





http://arxiv.org/abs/1606.03657
这篇论文理论部分较少,但是实验部分相比较多。(篇幅较长)
InfoGAN的发布时间应该在是DCGAN之后没多久,可以算是在大部分的GAN模型的前面的。从算法分类上看,InfoGAN属于半监督模型,但是不同于一般的半监督模型,比如,SemiGAN,CatGAN, ImprovedGAN,ACGAN等。后面的这些模型添加半监督的思路,主要是想要将GAN中D扩张为一个可以分类图像label,而不是单纯的分是否是bogus data(即,是否来自于G)。
Semi-GAN:D输出变成K+1。(1为原来的fake or not的判断, K为分类器的目标分类类数)
CatGAN:D的输出变成K。结合信息熵,认为概率在每个类上越接近等概率,表示data来自于G。当然,越是集中在某个类别上,这样就可以描述具体的类别了。
ImprovedGAN:D的输出变成K。做两层的softmax。一层是在D上做,这里只是将D当做一个分类器来看待。之后,再假设有还有一个类别,即fake,K+1。由于其他K个类别数字都在变,因此假设最后一个类别数值固定也可以再加一层softmax完成。
ACGAN:将D分解,D的卷积层作为特征挖掘的层(一般也是这么认为的)。之后,对于这样的特征再做不同的映射。一个将特征映射到K上(分类器), 一个是将特征映射到0/1上(判别器)。(判别器本质上也是分类器,这里主要是为了区别说明)
时间上看,InfoGAN应该是在Semi-GAN和Cat-GAN之后提出,在ImprovedGAN和ACGAN之前提出。
点击访问CatGAN
点击访问ImprovedGAN
点击访问ACGAN
但是,会注意到,其实,无论怎么改,大家在半监督的GAN上的挖掘都是停留在D上。而忽视了G(当然也是G上不太好做文章的原因)。
一般来说,G的输入只有z 。GAN的训练方式,是将一个随机变量,通过博弈的方式,让z在G上具有意义。也就是使得没有特定信息的变量z,在通过G的映射之后,变得具有某种含义。这种含义使得z的变化会影响到G的生成效果。
InfoGAN的操作,就是尝试添加其他的输入,使得这参数也具有意义。
很自然的,就会想到,添加一组有贴有特定标签的数据,然后,再拿来训练,之后就会得到这样的结果。但是这样的操作,其实本质上只是在将z扩张一个大小而已,相比于GAN本身并没有太大的区别。
但是InfoGAN的操作,并不这样。InfoGAN尝试结合半监督的特征学习方式来完成这一点。
先简单讲讲特征学习:
特征,可以说是机器学习中极其重要的一点。不同的特征描述可以对于数据处理,带来完全不同的处理难度。
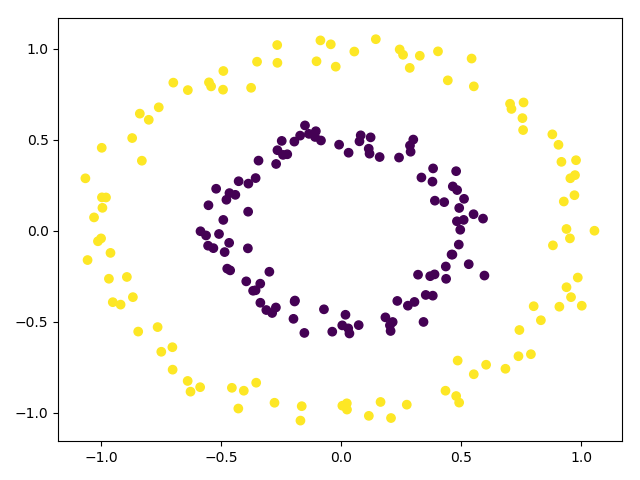
比如关于下面这种数据,就无法用一个线性分类来分类。但是转换成极坐标之后,就会发现,黄色的点,距离圆心普遍较远,因此极坐标的R相对于紫色的都较大。因此关于R做线性分割即可完成分类。
深度学习,本质上是想要用更深层的映射,来挖掘更多细节信息而构成新的特征,用于进一步的处理。
特征学习,就是通过一些方法,找到对于一个数据的较好的特征描述。(怎么定义较好,就看特定需求了。)
有监督(或者是半监督)特征学习,就是结合一些label来尝试提出更好的特征描述(比较常见);
无监督特征学习,就是结合一些不需要label的描述优劣的标准(内部聚合什么之类),尝试提出较好的特征描述。
回到InfoGAN
InfoGAN,在借助互信息的概念,将GAN和特征学习结合,使得在不需要借助对应的信息下,就可以完成对于特定的特征描述和控制。
比如说,在不需要对于数据进行标注(是否倾斜)的情况下,有控制的生成倾斜程度不同的MNIST数字。
这在数据标注不够的情况下,可以有条件的控制成有特定倾向的数据,我觉得这项研究对于GAN的应用上,拔高了好几个量级。
GAN的一个重要作用就是在数据集不足的情况下,学习特征,从而扩张数据集。
但是,InfoGAN的操作,使得GAN能将无标注的数据集,学习成有标注的数据集。(秀不秀?)
当然实验下,误差也是有的,但是还是值得称赞。
InfoGAN理论部分
阐明:InfoGAN,尝试添加某些特定的参数c,来学习模型中隐含的特征(使用模型的人也不知道有什么隐含特征,但计算机能看出来,并在最后的结果中展示)。
也就是在添加某个参数c后,是的模型的信息熵减少。(信息熵表示信息量大小,信息熵减少意味着,给出的参数或者条件将某种特征表现了出来)
比如说,MNIST数据集,整个数据集的信息熵为H1;如果我给定了特定数字,例如0,那么在0这个数据集上的信息熵毫无疑问是比H1要小的(至少这个数据集多了0这个特征,所以信息熵减少)。
而添加了某个参数,信息熵减少,衡量这个量不就是互信息嘛?
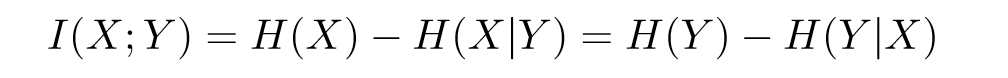
对于G来说,我们需要保证,在添加了参数c之后,G对应的信息熵减少,也就是相对应的互信息增加。所以目标函数可以简化为:
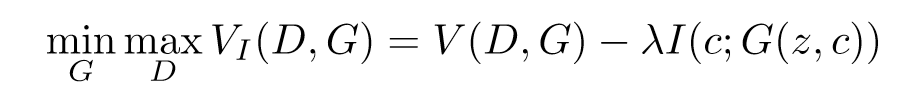
λ只是一个超参数,一般取1,略过。
但是由于互信息是不好算的,因此常用其他的方式来计算代替这个步骤(这个步骤的合理性,由 Variational Information Maximization 保证),公式如下:
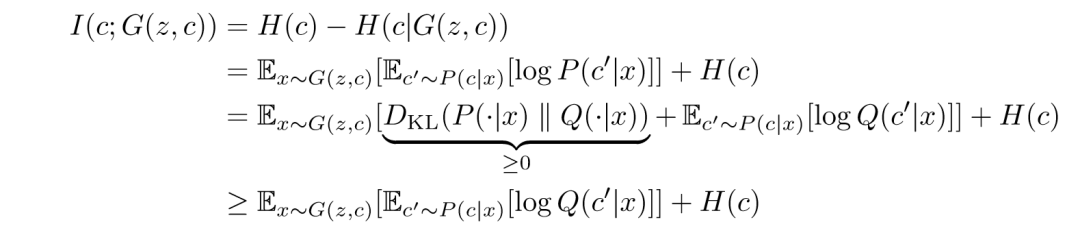
这样我们之后算互信息的时候用较为方便方式计算就好了,这里VIM保证了,其他的计算方式相较会是下限。
之后,为了简单,这篇论文保证c自己的分布是均匀分布,这样H(c)就变成了常数,优化的过程就只用看前面的,计算Q(c|x)就好了。
而且,为了方便,或者加快迭代,甚至连log都可以去掉(这样是实际中使用常用的。但是这么用了之后,就不能和原来的D,G的损失放在一起了,公式变了嘛,虽然等价但是公式毕竟还是不同)
这样,我们就可以用较为方便的方式来衡量添加了参数后的图片的判别效果即可。
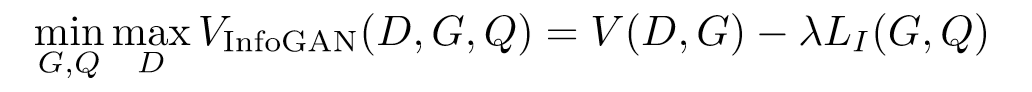
MNIST常用参数设计:
c1(长度为10),用来控制输出具体是哪个类别(有监督)
c2,c3,挖掘隐含信息(并用c2,c3来控制隐含信息)(无监督)。
c1的计算Q(c|x),很明显就是分类器常用的交叉熵
c2,c3,为了挖掘隐含信息,只需要保证和初始的输入一致即可,用MSE。
保持一致为什么可以保证获取隐含信息:
输入的信息c2,c3,在融入到G生成图片中,体现为图片的某些特征。
当且仅当图片中存在着有规律的c2,c3通过G映射出来的特征时,才能保证被D的特征挖掘的时候被获取到。因此如果能保证前后一致的话,那么说明c2,c3可以控制在G生成的图片表现出某种特征。
理论部分结束,看个广告,让我恰下饭~
实验
InfoGAN论文中给出了MNIST相关的D,G架构,但是我试了下,发现效果不太行,没我之前设计的那个好用(不亏是我)。
有必要说明,c只输入给了G,而没有给D,因此,在最终计算的时候,是通过了D映射的产物。这时候,c已经被映射多次。如果是挖掘隐含信息就没有问题,但是很有可能到只输入的c和输出的数字不统一(但是这是正确的,同一输入只能保证输出的图片在细节上统一。但是对于输入label来控制输出是具体哪一类可能会出现误差。)
比如
1->G->图片数字2->D->1(10个变量,其中在1对应的概率数值较高)
这种情况,是存在的(把2认作1)。
因为D本质上是在挖掘图片细节,所以最终的结果是有限考虑到在细节上的统一性。而不是label的统一性。这也是为什么为了控制输出必须要在D上也给label作为输入(比如CGAN和ImprovedGAN)。
这里总共有12个参数c。
前10个为label的one-hot编码,称之为c1。
后面两个为隐藏的因子(尝试学习隐含的因子, 输入之前,我也不知道可能学会控制啥,看缘分吧emmm),分别为c2,c3。这两个用[-1, 1]上的均匀分布。
关于c1的试验结果:
同一行的,都是同一个one-hot编码的信息给G的。存在误差的原因上面给出解释了。

关于c2的试验结果:
下面不同图之间是由于c1取了不同的one-hot编码;
同一张图的不同小图,从左往右,从上往下,递进,是c2从-1到1均匀递进。
从输出来看,可能学习到的是倾斜程度。










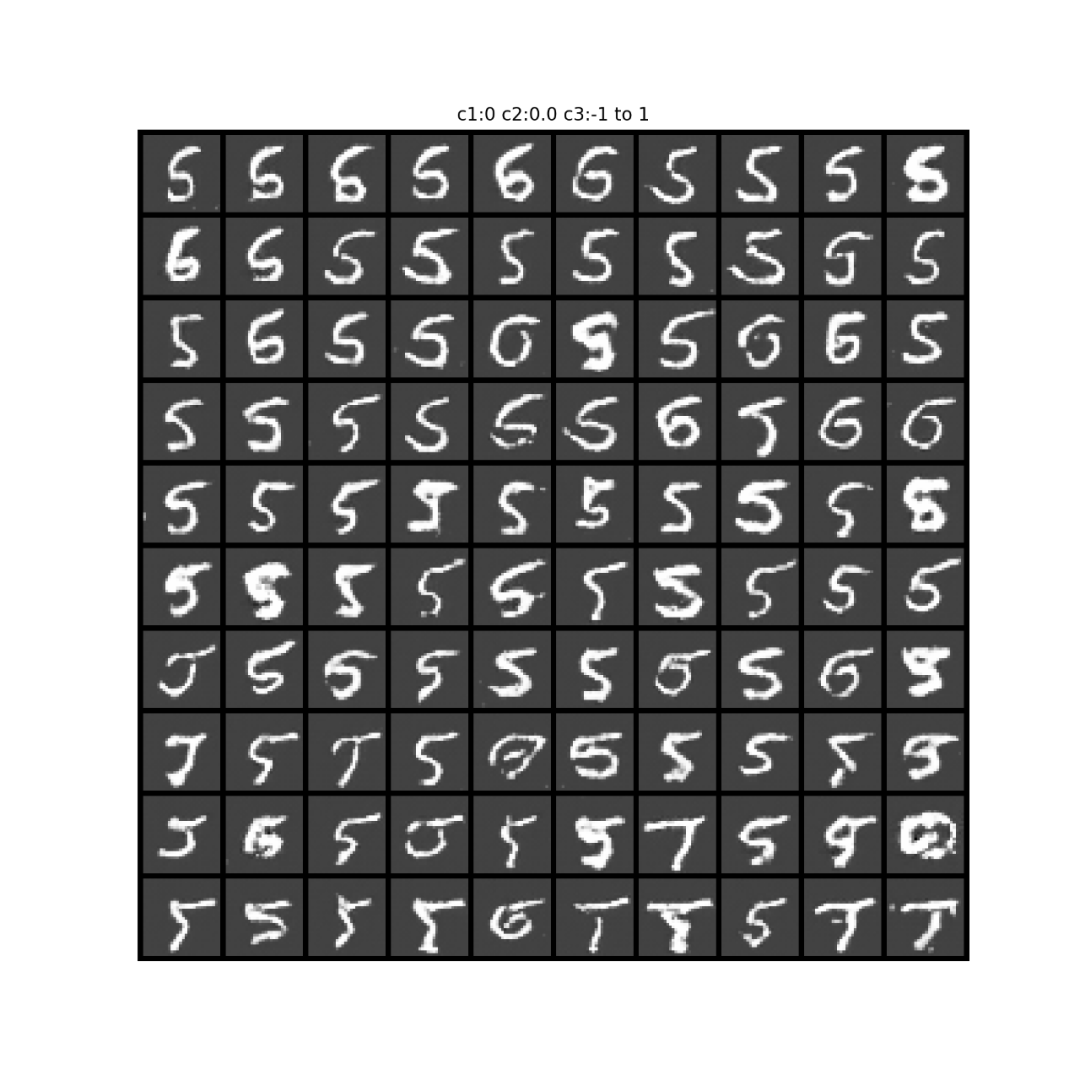
关于c3的试验结果:
下面不同图之间是由于c1取了不同的one-hot编码;
同一张图的不同小图,从左往右,从上往下,递进,是c3从-1到1均匀递进。
从输出来看,可能学习到的是(扭曲程度?或者粗细程度?)。这个学习得不是那么明显。









代码
model.py
import osimport torchimport torch.nn as nnimport torch.utils.data as Dataimport torchvisionfrom torch.utils.data import DataLoaderclass Generator(nn.Module): def __init__(self, input_size): super(Generator, self).__init__() strides = [1, 2, 2, 2] padding = [0, 1, 1, 1] channels = [input_size, 256, 128, 64, 1] # 1表示一维 kernels = [4, 3, 4, 4] model = [] for i, stride in enumerate(strides): model.append( nn.ConvTranspose2d( in_channels=channels[i], out_channels=channels[i + 1], stride=stride, kernel_size=kernels[i], padding=padding[i] ) ) if i != len(strides) - 1: model.append( nn.BatchNorm2d(channels[i + 1]) ) model.append( nn.ReLU() ) else: model.append( nn.Tanh() ) self.main = nn.Sequential(*model) def forward(self, x): x = self.main(x) return xclass Discriminator(nn.Module): def __init__(self, input_size): super(Discriminator, self).__init__() strides = [2, 2, 2] padding = [1, 1, 1] channels = [input_size, 64, 128, 256] # 1表示一维 kernels = [4, 4, 4] model = [] for i, stride in enumerate(strides): model.append( nn.Conv2d( in_channels=channels[i], out_channels=channels[i + 1], stride=stride, kernel_size=kernels[i], padding=padding[i] ) ) model.append( nn.BatchNorm2d(channels[i + 1]) ) model.append( nn.LeakyReLU(0.2) ) self.main = nn.Sequential(*model) self.D = nn.Sequential( nn.Linear(3 * 3 * 256, 1), nn.Sigmoid() ) self.C = nn.Sequential( nn.Linear(3 * 3 * 256, 10), nn.Softmax(dim=1) ) self.L = nn.Sequential( nn.Linear(3 * 3 * 256, 2), ) def forward(self, x): x = self.main(x).view(x.shape[0], -1) return self.D(x), self.C(x), self.L(x)if __name__ == '__main__': N_IDEAS = 100 G = Generator(N_IDEAS, ) rand_noise = torch.randn((10, N_IDEAS, 1, 1)) print(G(rand_noise).shape) DOWNLOAD_MNIST = False mnist_root = '../Conditional-GAN/mnist/' if not (os.path.exists(mnist_root)) or not os.listdir(mnist_root): # not mnist dir or mnist is empyt dir DOWNLOAD_MNIST = True train_data = torchvision.datasets.MNIST( root=mnist_root, train=True, # this is training data transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0] download=DOWNLOAD_MNIST, ) D = Discriminator(1) print(len(train_data)) cel = nn.CrossEntropyLoss() train_loader = Data.DataLoader(dataset=train_data, batch_size=2, shuffle=True) for step, (x, y) in enumerate(train_loader): print(x.shape) d, c, l = D(x) print(d.shape) print(c.shape) print(c.sum(dim=1)) print(cel(c, y)) z = torch.randn((x.shape[0], N_IDEAS - 10 - 2)) cat_c = torch.zeros((x.shape[0], 10)).scatter_(1, y.unsqueeze(1), 1) # one-hot encoding lat_c = (torch.rand((x.shape[0], 2)) * 2 - 1) # [-1, 1] rand_noise = torch.cat([z, cat_c, lat_c], dim=1) print(rand_noise.shape) breakmain.py
import osimport torchfrom torch.utils.data import Dataset, DataLoaderimport torch.nn as nnfrom model import Generator, Discriminatorimport torchvisionimport itertoolsimport matplotlib.pyplot as pltif __name__ == '__main__': LR = 0.0002 EPOCH = 20 # 50 BATCH_SIZE = 100 N_IDEAS = 100 # + 10 + 2 DOWNLOAD_MNIST = False TRAINED = False mnist_root = '../Conditional-GAN/mnist/' if not (os.path.exists(mnist_root)) or not os.listdir(mnist_root): # not mnist dir or mnist is empyt dir DOWNLOAD_MNIST = True train_data = torchvision.datasets.MNIST( root=mnist_root, train=True, # this is training data transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0] download=DOWNLOAD_MNIST, ) train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) torch.cuda.empty_cache() if TRAINED: G = torch.load('G.pkl').cuda() D = torch.load('D.pkl').cuda() else: G = Generator(N_IDEAS).cuda() D = Discriminator(1).cuda() optimizerG = torch.optim.Adam(G.parameters(), lr=LR) optimizerD = torch.optim.Adam(D.parameters(), lr=LR) optimizerInfo = torch.optim.Adam(itertools.chain(G.parameters(), D.parameters()), lr=LR) c_c = nn.NLLLoss() # criterion for classifying l_c = nn.MSELoss() for epoch in range(EPOCH): tmpD, tmpG, tmpInfo = 0, 0, 0 for step, (x, y) in enumerate(train_loader): x = x.cuda() z = torch.randn((x.shape[0], N_IDEAS - 10 - 2)).cuda() cat_c = torch.zeros((x.shape[0], 10)).scatter_(1, y.unsqueeze(1), 1).cuda() # one-hot encoding lat_c = (torch.rand((x.shape[0], 2)) * 2 - 1).cuda() # [-1, 1] y = y.cuda() rand_noise = torch.cat([z, cat_c, lat_c], dim=1).unsqueeze(2).unsqueeze(3) G_imgs = G(rand_noise) D_fake_D, D_fake_C, D_fake_L = D(G_imgs) D_real_D, D_real_C, D_real_L = D(x) p_fake = torch.squeeze(D_fake_D) p_real = torch.squeeze(D_real_D) c_fake = c_c(D_fake_C, y) l_fake = l_c(D_fake_L, lat_c) # c_real = c_c(D_real_C, y) # D_D = -torch.mean(torch.log(p_real) + torch.log(1 - p_fake)) # same as GAN # D_C_L = l_fake + c_fake # D_loss = D_D + D_C_L # # G_loss = -torch.mean(torch.log(p_fake)) + D_C_L # left part is same as GAN D_C_L = l_fake + c_fake D_D = -torch.mean(torch.log(p_real) + torch.log(1 - p_fake)) # same as GAN D_loss = D_D G_loss = -torch.mean(torch.log(p_fake)) # same as GAN optimizerD.zero_grad() D_loss.backward(retain_graph=True) optimizerD.step() optimizerG.zero_grad() G_loss.backward(retain_graph=True) optimizerG.step() optimizerInfo.zero_grad() D_C_L.backward() optimizerInfo.step() tmpD_ = D_loss.cpu().detach().data tmpG_ = G_loss.cpu().detach().data tmpInfo_ = D_C_L.cpu().detach().data tmpD += tmpD_ tmpG += tmpG_ tmpInfo += tmpInfo_ tmpD /= (step + 1) tmpG /= (step + 1) tmpInfo /= (step + 1) print( 'epoch %d avg of loss: D: %.6f, G: %.6f, Info: %.6f' % (epoch, tmpD, tmpG, tmpInfo) ) if epoch % 2 == 0: plt.title(str(y[0])) plt.imshow(torch.squeeze(G_imgs[0].cpu().detach()).numpy()) plt.show() torch.save(G, 'G.pkl') torch.save(D, 'D.pkl')judge.py
import numpy as npimport torchimport matplotlib.pyplot as pltfrom model import Generator, Discriminatorimport torchvision.utils as vutilsdef fixed_C1C3_test_C2(G, c1=0, c3=0, BATCH_SIZE=100, N_IDEAS=100): y = torch.from_numpy(np.array([c1 for i in range(BATCH_SIZE)])).type(torch.LongTensor) z = torch.randn((BATCH_SIZE, N_IDEAS - 10 - 2)).cuda() cat_c = torch.zeros((BATCH_SIZE, 10)).scatter_(1, y.unsqueeze(1), 1).cuda() # one-hot encoding lat_c = torch.from_numpy( np.concatenate([np.linspace(-1, 1, BATCH_SIZE // 10).repeat(10)[:, np.newaxis], np.zeros((BATCH_SIZE, 1)) + c3], axis=1)).type(torch.FloatTensor).cuda() rand_noise = torch.cat([z, cat_c, lat_c], dim=1).unsqueeze(2).unsqueeze(3) G_imgs = G(rand_noise) G_imgs = G_imgs.cpu().detach() # .numpy() fig = plt.figure(figsize=(10, 10)) plt.title("c1:%d c2:-1 to 1 c3: %.1f" % (c1, c3)) plt.axis("off") plt.imshow(np.transpose(vutils.make_grid(G_imgs, nrow=10, padding=2, normalize=True), (1, 2, 0))) plt.savefig("c1_%d_c3_%.1f.png" % (c1, c3), dpi=200) plt.show()def fixed_C1C2_test_C3(G, c1=0, c2=0, BATCH_SIZE=100, N_IDEAS=100): y = torch.from_numpy(np.array([c1 for i in range(BATCH_SIZE)])).type(torch.LongTensor) z = torch.randn((BATCH_SIZE, N_IDEAS - 10 - 2)).cuda() cat_c = torch.zeros((BATCH_SIZE, 10)).scatter_(1, y.unsqueeze(1), 1).cuda() # one-hot encoding lat_c = torch.from_numpy( np.concatenate([np.zeros((BATCH_SIZE, 1)) + c2, np.linspace(-1, 1, BATCH_SIZE // 10).repeat(10)[:, np.newaxis]], axis=1)).type(torch.FloatTensor).cuda() rand_noise = torch.cat([z, cat_c, lat_c], dim=1).unsqueeze(2).unsqueeze(3) G_imgs = G(rand_noise) G_imgs = G_imgs.cpu().detach() # .numpy() fig = plt.figure(figsize=(10, 10)) plt.title("c1:%d c2:%.1f c3:-1 to 1" % (c1, c2)) plt.axis("off") plt.imshow(np.transpose(vutils.make_grid(G_imgs, nrow=10, padding=2, normalize=True), (1, 2, 0))) plt.savefig("c1_%d_c2_%.1f.png" % (c1, c2), dpi=200) plt.show()if __name__ == '__main__': BATCH_SIZE = 100 N_IDEAS = 100 G = torch.load("G.pkl").cuda() for i in range(10): fixed_C1C3_test_C2(G, c1=i, c3=0, BATCH_SIZE=BATCH_SIZE, N_IDEAS=N_IDEAS) for i in range(10): fixed_C1C2_test_C3(G, c1=i, c2=0, BATCH_SIZE=BATCH_SIZE, N_IDEAS=N_IDEAS) # ======== c1-test(control numbers) ======== # y = torch.from_numpy(np.array([i // 10 for i in range(BATCH_SIZE)])).type(torch.LongTensor) z = torch.randn((BATCH_SIZE, N_IDEAS - 10 - 2)).cuda() cat_c = torch.zeros((BATCH_SIZE, 10)).scatter_(1, y.unsqueeze(1), 1).cuda() # one-hot encoding lat_c = (torch.zeros((BATCH_SIZE, 2)) - 1).cuda() # val = -1 [-1, -1] rand_noise = torch.cat([z, cat_c, lat_c], dim=1).unsqueeze(2).unsqueeze(3) G_imgs = G(rand_noise) G_imgs = G_imgs.cpu().detach() # .numpy() print(G_imgs.shape) fig = plt.figure(figsize=(10, 10)) plt.axis("off") plt.imshow(np.transpose(vutils.make_grid(G_imgs, nrow=10, padding=2, normalize=True), (1, 2, 0))) plt.savefig('normal.png', dpi=200) plt.show()















 3621
3621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









