





是一个计算机科学概念用于使用单个字符串来描述,匹配某个规则的字符串常常用来检索,替换某些模式的文本
正则的写法
- .(点号):表示任意一个字符,除了
- [](中括号),匹配括号中列举的范围,如[0-9]代表任意单个字数,[a-z]代表任意单个小写字母
- d: 任意一个数字
- D:除了数字都可以
- s:表空格,tab键
- S:除了空格,tab键之外
- w:单词字符,a-z,A-Z,0-9,_
- W:除了字母和数字
- *:表示前面的内容重复零次或者多次
- +:表面前面内容至少出现一次
- ?:表面前面的内容出现一次或者零次
- {m, n} :出现m到n次
- ^ :匹配字符串的开头
- $:匹配字符串的结尾
- ():对正则表达式的内容进行分组,从第一个括号开始
- A:匹配字符串开始
- Z:匹配字符串末尾
- |:左右任意一个
使用大致步骤
- 使用compile将表示正则的字符串编译为一个pattern对象
- 利用Pattern对象提供的方法,对文本进行匹配,获取匹配结果
- 最后利用match对象提供的属性和方法后去信息,根据需要进行操作
常用匹配方法
match匹配
- 必须从第一个字符开始就能匹配上,否则匹配失败
- 返回的结果只有一个,并且支持group分组
import retext = '1234aash34235235fdosdf'p = re.compile('[0-9]*')result = p.match(text)print(result)print(result.group())print(result.span())"""输出结果1234(0, 4)"""返回结构体re.Match
- span:表示匹配的跨度,从哪里匹配,到哪里结束,左包括右边不包括
- group:表示匹配的组,如果只有一组则直接打印内容
- start:显示开始匹配的字符串的位置
- end:表示结束字符串的位置
- groups:当正则里面出现括号时搭配使用
import retext = '1234aash34235235fdosdf'p = re.compile('([0-9]*)') # 这里多了一个括号result = p.match(text)print(result)print(result.group())print(result.groups())print(result.span())"""1234('1234',)(0, 4)"""search匹配
- 与match基本一致,也只返回一个结果
- 但是可以不用从开头位置匹配
- 返回一个结果,支持group分组
import retext = 'a1234aash34235235fdosdf'p = re.compile('[0-9]+')result = p.search(text)print(result)print(result.group())"""1234"""findall匹配
- 匹配所有能匹配到的结果
- 不支持group分组,默认返回一个列表
import retext = 'a1234aash34235235fdosdf'p = re.compile('[0-9]+')result = p.findall(text)print(result)"""['1234', '34235235']"""finditer匹配
- 匹配所有能匹配到的结果
- 默认返回一个迭代,由re.Match迭代而成,可以通过for循环取出
- re.Match支持group分组
import retext = 'a1234aash34235235fdosdf'p = re.compile('[0-9]+')result = p.finditer(text)print(result)for r in result: print(r) print(r.group())"""123434235235"""sub替换
- 可以用sub替换要匹配的字符
- sub为批量替换,即可以替换多个位置
import retext = 'a1234aash34235235fdosdf'p = re.compile('[0-9]+')result = p.sub('0', text) # 把结果全部替换为0print(result)"""a0aash0fdosdf"""group与groups的区别
- group与groups都属于re.Match的内置属性
- group用于直接显示匹配结果,而groups用于提取匹配结果中的值
- 以提取百度网页title为例
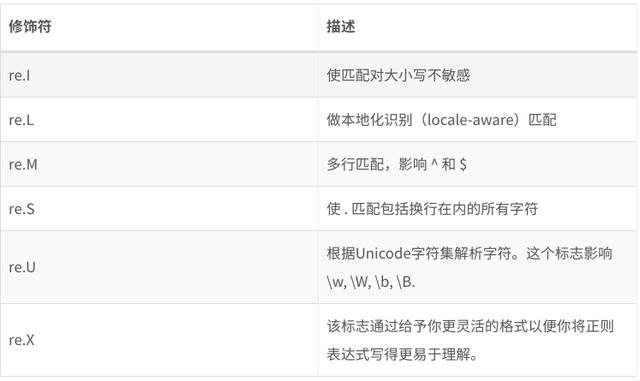
import reimport requestsurl = 'https://www.baidu.com'headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}response = requests.get(url, headers=headers)html = response.textp = re.compile('(.*?)') # 提取title中间的值result = p.search(html)print(result.group())print(result.groups())"""百度一下,你就知道('百度一下,你就知道',)"""import retext = '2020-04-05'p = re.compile('([0-9]{4})-([0-9]{2})') # 这里分了两个组,一组提取年份,一组提取月份result = p.search(text)print(result)print(result.group()) # 打印匹配值print(result.groups()) # 打印匹配结果,返回一个tupleprint(result.group(0)) # 打印所有组,和group()一样print(result.group(1)) # 打印第一组的匹配值print(result.group(2)) # 打印第二组的匹配值print(result.groups(0)) # 打印所有匹配结果,和groups一样的import reimport requestsurl = 'https://www.baidu.com'headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}response = requests.get(url, headers=headers)html = response.textp = re.compile('(.*?)') # 提取title中间的值result = p.search(html)print(result.group())print(result.group(1)) # 把第1组的结果打印出来print(result.groups())"""百度一下,你就知道百度一下,你就知道('百度一下,你就知道',)"""正则表达式修饰符
re.I演示
假设想要匹配所有字母,不区分大小写
import retext1 = 'shdfi1234SHDFISHDI'p = re.compile('[a-z]+', re.I) # 不区分大小写,所有字母都匹配result = p.findall(text1)print(result)"""['shdfi', 'SHDFISHDI']"""re.M演示
- 假设匹配以sh开头以2结尾的字符串
import retext1 = 'sh22dfi1234SHDFIssSHDI'p = re.compile('^sh.*2$', re.M) # 匹配多行,即忽略回车匹配所有小写字母p2 = re.compile('^sh.*2$')result = p.findall(text1)result2 = p2.findall(text1)print(result)print(result2)"""['sh22dfi12'][]"""re.S演示
- 假设匹配一个d..I的字符串
import retext1 = 'sh22dfi1234SHDFIssSHDI'p1 = re.compile('d.*I')p2 = re.compile('d.*I', re.S) # 让点号也能匹配换行符result1 = p1.search(text1)result2 = p2.search(text1)print(result1) # 目前没有匹配上print(result2.group()) # 从下面的结果来看换行符也被匹配上了"""Nonedfi1234SHDFIssSHDI"""匹配中文
- 匹配中文[一-龥],不包括全角标点
贪婪匹配与非贪婪匹配
. *和.*?
import retext = '12ddd345'# 匹配一个数字开头数字结尾的字符串p1 = re.compile('[0-9].*[0-9]') # 贪婪模式p2 = re.compile('[0-9].*?[0-9]') # 非贪婪模式result1 = p1.search(text)result2 = p2.search(text)print(result1.group())print(result2.group())"""12ddd34512"""- 正则表达式默认使用贪婪匹配
import retext = u'123你好bbabd'p1 = re.compile(u'[一-龥]{1,2}') # 匹配一个或者两个中文result1 = p1.search(text)print(result1.group()) # 打印结果是匹配两个"""你好"""- 如果使用非贪婪匹配
import retext = u'123你好bbabd'p1 = re.compile(u'[一-龥].*?') # 匹配一个或者两个中文result1 = p1.search(text)print(result1.group()) # 打印结果是匹配一个"""你"""














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









