






一、问题背景
很多数据工程师都会遇到一种情况,即部分数据不是来源于真实场景,而是需要随机生成。虽然从严格意义上讲,随机意味着有统计规律的实验结果,但在大部分ETL场景下,随机指的是伪随机数据。本文试图从数据的认识论角度讨论数据类型,并给出Kettle如何生成随机数据的解决方案。
二、数据分类
从数据挖掘的角度来分析,数据包括以下两种常用类别:
1、标称
标称可以理解为标准称呼的缩写,代表一些符号或者事物的名称。每个值代表一种类别、编码或者状态,因此标称类型往往又称之为分类。有编程经验的人,可以把标称理解为枚举类型。如果标称的可能值总数是2,那么又往往别称为二元类型。
所有可能的取值组成的集合称为值集合。举例来说,性别就是一种典型的标称类型,一般可以用如下值集合表示:
性别={男,女}
所以,性别也是一种典型的二元数据。
又如季节类型可以用如下值集合表示:
季节={春,夏,秋,冬}
又如军官军衔可以用如下值集合表示:
军官军衔={上将、中将、少将、大校、上校、中校、少校、上尉、中尉、少尉}
标称类型的数据一般没有顺序,而且做加减乘除等数学计算无现实意义,如果再去求均值或者方差就更加是做无用功了。
2、数值
数值是定量分析的基础,一般可以用整数或者实数表示,常见的表现形式包括自然数、区间数、百分比等。数值类型有序,且可以做数学计算,均值和方差等统计计算均有现实含义。
三、背景知识
Kettle利用java.util.Random类的两个方法来实现随机数字的产生。
public double nextDouble()
public int nextInt()
其中nextDouble产生[0,1)区间内的一个实数,nextInt产生232个随机整数值(包含符号位),分别对应图1中的随机数字和随机整数功能。
图1:

那么在Kettle只有两个基本方法的前提下,如何产生满足应用需求的数据呢?
1、标称类型随机数据
产生标称类型的随机数据,一般有求模法、范围法两种方法。
求模法是指通过随机数字与值集合的势进行模运算,从而得到特定集合内的数值。假设r为一个随机正整数,那么表达式:
r % 2
的可能值要么是0,要么是1。所以,如果需要随机的性别数据,只需将0转为男、1转为女即可。
又如表达式:
r % 4
的可能值为0、1、2、3。所以,如果需要随机的季节数据,只需将0转为春、1转为夏、2转为秋、3转为冬即可。
范围法是指将[0,1)区间等距离划分为n个区间(其中n为值集合的势),然后根据随机小数z所属范围来映射到值集合。同样以性别为例,假设z是一个[0,1)区间内的随机小数,那么:
如果 0<= z< 0.5,则得到男
如果 0.5<= z< 1,则得到女
又如以季节为例,那么:
如果 0<= z< 0.25,则得到春
如果 0.25<=z < 0.5,则得到夏
如果 0.5<= z< 0.75,则得到秋
如果 0.75<=z < 0.1,则得到冬
2、数值类型随机数据
如前所述,Kettle本身支持[0,1)区间内的随机小数以及随机整数。但现实需求往往不是如此简单。例如,也许需要的数据必须是在100到200之间的整数,亦或是需要一个在10到16之间的任意小数,亦或是需要一个13位的自然数。这类问题大体可以分为区间整数、区间小数、超大型数据等类型。
假设已有[0,1)区间内的随机小数r。
如果需要一个[a,b)区间范围内的随机实数k,那么可以通过
k = a + (b-a) * r
计算得到。
如果需要一个[a,b)区间范围内的随机整数,比较简单的办法是对区间范围内的随机实数取整。另外一种办法,就是通过随机正整数d,通过以下公式
k = a + d % (b-a)
得到。这种方法与求模法思想一致。
四、Kettle解决方案
1、计算器
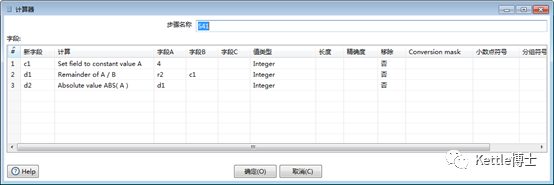
计算器步骤包括大量函数功能,比较常用的包括常量(Set field to constant value A)、求模(Remainder of A/B)、绝对值(Absolutevalue ABS(A))等。图2所示为一个生成四季标称的实例。其中c1字段为常量4,d1字段为随机整数r2对c1求模,d2字段为d1字段的绝对值。这样,最终得到的d2字段,可能值集合为{0,1,2,3}。
图2:
2、值映射
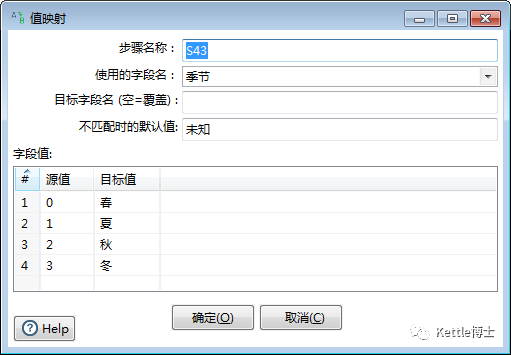
值映射步骤可以将生成的数字转为实际需要的标称值。如果3为一个数字转四季的实例。即原始值为0时,转为春;原始值为1时,转为夏;原始值为2时转为秋;原始值为3时转为冬。
图3:
3、数值范围
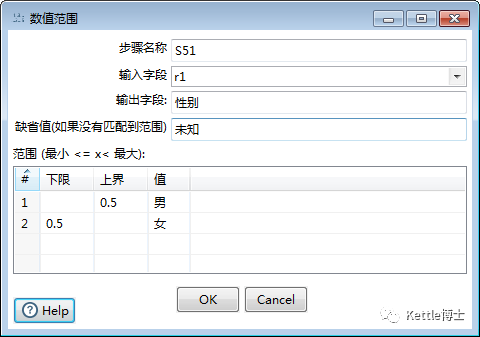
数值范围步骤可以根据输入字段所属区间,决定最终值。如图4实例所示,如果输入字段r1小于0.5,则输出男;如果输入字段r1大于0.5,则输出女。
图4:
4、公式
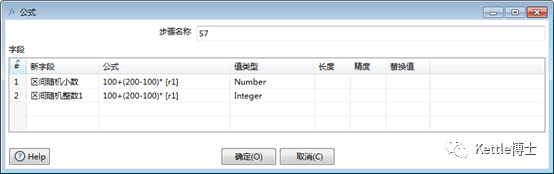
公式步骤可以编辑比较灵活的计算表达式。图5中的实例,采用前文所述计算公式,生成区间随机小数字段,并通过该步骤的类型转换能力,把随机小数取整,从而生成随机整数。
图5:
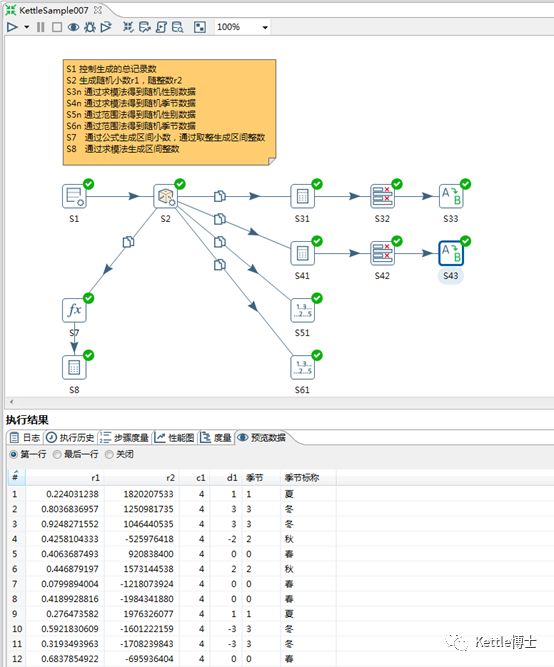
5、综合实例
结合上述所有方法,制作了一个综合示例。如图6所示,示例通过生成记录、生成随机数、公式、计算器、数值范围、值映射等步骤,演示了产生随机数据的各种方法。
图6:
五、总结
本文讨论了生成随机样本数据的多种方法,并通过一个综合实例演示Kettle中的解决办法。
如需示例转换文件,请联系微信号carol_sxh有偿获取,添加好友时请注明所需文件名(KettleSample007.ktr)。














 6440
6440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









