





一.先在你的数据表设置好唯一索引,sql语句如下:

alter table gift_doc add unique index(num_id);
如下图

Db::name('giftDoc')->insert($data_list,true);
//只要第二个参数$replace 等于true就行,
tp核心框架封装了,如下图
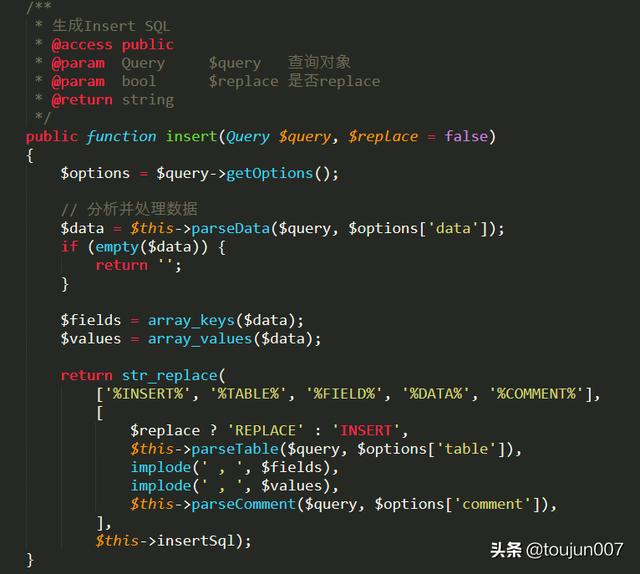
二.如果入库数据已经重复,不能添加唯一索引,数据输出需要去重处理

//实例化数据表
$test_data= M('hot');
//利用distinct方法去重
$data=$test_data->Distinct(true)->field('num_id')->order('num_id desc')->select();
//利用group方法去重
$data=$test_data->group('description')->order('description desc')->select();
dump($data);
对于两种去重方式:
利用distinct去重、简单易用,但只能对于单一字段去重,并且最终的结果也仅为去重的字段,
实际应用价值不是特别大。
利用group去重,最终的显示结果为所有字段,且对单一字段进行了去重操作,效果不错,
但最终显示结果除去去重字段外,按照第一个字段进行排序,可能还需要处理。
















 2878
2878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









