





一、前言
在论文“Real-time Event Detection on Social Data Streams”中,作者首先在每一个时间窗口(分钟级)内利用社区发现算法(Louvain method)得到一个聚类 ,然后采用带权二分图最大匹配(maximum weighted bipartite matching)对 和上一时间窗口的聚类 进行聚类链接(Cluster Linking)。
We filter out any edges whose weight falls below a threshold and perform maximum weighted bipartite matching to find cluster links.
论文将节点之前的权重定义为: 与 各节点间共有的实体数目。
The edge weight between them is a measure of how many entities these clusters share, similar to the cosine similarity described earlier.

背景交代完,接下来我们就开始补充二分图匹配问题、匈牙利算法和KM算法的相关知识。
二、二分图匹配问题
所谓二分图(Bipartite Graph)就是这样一个图:
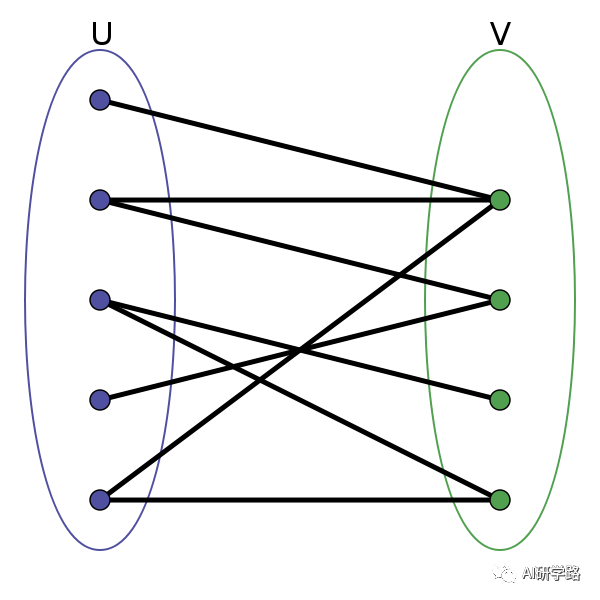
简单地说,就是一张图里的所有点可以分为两组(如上图),并且每条边都跨越两组。这样的图就是二分图。
1. 二分图的定义
说的严谨一点:
二分图又称双分图、二部图、偶图,指顶点可以分成两个不相交的集U和V(U和V皆为独立集(Independent Sets)),使得在同一个集内的顶点不相邻(没有共同边)的图。
一个图为二分图仅当:
没有奇数圈;
点色数为2;
2. 相关的几个概念


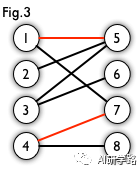
我们定义匹配点、匹配边、未匹配点、非匹配边。如图3,1、4、5、7为匹配点,其他顶点为未匹配点;1-5、4-7为匹配边、其他边为非匹配边。
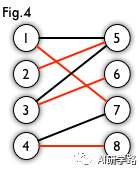
匹配(matching):二分图的一个“匹配”是指一些边的集合,任意两条边没有公共点。例如,图3、图4中红色的边就是图2的匹配。
最大匹配(maximum matching):二分图的“最大匹配”,值的是二分图的所有匹配中边数最多的匹配。图4是一个最大匹配。它包含4条匹配边。
完美匹配(perfect matching):二分图的一个“完美匹配”,是指所有点都在这个匹配中的一个匹配。也就是说这个匹配里的所有边刚好经过所有点一次。图4是一个完美匹配,显然,完美匹配一定是最大匹配(完美匹配的任何一个点都已经匹配,添加一条新的匹配边一定会与已有的匹配边冲突)。但并非每个图都存在完美匹配。
举例来说:如下图所示,如果在某一对男孩和女孩之前存在相连的边,就意味着他们彼此喜欢。是否可能让所有男孩和女孩两两配对,使得每对都互相喜欢?图论中,这就是完美匹配问题。如果换一个说法:最多有多少对互相喜欢的男孩/女孩可以配对?这就是最大匹配问题。

下面先讲匈牙利算法(Hungarian Algorithm),匈牙利算法用于求解无权二分图(unweighted bipartite graph)的最大匹配(maximum matching)和完美匹配(perfect matching)。
三、匈牙利算法
匈牙利算法是一种在多项式时间内求解任务分配问题的组合优化算法,并推动了后来的原始对偶方法。美国数学家哈罗德·库恩于1955年提出该算法。此算法之所以被称作匈牙利算法,是因为算法很大一部分是基于以前匈牙利数学家 Dénes Kőnig 和 Jenő Egerváry 的工作之上创建起来的。詹姆士·芒克勒斯在 1957 年回顾了该算法,并发现(强)多项式时间的。此后该算法被称为 Kuhn–Munkres 算法或 Munkres 分配算法。原始算法的时间复杂度为 ,但 Edmonds 与卡普发现可以修改算法达到 运行时间,富泽也独立发现了这一点。Ford 和 Fulkerson 将该方法推广到了一般运输问题。2006 年发现卡尔·雅可比在 19 世纪就解决了指派问题,该解法在他死后在 1890 年以拉丁文发表。
——Wikipedia
这段文字为我们讲述匈牙利算法的历史姻缘……
1. 相关的几个概念和定理
在讲匈牙利算法之前,先学习几个概念,这些概念都是为匈牙利算法服务的。
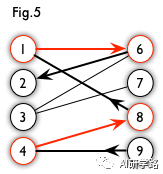
交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边…形成的路径叫交替路。
增广路:从一个未匹配点出发,走交替路,如果以另一个未匹配点(出发的点不算)为结尾,则这条交替路称为增广路(agumenting path)。例如,图 5 中的一条增广路如图 6 所示(图中的匹配点均用红色标出):
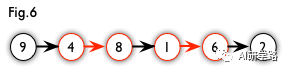
增广路有一个重要特点:非匹配边比匹配边多一条。因此,研究增广路的意义是改进匹配。只要把增广路中的匹配边和非匹配边的身份交换即可。由于中间的匹配节点不存在其他相连的匹配边,所以这样做不会破坏匹配的性质。交换后,图中的匹配边数目比原来多了 1 条。
我们可以通过不停地找增广路来增加匹配中的匹配边和匹配点。找不到增广路时,达到最大匹配(这是增广路定理)。匈牙利算法正是这么做的。
增广路定理:任意一个非最大匹配的匹配一定存在增广路。
匈牙利树一般由BFS构造(类似于BFS树)。从一个未匹配点出发运行BFS(唯一的限制是,必须走交替路),直到不能再扩展为止。例如,由图7,可以得到如图8的一棵 BFS 树:
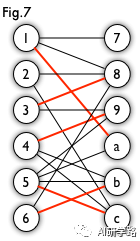
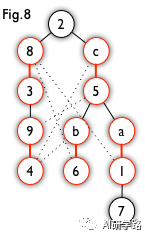
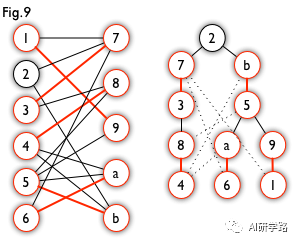
这棵树存在一个叶子节点为非匹配点(7 号),但是匈牙利树要求所有叶子节点均为匹配点,因此这不是一棵匈牙利树。如果原图中根本不含 7 号节点,那么从 2 号节点出发就会得到一棵匈牙利树。这种情况如图 9 所示(顺便说一句,图 8 中根节点 2 到非匹配叶子节点 7 显然是一条增广路,沿这条增广路扩充后将得到一个完美匹配)。
2. 算法基本原理
注意前面增广路的定义:“从一个未匹配点出发,走交替路,以另一个未匹配点为结尾”,首尾都是未匹配点,说明首尾的边都是非匹配边。而又是交替路,也就是说非匹配边比匹配边多一条。那么我们完全可以把这条增广路里的匹配边和非匹配边互换(称为“交换匹配”),那么匹配边就会多出 1 条,实现了“增广”的意义。并且这样做并不会对其他边造成影响,也不破坏二分图的性质。
那么我们就可以一直找增广路,不断交换匹配。根据增广路定理,如果找不到了,就说明已经达到最大匹配。
同样可以证明,已经匹配的点永远不会退出匹配,只会更换匹配。
这就是匈牙利算法最核心的部分了:一直找增广路,不断交换匹配。
可能看完上面的叙述,还是有点困惑。一直找增广路,不断交换匹配到底应该怎么做?以下我举一个便于理解例子:
现在Boys和Girls分别是两个点集,里面的点分别是男生和女生,边表示他们之间存在“暧昧关系”。最大匹配问题相当于,假如你是红娘,可以撮合任何一对有暧昧关系的男女,那么你最多能成全多少对情侣?(数学表述:在二分图中最多能找到多少条没有公共端点的边)
现在我们来看看匈牙利算法是怎么运作的:
我们从B1看起(男女平等,从女生这边看起也是可以的),他与G2有暧昧,那我们就先暂时把他与G2连接(注意这时只是你作为一个红娘在纸上构想,你没有真正行动,此时的安排都是暂时的)。

来看B2,B2也喜欢G2,这时G2已经“名花有主”了(虽然只是我们设想的),那怎么办呢?我们倒回去看G2目前被安排的男友,是B1,B1有没有别的选项呢?有,G4,G4还没有被安排,那我们就给B1安排上G4。
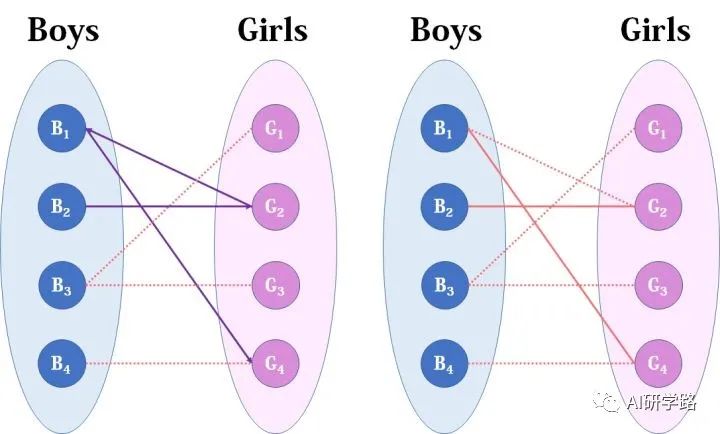
我们来细看这一过程:
开始是B1——G2;
由于B2的加入,有增广路G4——B1——G2——B2;
然后交换匹配,成为G4——B1——G2——B2;
这是不是正是前面提到的一直找增广路,不断交换匹配。
我们继续,B3直接配上G1就好了,这没什么问题。至于B4,他只钟情于G4,G4目前配的是B1。B1除了G4还可以选G2,但是呢,如果B1选了G2,G2的原配B2就没得选了。我们绕了一大圈,发现B4只能注定单身了,可怜。(其实从来没被考虑过的G3更可怜)
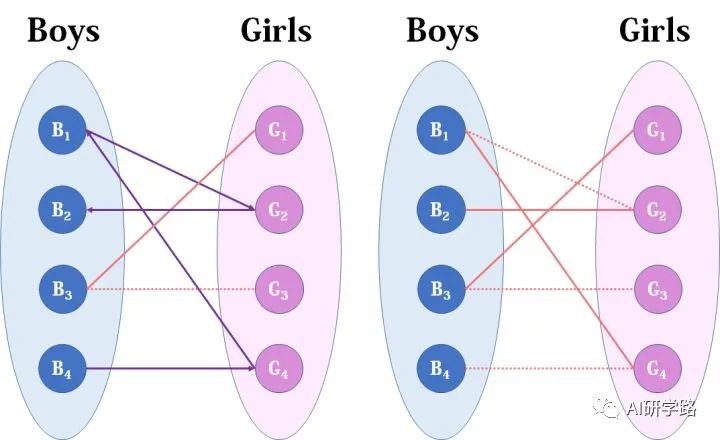
匈牙利算法的要点如下:
1)从左边第1个顶点开始,挑选未匹配点进行搜索,寻找增广路。
如果经过一个未匹配点,说明寻找成功。更新路径信息,匹配边数+1,停止搜索。
如果一直没有找到增广路,则不再从这个点开始搜索。事实上,此时搜索后会形成一棵匈牙利树。我们可以永久地把它从图中删去,而不影响结果。
2)由于找到增广路之后需要沿着路径更新匹配,所以我们需要一个结构来记录路径上的点。DFS版本通过函数隐式地使用一个栈,而BFS版本使用一个队列。
3. 匈牙利算法的应用
这一部分其实与所要叙述的目标相关性不大,不过开阔开阔思路总是好的。
一些题目,乍一看与上面这个男女配对的问题没有任何相似点,其实都可以用匈牙利算法。例如:
(洛谷P1129) [ZJOI2007]矩阵游戏
题目描述
小Q是一个非常聪明的孩子,除了国际象棋,他还很喜欢玩一个电脑益智游戏――矩阵游戏。矩阵游戏在一个 黑白方阵进行(如同国际象棋一般,只是颜色是随意的)。
每次可以对该矩阵进行两种操作:
行交换操作:选择矩阵的任意两行,交换这两行(即交换对应格子的颜色)
列交换操作:选择矩阵的任意两列,交换这两列(即交换对应格子的颜色)
游戏的目标,即通过若干次操作,使得方阵的主对角线(左上角到右下角的连线)上的格子均为黑色。
对于某些关卡,小Q百思不得其解,以致他开始怀疑这些关卡是不是根本就是无解的!于是小Q决定写一个程序来判断这些关卡是否有解。
输入格式
第一行包含一个整数T,表示数据的组数。
接下来包含T组数据,每组数据第一行为一个整数N,表示方阵的大小;
接下来N行为一个 的01矩阵(0表示白色,1表示黑色)。
输出格式
包含T行。对于每一组数据,如果该关卡有解,输出一行Yes;否则输出一行No。
我们把矩阵转化为二分图(左侧集合代表各行,右侧集合代表各列,某位置为1则该行和该列之间有边)。我们想进行一系列交换操作,使得X1连上Y1,X2连上Y2,……
大家可以想象,所谓的交换,是不是可以等价为重命名?我们可以在保持当前二分图结构不变的情况下,把右侧点的编号进行改变,这与交换的效果是一样的。

所以想让X1、X2...与Y1、Y2...一一对应,其实只需要原图最大匹配数为4就行了。(这与组合数学中相异代表系的概念相合)。实现代码及更多应用参见[1]
四、KM(Kuhn-Munkres)算法
好,前菜和头盘都上完了,现在我们来吃主菜,祝你有个好胃口!
1. 相关的几个概念和定理
完备匹配:定义 设G=为二部图,|V1|≤|V2|,M为G中一个最大匹配,且|M|=|V1|,则称M为V1到V2的完备匹配。也就是说把一个集合中的点全部匹配到另一个集合中。在上述定义中,若|V2|=|V1|,则完备匹配即为完美匹配,若|V1|最大匹配。
二分图最优匹配:对于二分图的每条边都有一个权(非负),要求一种完备匹配方案,使得所有匹配边的权和最大,记做最优完备匹配。(特殊的,当所有边的权为1时,就是最大完备匹配问题)
二分图带权匹配与最优匹配:什么是二分图的带权匹配?二分图的带权匹配就是求出一个匹配集合,使得集合中边的权值之和最大或最小,这个匹配集合比一定是完备匹配。而二分图的最优匹配则一定为完备匹配,在此基础上,才要求匹配的边权值之和最大或最小。二分图的带权匹配与最优匹配不等价,也不互相包含。
顶标:每个节点与另一个集合中节点之间的最大权值
可行顶标(标杆):对于原图中的任意一个结点,给定一个函数 求出节点的顶标值。我们用数组 记录集合 中的节点顶标值,用数组 记录集合 中的节点顶标值。并且,对于原图中任意一条边 ,都满足 。
相等子图:设 G(V,E) 为二部图, G'(V,E') 为二部图的子图。如果对于 G' 中的任何边 满足, ,我们称 G'(V,E') 为 G(V,E) 的等价子图或相等子图(是G的生成子图)。
以下是一些扩展的内容:
KM算法是求最大权完备匹配,如果要求最小权完备匹配怎么办?
方法很简单,只需将所有的边权值取其相反数,求最大权完备匹配,匹配的值再取相反数即可。
KM算法的运行要求是必须存在一个完备匹配,如果求一个最大权匹配(不一定完备)该如何办?
依然很简单,把不存在的边权值赋为0。
KM算法求得的最大权匹配是边权值和最大,如果我想要边权之积最大,又怎样转化?
还是不难办到,每条边权取自然对数,然后求最大和权匹配,求得的结果a再算出e^a就是最大积匹配。至于精度问题则没有更好的办法了。
2. 算法流程
这里有一篇比较好的男女找对象指南博客讲解了KM算法的执行过程,生动而又形象。主要理解过程中是怎么满足配对条件的,不满足后怎么办,过程中降低期望值d是怎么求得的,在配对失败期望值进行更改以后发生了那些变化,这些变化为新的一轮的匹配带来了什么?[2]
3. 算法原理
算法原理在[3]做了很好解释(好吧,是我写累了,还要去跑步),可以移步学习。
以上是KM算法的基本思想。但是朴素的实现方法,时间复杂度为 ——需要找 次增广路,每次增广最多需要修改 次顶标,每次修改顶标时由于要枚举边来求d值,复杂度为 。实际上KM算法的复杂度是可以做到 的。我们给每个Y顶点一个“松弛量”函数slack,每次开始找增广路时初始化为无穷大。在寻找增广路的过程中,检查边(x,y)时,如果它不在相等子图中,则让slack[y]变成原值与weight(x,y)-lx(x)-ly(y)的较小值(就是男生女生配对的求d的过程)。这样,在修改顶标时,取所有不在交错树中的Y顶点的slack值中的最小值作为d值即可。但还要注意一点:修改顶标后,要把所有的不在交错树中的Y顶点的slack值都减去d(对应就是未被访问的男生离女生更近了一步)。
以上就是全部内容,关于代码我会实现python版本的,在论文“Real-time Event Detection on Social Data Streams”论文笔记完成并复现完成后给出github地址,完结撒花。
引用:
[1] https://zhuanlan.zhihu.com/p/96229700
[2] https://www.cnblogs.com/wenruo/p/5264235.html
[3] https://blog.csdn.net/x_y_q_/article/details/51927054















 2197
2197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









