





点击蓝字
关注我们
提高知识水平
Transportation

导语
交通分配(Traffic Assignment)是交通规划四阶段法的最后一步,其中随机分配(Stochastic Assignment)方法是其中一种重要方法。随机分配主要基于“随机用户平衡”(Stochastic User Equilibrium,即SUE)理论实现,其中Dial算法是求解SUE问题的经典方法,具体理论可参考《交通规划》教材中随机交通分配方法。本文在简单回顾Dial理论方法基础上,通过C++进行编程实现,同时设计了求解交通问题简单的并行计算结构,为求解大规模问题提供思路与方法。
1.首先回顾Dial方法的基本理论与基本步骤。
2.其次较为详尽解释Dial方法的C++编程实现。
3.最后提供程序完整解决方案,供大家交流学习。
一、Dial算法具体步骤
步骤1:初始化。确定有效路段和有效径路.
•计算从起点r到所有节点的最小阻抗,记为r(i);
•计算从所有节点到终点s的最小阻抗,记为s(i);
•定义Q(i)为路段起点为i的路段终点的集合;
•定义D(i)为路段终点为i的路段起点的集合;
•对每个路段(i,j),根据下式计算路段似然值(Link Likelyhood)L(i,j)(此时通常假定参数b=1):
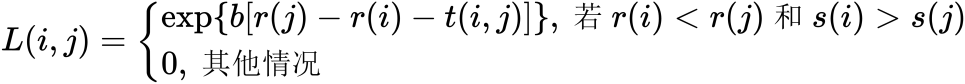
由该公式可知,凡是似然值等于0的路段都是不合理路段,不应该考虑包含它们的径路;凡是似然值大于0的路段都可以考虑包含在有效径路中;当某径路包含的所有路段的似然值都等于1时,该径路必然是最小阻抗径路。
Dial算法中的初始化过程,实质就是确保出行量分配在使其有效地远离其起始节点的 径路上,那些“走回头路”的径路将被剔除掉。
步骤2:从起点r开始按照r(i)升的顺序,向前计算路段权重。
从起点r开始,按照r(i)的上升顺序依次考虑每个节点,对每个节点,计算离开它的所有路段的权重值,对于节点i,其权重W(i,j), j∈O(i)的计算公式为:
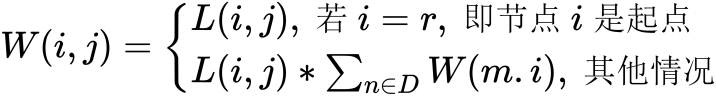
当达到终点s,即i=s时就停止权重的计算。
步骤3:从终点$开始,按照s(Q上升的顺序,向后计算路段交通量。
从终点s开始,按照s(j)的上升顺序依次考虑每个节点,对每个节点,计算进入它的所 有路段的交通量,对于节点j,其交通量x(i,j), i∈D(i)的计算公式为:
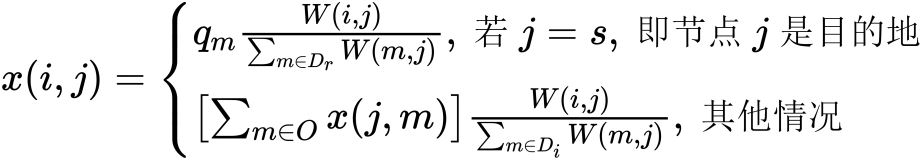
当达到起点r,即j=r时停止计算。同时整个算法结束。式中qn表示从起点r到终点s的OD交通量,方括号内的交通量之和是指节点j的所有下游路段上的交通量之和,它们应该先于路段(i,j)上的交通量事先已被计算出来,所以节点的考虑顺序是十分重要的。

二、数据文件准备
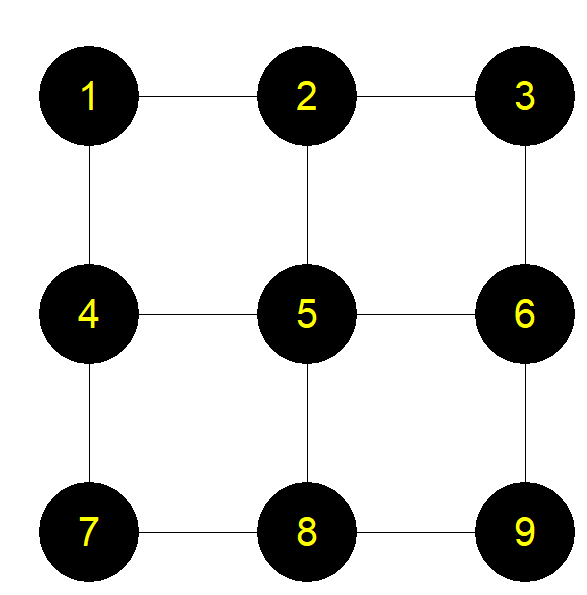
下面以邵春福老师《交通规划》中的路网为案例基础进行数据文件准备。文件包括路网节点node.csv,路网连接边link.csv,待分配流量demand.csv。
(1)node.csv
Node数据存储于g_node_vector中,字段信息如下图所示:
node_id | zone_id | x_coord | y_coord |
结点编号 | O-D小区编号 | X坐标 | Y坐标 |
(2)link.csv
Link数据存储于g_node_vector中,字段信息如下图所示:
road_link_id | from_node_id | to_node_id | length |
路段编号 | 路段起点编号 | 路段终点编号 | 路段长度 |
(3)demand.csv
Demand数据存储与g_demand_vector中,字段信息如下图所示:
from_zone_id | to_zone_id | number_of_agents |
交通量产生地点编号 | 交通量吸引地点编号 | 交通量数值 |
路网拓扑结构如图所示:
三、简单C++编程实现
大规模交通网络具有较高的计算挑战性,C++在计算效率上具有相当优势,故本次使用C++语言实现,不熟悉C++语言也可通过Python实现算法过程。鉴于篇幅原因,这里仅介绍程序整体框架及Dial核心算法部分,I/O等可参见源程序,若有一定C++基础更易理解。
(1)主程序框架
int main(){// 1.计时开始clock_t startTime, endTime;startTime = clock();// 2.读取数据,包括node,link,demandg_ReadInputData(assignment);// 3.准备所有node间最短径路,使用Floyd方法实现(Dijstra亦可)float** adj_matrix;adj_matrix = floyd_SPP(assignment);// 4.重置所有link流量为0for (int i = 0; i < assignment.g_number_of_links; i++) { g_link_vector[i].volume = 0.0;}// 5.准备并行计算工作台(将所有OD均分至工作台)g_assign_computing_tasks_to_memory_blocks_SUE(assignment);// 6.每个工作台中分别执行Dial算法#pragma omp parallel forfor (int ProcessID = 0; ProcessID < g_NetworkForSUE_vector.size(); ProcessID++) { g_NetworkForSUE_vector[ProcessID]->Dial_subnetwork(adj_matrix);}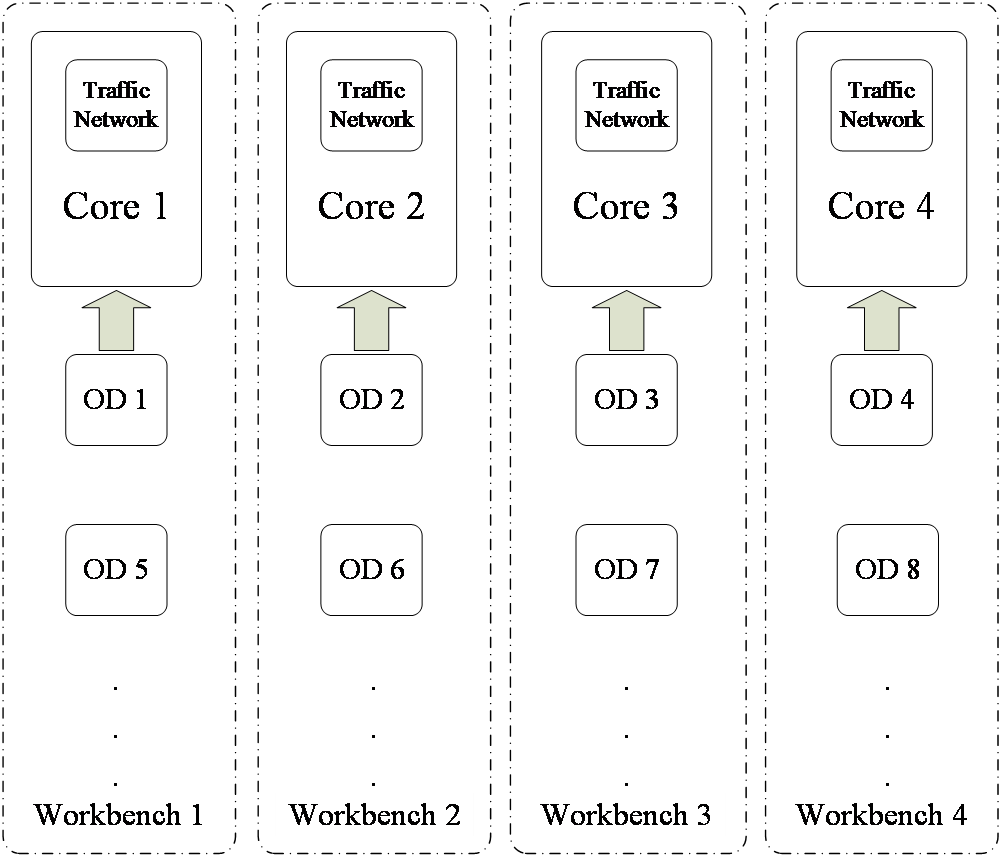
// 7.输出结果g_output_RLSUE_result(assignment);// 8. 释放Floyd矩阵内存空间for (int i = 0; i < assignment.g_number_of_nodes; i++){ delete[] adj_matrix[i];}delete[] adj_matrix;// 9.计时停止endTime = clock();cout << "The run time is: " << (double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl;system("pause");return 1;}(2)基本函数及类的声明与定义
(按程序中顺序介绍)
1.class Assignment {……}: 该项计算任务的全局信息,node数量、link数量、demand数量、并行计算线程数量等。
2.class CNode, class Clink, class CDemand: 分别存储node(编号、坐标等),link(两端节点,长度等),demand(O-D点,需求量等)的相关信息。
3. class CCSVParser {……}:读取CSV文件工具类。(这个可以不看,主要作用是打开文件,找到字段等)。
4.void g_ReadInputData() {……}:读取node.csv, link.csv, demand.csv文件,将数据存至相应vector中。
5.class NetworkForSUE {……}: Dial算法核心类(划重点!),算法实现的核心步骤在这里面,后面会详细介绍。
6. void g_assign_computing_tasks_to_memory_blocks_SUE(){……}: 实现并行计算核心步骤,将不同O-D对平均分在不同工作台运算,提高计算机利用效率,如下图所示(以4核为例):
7. void fopen_ss()/void g_output_RLSUE_result():结果输出函数,输出result.csv,主要包括每条link的流量信息。
8. float** floyd_SPP():计算最短路径函数,通过Floyd方法。
(3)Dial算法实现程序
Dial算法程序可在NetworkForSUE类下找到,即:void Dial_subnetwork()。代码有些长,希望你可以看完。
第1步:初始化。
第1.1步:计算从起点r到所有节点的最小阻抗,记为r(i);计算从所有节点到终点s的最小阻抗,记为s(i)。程序中分别使用数组r_distance[i], s_distance[i]表示。
for (int i = 0; i < assignment.g_number_of_nodes; i++) { r_distance[i] = adj_matrix[origin_node][i]; //阻抗值从flyod矩阵获得。}for (int i = 0; i < assignment.g_number_of_nodes; i++) { s_distance[i] = adj_matrix[i][destination_node];}第1.2步:计算路段似然值,计算公式见上文。
for (int i = 0; i < assignment.g_number_of_links; i++) { int from_node = g_link_vector[i].from_node_seq_no; int to_node = g_link_vector[i].to_node_seq_no; if ((r_distance[from_node] < r_distance[to_node]) & (s_distance[from_node] > s_distance[to_node])) { link_likelihood[i] = exp((float)b_Dial * (r_distance[to_node] - r_distance[from_node] - (float)g_link_vector[i].lenth)); if (link_likelihood[i] > 65535) //由于部分最短路不存在(距离无穷大),造成似然值过大,此时该路不可行,似然值为零 link_likelihood[i] = 0; }}第2步:从起点r开始按照r(i)上升的顺序,向前计算路段权重。
第2.1步:按照r(i)上升的顺序形成排序数组,记录于r_index_list中。按照s(i)上升的顺序形成排序数组,记录于s_index_list中。
vector<float> r_distance_array(assignment.g_number_of_nodes);for (int i = 0; i < r_distance_array.size(); i++) r_distance_array[i] = r_distance[i];vector<size_t> r_index_list;r_index_list = sort_indexes_e(r_distance_array); //排序函数,返回值为关键字排序后的下标值vector<float> s_distance_array(assignment.g_number_of_nodes);for (int i = 0; i < s_distance_array.size(); i++) s_distance_array[i] = s_distance[i];vector<size_t> s_index_list;s_index_list = sort_indexes_e(s_distance_array);第2.2步:按照r_index_list的顺序,向前逐步计算路段权重。
for each (int node_list_no in r_index_list) { //按照r_index_list的顺序遍历 CNode node = g_node_vector[node_list_no]; if (node.node_seq_no == destination_node) //遍历至终点停止 break; if (node.node_seq_no == origin_node) { //遍历至起点开始,起点的label为0. for each (int next_link in g_node_vector[node_list_no].m_outgoing_link_seq_no_vector) { link_weights_list[next_link] = link_likelihood[next_link]; link_label_list[next_link] = 1.0; } } else { //遍历至中间点时,计算相应label及label_sum信息。 float current_label = 1.0; for each (int pre_link in g_node_vector[node_list_no].m_incoming_link_seq_no_vector) { //遍历该点的入弧及前继结点。 if (link_likelihood[pre_link] > 0) { current_label = current_label * link_label_list[pre_link]; } } if (current_label == 1.0) { for each (int next_link in g_node_vector[node_list_no].m_outgoing_link_seq_no_vector) {//计算离开该店所有路段的权重值 float sum_w = 0.0; for each (int pre_link in g_node_vector[node_list_no].m_incoming_link_seq_no_vector) { sum_w += link_weights_list[pre_link]; } link_weights_list[next_link] = link_likelihood[next_link] * sum_w; link_label_list[next_link] = 1.0; } } }}第3步:从终点s开始按照s(i)上升的顺序,向后计算路段交通量。
for each (int node_list_no in s_index_list) { //按照s_index_list的顺序遍历 CNode node = g_node_vector[node_list_no]; if (node.node_seq_no == origin_node) //遇到起点时停止 break; if (node.node_seq_no == destination_node) { //遍历至终点时开始,初始化路段flow,label等信息,并在终点进行第一次分配。 float sum_w_pre = 0.0; for each (int pre_link in g_node_vector[node_list_no].m_incoming_link_seq_no_vector) { sum_w_pre += link_weights_list[pre_link]; } for each (int pre_link in g_node_vector[node_list_no].m_incoming_link_seq_no_vector) {//计算进入终点所有路段交通量 if (link_weights_list[pre_link] == 0) { link_flow_list[pre_link] = 0.0; link_label_list[pre_link] = 1.0; } else { link_flow_list[pre_link] = (link_weights_list[pre_link] / sum_w_pre) * demand_volume; link_label_list[pre_link] = 1.0; } } } else { //遍历至中间点时,累计流量和并分配流量。 float current_label = 1.0; float sum_flow = 0.0; for each (int next_link in g_node_vector[node_list_no].m_outgoing_link_seq_no_vector) { if (link_weights_list[next_link] > 0) { current_label = current_label * link_label_list[next_link]; sum_flow += link_flow_list[next_link]; } } if (current_label == 1.0) { float sum_w_pre = 0.0; for each (int pre_link in g_node_vector[node_list_no].m_incoming_link_seq_no_vector) { sum_w_pre += link_weights_list[pre_link]; } //计算路段权重和 for each (int pre_link in g_node_vector[node_list_no].m_incoming_link_seq_no_vector) {//计算进入该点所有路段交通量 if (link_weights_list[pre_link] == 0) { link_flow_list[pre_link] = 0.0; link_label_list[pre_link] = 1.0; } else { link_flow_list[pre_link] = (link_weights_list[pre_link] / sum_w_pre) * sum_flow; link_label_list[pre_link] = 1.0; } } } }}(4)程序运行结果
程序运行结果在result.csv中,包括每条link上的流量信息,字段如下图所示,进一步可以根据BPR函数计算相应的Travel Time,可自行尝试。
link_id | from_node_id | to_node_id | volume |
1 | 1 | 2 | 647.948 |
…… | |||
(5)大规模路网案例测试
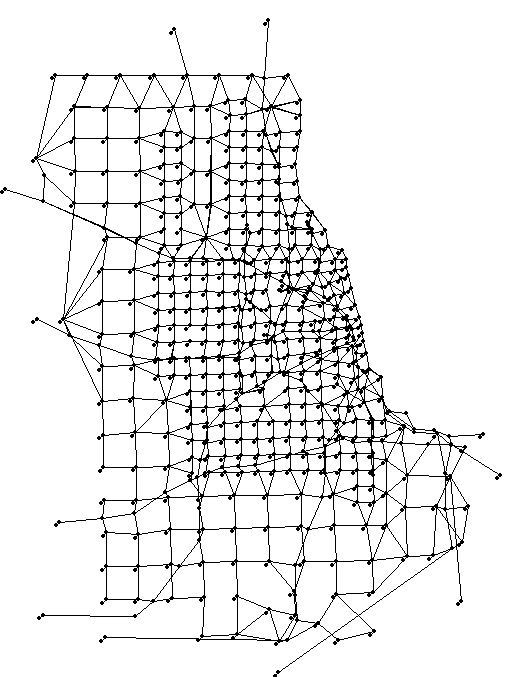
在较大网络Chicago测试中,node数量933,link数量2950,demand数量23210。网络拓扑结构如图所示:
在i5低压双核笔记本,x64 release模式下不同线程计算结果如下:

受限于本人编程水平及设备,代码效率仍有一定提升优化空间,欢迎大佬或有高性能计算机小伙伴修改与测试。
结束语
文中提到的源程序已上传至Github平台,网址:https://github.com/EntaiWang99/Learning-Network/tree/master/Dial_SUE。大家可以直接打开解决方案运行,注意需打开OpenMP功能,欢迎感兴趣的小伙伴讨论与交流。
参考
[1] 邵春福. 交通规划原理[M]. 中国铁道出版社, 2004.
[2] STALite: https://github.com/xzhou99/STALite
编辑:庄桢

“交通科研Lab”:分享学习点滴,期待科研交流!

如果觉得还不错
点这里!???















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









