0408
(-0.71) (0.05)
lths -3.544*** -2.940**
(-3.35) (-2.12)
hs -2.796*** -2.593**
(-3.14) (-2.15)
ltcoll -2.579*** -2.159*
(-2.86) (-1.69)
pr0 -0.327 0.749
(-0.46) (0.86)
lnfinc_a0 0.855*** 1.285***
(2.88) (3.00)
momage -0.0572 0.0943
(-0.69) (0.78)
afqt 0.205*** 0.208***
(15.05) (11.66)
brthwt -0.00463 0.0107
(-0.37) (0.62)
brorddum 1.894*** 2.314***
(3.90) (3.47)
preterm -0.236 -0.226
(-1.60) (-1.05)
rmomwk -0.265 -0.402
(-0.58) (-0.71)
_cons 89.40*** 82.38***
(27.40) (19.24)
------------------------------------
N 3100 3083
adj. R-sq 0.152 0.160
------------------------------------
t statistics in parentheses
* p<0.1, ** p<0.05, *** p<0.01
可以看出,OLS 结果是基于所有观测值进行估计,且估计效应 ATT 为 -1.298,并在 5% 的水平上显著;而 PSM_OLS 是基于成功匹配的 3083 个观测值进行估计,且估计效应 ATT 为 -1.619,并在 1% 的水平上显著。
参考文献
温馨提示: 文中链接在微信中无法生效。请点击底部
- Becker, S. O., & Ichino, A. (2002). Estimation of Average Treatment Effects Based on Propensity Scores. The Stata Journal, 2(4), 358–377. -Link-
- Titus, M. A. (2007). Detecting selection bias, using propensity score matching, and estimating treatment effects: an application to the private returns to a master’s degree. Research in Higher Education, 48(4), 487-521. -Link-
- Sianesi, B. (2010). An introduction to matching methods for causal inference and their implementation in Stata. Stata Users Group. -Link-
? 连享会 - 文本分析与爬虫 - 专题视频? 已上线:可随时购买,7.31 日下架
? 主讲嘉宾:司继春 || 游万海
? 课程主页:https://gitee.com/arlionn/text

连享会 - 效率分析专题
? 已上线:可随时购买,7.31 日下架
? 主讲嘉宾:连玉君 | 鲁晓东 | 张宁? 课程主页:https://gitee.com/arlionn/TE

? ? ? ?
连享会主页:? www.lianxh.cn
直播视频:lianxh.duanshu.com

免费公开课:
- 直击面板数据模型:https://gitee.com/arlionn/PanelData - 连玉君,时长:1小时40分钟
- Stata 33 讲:https://gitee.com/arlionn/stata101 - 连玉君, 每讲 15 分钟.
- 部分直播课课程资料下载 ? https://gitee.com/arlionn/Live (PPT,dofiles等)
温馨提示: 文中链接在微信中无法生效。请点击底部

关于我们
- ? 连享会 ( 主页:lianxh.cn ) 由中山大学连玉君老师团队创办,定期分享实证分析经验。
- ? 直达连享会:【百度一下:连享会】即可直达连享会主页。亦可进一步添加 主页,知乎,面板数据,研究设计 等关键词细化搜索。
- ? 公众号推文分类: 历史推文分为多个专辑,主流方法介绍一目了然:DID, RDD, IV, GMM, FE, Probit 等。
连享会 · 推文专辑:Stata资源 | 数据处理 | Stata绘图 | Stata程序结果输出 | 回归分析 | 时序 | 面板 | 离散数据交乘调节 | DID | RDD | 因果推断 | SFA-TFP-DEA文本分析+爬虫 | 空间计量 | 学术论文 | 软件工具
? 连享会小程序:扫一扫,看推文,看视频……

? 扫码加入连享会微信群,提问交流更方便


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









