






为何讨论内存模型
随着CPU硬件的发展以及摩尔定律的终结,多核心多线程并行计算成为主流。然而编写出准确无误的多线程代码的难度比编写准确无误的单线程代码,要难的太多!其中一个重要的困难就来自内存系统,倘若读写内存的结果不可预期,那就更加谈不上程序的正确性了。
这种不确定性,主要来自以下几个方面:
- 编译器会为了优化,调整内存指令的执行顺序。在这个过程中,编译器只需要保证单线程条件下,编译后代码的执行结果和源代码序(Souce Code Order)一致即可。消除这种reordering可以用编译器提供的指令,例如MSVC的 _ReadWriteBarrier。
- CPU在执行机器码的时候,可能根据硬件环境调整内存指令的执行顺序,以优化内存带宽利用率。单线程条件下,这种顺序调整对代码运行结果无影响,但是多线程则无法保证。
- 即使指令先后顺序无误,也可能因为Cache的因素导致先到的指令更晚被执行。
最后一种情况我们可以用一个Cache的例子来说明。因为CPU频率的不断提高,内存访问延迟(Memory Access Latency)已经成为一个主要的性能制约因素,所以L1、L2、L3甚至L4各级缓存被开发了出来,同时Cache Line本身也被划分成bank,不同的bank可以独立地被访问。
假设两个并发的写操作A、B(时序上A在B之前), A被分配到bank0,B被分配到bank1,但是此时bank0正处于繁忙状态因此A操作被挂起,但B操作在bank1上被立即执行了,B的结果就会更早的被别的线程“看到”。对于读操作显然也可能存在这种情况。
有序一致(Sequential Consistency)
有序一致是处理内存操作顺序不确定性的一个抽象概念。你可以回想一下单核心CPU是如何做到处理多任务的,给每个任务一个时间片(Time Slice),时间一到就换下一个任务。
内存操作的有序一致性可以想象成类似的操作,因为同时只有一个线程操作内存系统(当然底层可能并非如此,只是从Programmer的角度“看起来是这样”),所有内存操作可以被严格的排序。显然对于我们推导程序的正确性来说,这是一个大杀器,大不了我们把所有可能的序都穷举一遍就好了。用Dekker算法(部分代码)为例,
int x = 0, y = 0, r1 = 0, r2 = 0;
void thread1()
{
x = 1; //A
r1 = y; //B
}
void thread2()
{
y = 1; //C
r2 = x; //D
}有序一致性保证,r1和r2至少有一个不为0。推导过程如下,
- 如果B先于D,因为A在B先,所以此时x=1已经被赋值,再执行D导致r2 = x = 1
- 如果D先于B,因为C在D先,所以此时y=1已经被赋值,再执行B导致r1 = y = 1
有序一致性是保证大多数同步算法在并行环境下能正确运行的必要条件。但是你肯定也能想的到,要做到这点必然会损失一部分性能作为代价。所以当今主流的CPU架构(x86、ARM等)都还没有做到有序一致性的,它们分别实现了不同程度上的一致性。这段代码展示了在x86环境,上述代码可能真的会得到r1 = r2 = 0的结果。
弱序内存模型(Weak-Ordering Memory Model)
现在抛开有序一致性假定,回到真实世界中来。坏消息是,不同平台实现的内存模型千差万别,内存操作的乱序可以用维基百科上的表来展示如下(表中“Y”字样代表可能的reordering)
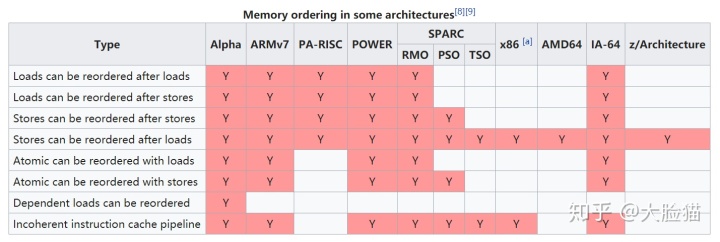
从这个表可以看到,x86是主流平台里内存模型最“严格”的,而在移动平台上主流的ARM架构下,几乎所有的内存操作都有可能被乱序执行。所以,很可能你写的多线程代码,在x86下可以正确运行,但是在ARM上会遇到问题。
不过,弱序内存模型也并非完全意义上的无序,有几个断言在所有情况下都是成立的,
- 同一个CPU上运行的线程,它们看到的内存操作的顺序永远是一致的(和代码序相同),reordering只存在于不同CPU线程之间。
- 乱序只发生在对不同内存地址(memory location)的操作之间,对于同一个地址/变量,始终保持有序一致性。
- 内存对齐的简单对象,其读写都是原子操作。
举一个大家工作中肯定遇到过的例子(比如游戏引擎里的streaming系统),
int data[5] = {9,9,9,9,9};
bool is_ready = false;
//on thread 1
void init_data()
{
for (int i = 0;i < 5; ++i)
{
data[i] = i;
}
is_ready = true;
}
//on thread 2
void sum_data()
{
if (!is_ready) return;
int sum = 0;
for (int i = 0;i < 5; ++i)
{
sum += data[i];
}
printf("%d",sum);
}在多CPU弱序内存模型环境中,init_data函数指令执行的顺序可能是这样的(is_ready在数据还没填充好的时候就被标记)
store data[3] 3
store data[4] 4
store is_ready true
store data[0] 0
store data[1] 1
store data[2] 2同样的,在读线程,sum_data读取的顺序也有可能是这样的(读取了较早前的错误数据)
load data[3]
load data[4]
load is_ready
load data[0]
load data[1]
load data[2]为解决内存操作乱序的问题,各个平台都提供了用来同步内存操作的同步指令,操作系统(Windows或者Linux)在这个基础上提供API用来生成同步指令的代码。
比如Linux下给上面的例子添加内存同步机制
int data[5] = {9,9,9,9,9};
bool is_ready = false;
//on thread 1
void init_data()
{
for (int i = 0;i < 5; ++i)
{
data[i] = i;
}
smp_wmb(); //fence前后的写内存操作不会被乱序
is_ready = true;
}
//on thread 2
void sum_data()
{
if (!is_ready) return;
smp_rmb(); //fence前后的读内存操作不会被乱序
int sum = 0;
for (int i = 0;i < 5; ++i)
{
sum += data[i];
}
printf("%d",sum);
}到这里我们就可以看到了,正确的多线程编程实际上是非常困难的。假如你的代码还需要跨平台的话,就需要注意更多的内存操作顺序问题,需要了解各个平台的不同,以及对应的内存同步指令。如果使用的编程语言不支持直接使用底层平台的内存同步指令,还有可能不得不使用Lock方案。这里其实就引出了C++ Memory Model提出的重要意义了。
C++标准内存模型
众所周知近些年来C++标准可谓是日新月异,随着C++0x, C++11, C++14, C++17, C++20等一系列标准的制定,很多牛逼的功能以跨平台的方式被加入了进来。其中C++11引入的原子对象类型和标准内存模型,对于我们写出正确的跨平台多线程代码至关重要。
C++原子类型
因为本文主要阐述的是标准内存模型,所以对C++11引入的各种原子对象类型不再赘述,详细可参考cppreference。
C++原子类型的主要贡献有两点:
- 提供一个读写改均为原子的标准模板类型,对同一个原子对象的多线程读写遵循有序一致性原则。
- 对原子对象的访问可以建立线程间同步,并且可以在多线程环境下对非原子内存操作定序。
标准原子类型提供的读写函数(比如std::atomic_int::load),均提供一个memory_order的参数,用来提供内存操作的语义。这个参数可以是
- std::memory_order::memory_order_seq_cst 标记该内存操作为有序一致性语义,也即保持最强的内存一致性
- std::memory_order::memory_order_release 标记该内存操作为release/store语义
- std::memory_order::memory_order_acquire 标记该内存操作为acquire/load语义
- std::memory_order::memory_order_acq_rel 标记该内存操作为acquire+release语义,一般用于read-modify-write原子操作,比如fetch_add方法
- std::memory_order::memory_order_relaxed 标记该内存操作为relaxed语义,仅仅保证原子操作性,不保证任何一致性
C++原子类型的所有方法均提供了memory_order_seq_cst的默认值(包括自定义操作符)。
Synchronize-with
那么原子类型操作的参数和我们讨论的内存模型有什么关系呢?原因就在于如果对位于不同线程上的两个原子操作打上恰当的memory_order标记,在它们之间就可以建立一个同步关系(Synchronize-with),利用这个关系就可以给位于不同线程上的内存操作(无论这个操作是否具有原子性)定序。
用C++原子类型重写streaming的例子,
int data[5] = {9,9,9,9,9};
std::atomic<bool> is_ready(false); //用来做定序的原子对象
//on thread 1
void init_data()
{
for (int i = 0;i < 5; ++i)
{
data[i] = i;
}
//release语义,也可以是更加严格的memory_order_seq_cst
is_ready.store(true, std::memory_order::memory_order_release);
}
//on thread 2
void sum_data()
{
//acquire语义,也可以是更加严格的memory_order_seq_cst
if (!is_ready.load(std::memory_order::memory_order_acquire)) return;
int sum = 0;
for (int i = 0;i < 5; ++i)
{
sum += data[i];
}
std::cout << sum;
}
init_data中原子对象is_ready的store操作被标记为release语义,同时sum_data里is_ready的load操作被标记为acquire语义,所以当sum_data读到is_ready=true的时候,这两个操作之间就建立了一个同步关系(Synchronize-with relationship)。这个关系,又进一步为relase之前以及acquire之后的非原子内存操作,确定了顺序,从而保证了在sum_data进行求和的时候,确切的看到了init_data存储的所有数组元素。
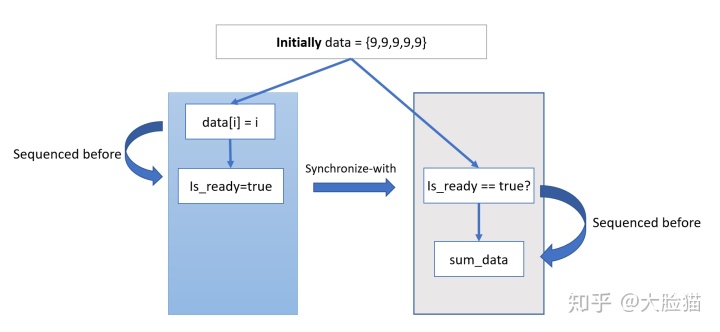
上图中箭头的顺序说明了这种定序是如何产生的,相同线程上的排序(Sequenced-before)加上原子对象的同步关系(Synchronize-with),我们就给不同线程上的非原子内存操作确定了顺序。
当然C++11也提供了fence,release-sequence等概念可以用来做内存操作的定序,这些更深入的内容可以参考Anthony Williams的C++ Concurrency in Action。
总结
- 多线程编程中内存操作可能因为编译器或者CPU架构的不同,产生乱序(Reordering),从而让让我们的代码不能按照设计的意图执行。
- 编译器提供了Memory Barrier指令,防止编译阶段乱序的发生。
- 有序一致性(Sequential Consistency)是最严格的内存同步模型,所有的内存操作有全局的排序,但代价是性能的损失。
- 所有主流的CPU架构均未实现有序一致性模型,它们用不同的内存模型提供了不同程度上的一致性。x86架构是其中“最严格”的一个,只有Store-Load Reordering可能发生。
- 操作系统(Windows/Linux)提供了Memory Barrier指令,可以防止代码执行阶段产生的乱序。
- C++11引入原子类型、内存模型,提供了内存乱序问题的最佳跨平台解决方案。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









