






前言
相信大家早已熟读作为国产科幻巅峰的优秀小说《三体》,徜徉在大刘衍生的宇宙观并折服于这个魔鬼的脑洞之中。然而回归小说这一体裁的本质,鲜活人物仍然是小说的灵魂,巨著《三体》中的人物塑造也是令人印象深刻。用python语言简单解密一个科幻小说,可谓在本质上是同根同源,用理性工具分析感性创作更是期待火花四溅……
1
jieba分析语言特色
思路如下:
首先,需要通过最简单的jieba分词得到《三体》整体的语言特色,并尝试初步整理出主要任务。这种方法主要只使用jieba库并且需要再三试验剔除明显多余的常用词,费时费力。(这是第四次排查之后的代码)
import jiebaimport os, sysimport jieba, codecs, mathimport jieba.posseg as pseg#3.txt= txt.load_txt()os.chdir(r'C:\Users\Administrator\Desktop')def get_text(): f = open('三体.txt','r',encoding='utf-8').read() words = jieba.lcut(f) return wordswords = get_text()counts = {}dy= ['一个','没有','这个','可能','什么','知道','我们', '他们','看到','已经','现在','自己','可以','就是','这样','不是','你们', '那个','这种','只是','如果','出现','这里','开始','最后','一样','两个','起来', '东西','只有','发现','这些','这是','还是','它们']for i in words: if len(i)==1: continue else: counts[i] = counts.get(i,0)+1print(counts)for i in dy: del (counts[i])ls = list(counts.items())ls.sort(key= lambda x:x[1],reverse=True)print(ls)for i in ls[:20]: print(i)之后结果如下:

然而,这种分析除了提示本书关键人物是程心、罗辑、汪淼和叶文洁外,并不能很全面的找到人物关系。
2
生成人物关系
第二次我受另一篇文章启发采取了用对应实体的方式直接对应人物然后生成人物关系。
1.使用jieba库 对《三体》进行关系实体。这里的实体指的是人物
2 出现实体之间的关系:判断是否有关系,通过一句话里面是否有这两个实体。如果一句话里面包含这两个实体,可以认为他们是存在关系的。(但也可能并不存在,只是存在关系的可能性很大)
3.输出关系
#参照文章‘Python 自然语言处理 入门——提取《釜山行》的人物关系’https://www.jianshu.com/p/8fc86ba6222d第二次代码如下:import os, sysimport jieba, codecs, mathimport jieba.posseg as pseg#3.txt= txt.load_txt()os.chdir(r'C:\Users\Administrator\Desktop')names = {} # 姓名字典relationships = {} # 关系字典#limenames 记录的是每一行出现的名字, 也就是说,只有出现在用一行的名字才认为是有关系的lineNames = [] # 每段内人物关系# count namesjieba.load_userdict("dict.txt") # 加载字典with codecs.open("三体.txt", "r", "utf8") as f: for line in f.readlines(): #按行输出文件 #print line #poss 包含两个key,一个是word,一个是flag """ words=pseg.cut("我爱北京天安门") for word ,flag in words: print ('%s %s' %(word,flag)) 输出的格式是: 我 r 爱 v 北京 ns 天安门 ns """ poss = pseg.cut(line) # 分词并返回该词词性 #给list添加一个为空的list lineNames.append([]) # 为新读入的一段添加人物名称列表 for w in poss: if w.flag != "nr" or len(w.word) < 2: continue # 当分词长度小于2或该词词性不为nr时认为该词不为人名 #[-1]表示最后一个元素 #limenames 记录的是每一行出现的名字, 也就是说,只有出现在用一行的名字才认为是有关系的 lineNames[-1].append(w.word) # 为当前段的环境增加一个人物 if names.get(w.word) is None: names[w.word] = 0 relationships[w.word] = {} names[w.word] += 1 # 该人物出现次数加 1# explore relationshipsfor line in lineNames: # 对于每一段 for name1 in line: for name2 in line: # 每段中的任意两个人 if name1 == name2: continue #如果名字1 和名字2 不相同的话 #也就是说,关系的抽取是基于 这一行有没有出现这两个名字 if relationships[name1].get(name2) is None: # 若两人尚未同时出现则新建项 relationships[name1][name2]= 1 else: relationships[name1][name2] = relationships[name1][name2]+ 1 # 两人共同出现次数加 1# outputwith codecs.open("三体_node.txt", "w", "utf-8") as f: f.write("Id Label Weight\r\n") for name, times in names.items(): f.write(name + " " + name + " " + str(times) + "\r\n")with codecs.open("三体_edge.txt", "w", "gbk") as f: f.write("Source Target Weight\r\n") for name, edges in relationships.items(): for v, w in edges.items(): if w > 3: f.write(name + " " + v + " " + str(w) + "\r\n")但是分析的结果却非常诡异(下面截取一部分)……只能辅助证明《三体》小说空间时间的跳跃度(就是特大的脑洞),对人物关系帮助不大。分析词性对应实体的方式似乎适用于人物活动集中的剧本而不适用于小说。

3
简单分析小说
最后我降低了对人物分析的要求,只希望python能简单分析小说,于是定了新的目标:
1)通过出现频率提取主要人物 2)作图式形成关联 3)简单分析特定人物关系
对于这种分析需要我提前准备好人物名单,于是在豆瓣上整合了三部曲中热心网友一个一个数出来的出场人物做成‘人名.txt’,部分如下

之后就可以用jieba和genism库进行简单分析了
代码如下
#参考文章‘利用Python简单品读小说’https://www.w3cschool.cn/python3/python3ilvp2z1w.# Python简单分析三体import gensimimport jiebaimport scipyimport numpy as npimport matplotlib.pyplot as pltimport scipy.cluster.hierarchy as hierarchyfrom matplotlib.font_manager import FontPropertiesfrom snownlp import SnowNLPimport osos.chdir(r'C:\Users\Administrator\Desktop')class easy_analysis(): def __init__(self): print('[FUNCTION]:THREE BODY Analysis...') print('[Author]:RECO') # 词向量训练 def training(self, text): with open(text, encoding='utf-8') as f: data = [line.strip() for line in f.readlines() if line.strip()] sentences = [] for d in data: words = list(jieba.cut(d)) sentences.append(words) model = gensim.models.Word2Vec(sentences, size=100, window=5, min_count=5, workers=4) return model # 给jieba添加关键词 def add_key_words(self, words): for word in words: jieba.add_word(word) # 获得需要添加的关键词 def get_key_words(self, text): with open(text, encoding='utf-8') as f: words = [line.strip('\n') for line in f.readlines()] return words # 返回d,a与b的关系和c与d的关系一样 def get_relation(self, model, a, b, c): d, _ = model.most_similar(positive=[c, b], negative=[a])[0] print('{}和{}的关系类似于{}和{}的关系'.format(a, b, c, d)) # 找主要人物 def find_main_characters(self, text1, text2, num=10, title='Untitled'): with open(text1, encoding='utf-8') as f: text = f.read() with open(text2, encoding='utf-8') as f: character_names = [line.strip('\n') for line in f.readlines()] count = [] for name in character_names: count.append([name, text.count(name)]) count.sort(key=lambda x: x[1]) _, ax = plt.subplots() frequency = [x[1] for x in count[-num:]] names = [x[0] for x in count[-num:]] ax.barh(range(num), frequency, color='skyblue',) font = FontProperties(fname="jt.ttf") ax.set_title(title, fontproperties=font) ax.set_yticks(range(num)) ax.set_yticklabels(names, fontproperties=font) plt.show() # 层级聚类 def hierarchy_(self, model, character_names): exist_names = [] word_vectors = None for name in character_names: if name in model: exist_names.append(name) for name in exist_names: if word_vectors is None: word_vectors = model[name] else: word_vectors = np.vstack((word_vectors, model[name])) np_names = np.array(exist_names) font = FontProperties(fname="jt.ttf") Y = hierarchy.linkage(word_vectors, method='ward') _, ax = plt.subplots(figsize=(10, 40)) Z = hierarchy.dendrogram(Y, orientation='right') index = Z['leaves'] ax.set_xticks([]) ax.set_yticklabels(np_names[index], fontproperties=font, fontsize=14) ax.set_frame_on(False) plt.savefig('results.jpg') # plt.show()if __name__ == '__main__': ea = easy_analysis() ea.find_main_characters(text1='三体.txt', text2='人名.txt', title='三体') ea.add_key_words(ea.get_key_words('人名.txt')) model = ea.training('三体.txt') model.save('model') model = gensim.models.Word2Vec.load('./model') ea.get_relation(model, '程心', '罗辑', '叶文洁') ea.hierarchy_(model, ea.get_key_words('人名.txt')) ea.Get_Emotion('人名.txt')之后主要人物词频非常清晰,也验证了第一种方式的正确性,汪淼、罗辑和程心作为一、二、三部曲的主人公和亲历者排在了最前,而刚好颠倒的排名更体现了三部曲的实质影响力,一只是序曲,二是揭露,三是真实世界的打开。这几位主要人物都是剧情推动者,是科幻小说在宏观场面描写之外文学价值的传递载体,展现了大刘人文方面的思考。
(所以程心和罗辑就是名副其实的三体男女主角?真好,庄颜就是我的了。。。)

然后是所有任务杂冗的关系图:


黄字部分是自选关系形成,我试验三次,结果分别如下:

???我的cp果然不行

好…好基友?
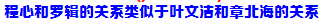
极端人格?
4
总结
整体来说这种简单关系分析还是不太准确,但能提供一定的思路,解密作者在科幻作品中看似不走心的人物塑造(我一辈子都会记得艾AA这简单粗暴的名字)实则体现了不同世界观的相互补充与混杂。
本期作者:孔盈颖
本期编辑校对:秦范
长按,关注数据皮皮侠
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









