






一、索引概念
索引是一种供服务器在表中快速查找一个行的数据库结构。合理使用索引能够大大提高数据库的运行效率。
在数据库中建立索引主要有以下作用。(1)快速存取数据。 (2)既可以改善数据库性能,又可以保证列值的唯一性。 (3)实现表与表之间的参照完整性 (4)在使用order by、group by子句进行数据检索时,利用索引可以减少排序和分组的时间。
在关系数据库中,每一行都由一个行唯一标识RowID。RowID包括该行所在的文件、在文件中的块数和块中的行号。索引中包含一个索引条目,每一个索引条目都有一个键值和一个RowID,其中键值可以是一列或者多列的组合。
Oracle中提供如下类型的索引B-tree indexes
These indexes are the standard index type. They are excellent for primary key and highly-selective indexes. Used as concatenated indexes, B-tree indexes can retrieve data sorted by the indexed columns. B-tree indexes have the following subtypes:Index-organized tables
An index-organized table differs from a heap-organized because the data is itself the index. See "Overview of Index-Organized Tables".
Reverse key indexes
In this type of index, the bytes of the index key are reversed, for example, 103 is stored as 301. The reversal of bytes spreads out inserts into the index over many blocks. See "Reverse Key Indexes".
Descending indexes
This type of index stores data on a particular column or columns in descending order. See "Ascending and Descending Indexes".
B-tree cluster indexes
This type of index is used to index a table cluster key. Instead of pointing to a row, the key points to the block that contains rows related to the cluster key. See "Overview of Indexed Clusters".
Bitmap and bitmap join indexes
In a bitmap index, an index entry uses a bitmap to point to multiple rows. In contrast, a B-tree index entry points to a single row. A bitmap join index is a bitmap index for the join of two or more tables. See "Bitmap Indexes".
Function-based indexes
This type of index includes columns that are either transformed by a function, such as the UPPER function, or included in an expression. B-tree or bitmap indexes can be function-based. See"Function-Based Indexes".
Application domain indexes
This type of index is created by a user for data in an application-specific domain. The physical index need not use a traditional index structure and can be stored either in the Oracle database as tables or externally as a file. See "Application Domain Indexes".
Hash cluster indexes: defined specifically for a hash cluster
Global and local indexes: relate to partitioned tables and indexes
另外,按照索引所包含的列数可以把索引分为单列索引和复合索引。索引列只有一列的索引为单列索引,对多列同时索引称为复合索引。
B-tree索引结构如下图

当索引列是主键或者该列的选择性很高(数据很少重复)时,适合使用B-Tree索引。
索引中不存储null值,并且索引默认按升序排列。
索引组织表
表中数据按索引的形式组织,表即索引
如图

二、创建索引
创建索引组织表CREATE TABLE indexTable
(
ID VARCHAR2 (10),
NAME VARCHAR2 (20),
CONSTRAINT pk_id PRIMARY KEY (ID)
)
ORGANIZATION INDEX;
创建IOT时,必须要设定主键,否则报错
OVERFLOW子句(行溢出)
因为所有数据都放入索引,所以当表的数据量很大时,会降低索引组织表的查询性能。此时设置溢出段将主键和溢出数据分开来存储以提高效率。溢出段的设置有两种格式:
PCTTHRESHOLD n:制定一个数据块的百分比,当行数据占用大小超出时,该行的其他列数据放入溢出段
INCLUDING column_name :指定列之前的列都放入索引块,之后的列都放到溢出段。CREATE TABLE t_iot
(
ID VARCHAR2 (10),
NAME VARCHAR2 (20),
CONSTRAINT pk_id PRIMARY KEY (ID)
)
ORGANIZATION INDEX
PCTTHRESHOLD 20
OVERFLOW TABLESPACE users
INCLUDING name;
如上例所示,name及之后的列必然被放入溢出列,而其他列根据 PCTTHRESHOLD 规则。
索引组织表的辅助索引SQL> create index idx_secondary_name on indexTable(name);
Index created.
该索引与堆表的索引有所不同,该索引中的rowid,我们称之为逻辑rowid。是根据索引组织表的主键通过base64算法得出的一个值。
For example, assume that the departments table is index-organized. The location_id column stores the ID of each department. The table stores rows as follows, with the last value as the location ID:10,Administration,200,1700
20,Marketing,201,1800
30,Purchasing,114,1700
40,Human Resources,203,2400
A secondary index on the location_id column might have index entries as follows, where the value following the comma is the logical rowid:1700,*BAFAJqoCwR/+
1700,*BAFAJqoCwQv+
1800,*BAFAJqoCwRX+
2400,*BAFAJqoCwSn+
如果需要为索引组织表创建位图索引的话,需要创建mapping tableSQL> drop index idx_secondary_name;
Index dropped.
SQL> create bitmap index idx_secondary_name on indexTable(name);
create bitmap index idx_secondary_name on indexTable(name)
*
ERROR at line 1:
ORA-28669: bitmap index can not be created on an IOT with no mapping table
mapping table中存储索引组织表的逻辑rowid,bitmap index中存储mapping table数据的rowid。通过访问mapping table将rowid转换成逻辑rowid。

创建mapping tableSQL> alter table indexTable move mapping table;
Table altered.
SQL> create bitmap index idx_secondary_name on indexTable(name);
Index created.
位图索引
当索引列的值重复数据非常多时,适合使用位图索引。位图索引结构如下
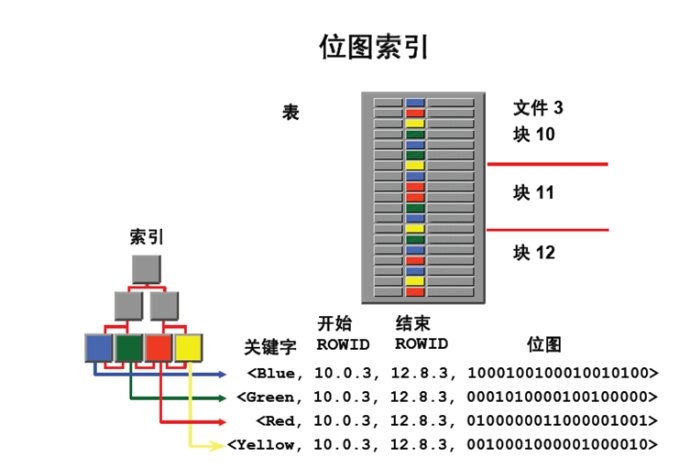
与B-tree索引不同,位图索引存储null值,对于count计算有很大的益处。位图索引不适合高并发修改数据,因为修改数据时,需要将索引条目锁定。一个条目(Blue)包含了太多的行。位图索引适合做and or等运算和count统计,比如需要求上例中关键字为Blue的count数,只需计算位图中为1的个数。
对于and 和 or 只需对位图做位运算即可,非常高效。
位图索引还有一个特例,索引列不在主表上,而是由join查询得出。我们看如下图示
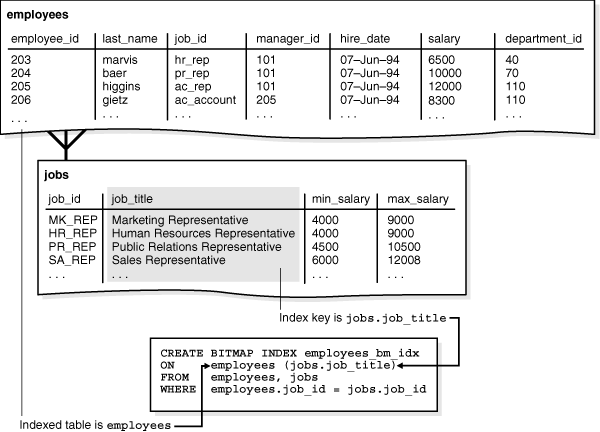
在表employees上建立一个位图索引,但是该索引列是由jobs表提供的。
上图示的例子能很好的理解bitmap join 索引,但是不实用。因为在employees的job_id上建立位图索引也能达到相同的效果。
我们假设有Customers,sales两张表,这两张表都很大。
如果有如下需求SELECT SUM (S.AMOUNT_SOLD)
FROM CUSTOMERS C, SALES S
WHERE C.CUST_ID = S.CUST_ID AND C.CUST_CITY = 'Yokohama';
就算cust_id字段上有索引,也不会提高查询性能。
我们可以建立如下索引CREATE BITMAP INDEX cust_sales_bji
ON sales (c.cust_city)
FROM customers c, sales s
WHERE c.cust_id = s.cust_id;SQL> grant select any table to scott;
Grant succeeded.
SQL> conn scott/tiger
Connected.
SQL> create table customers as select * from sh.customers;
Table created.
SQL> ALTER TABLE CUSTOMERS ADD (
CONSTRAINT CUSTOMERS_PK
PRIMARY KEY
(CUST_ID)); 2 3 4
Table altered.
SQL> create table sales as select * from sh.sales;
Table created.
SQL> ALTER TABLE SALES ADD (
CONSTRAINT SALES_PK
PRIMARY KEY
(PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, PROMO_ID));
Table altered.
SQL> CREATE BITMAP INDEX cust_sales_bji
ON sales (c.cust_city)
FROM customers c, sales s
WHERE c.cust_id = s.cust_id;
Index created.
反转索引
如果某些采用sequence生成值,而该列有建有索引。因为新插入的数据全部都集中在一起,则会引起索引的热点块,降低性能。还会浪费索引的空间,增加索引的高度。因为一旦发生索引块的分裂。较小的索引块将再也不会被使用了。
为了解决此类问题,可以将索引列的值进行反转,然后再建立索引。如值为123456789,反转成987654321.SQL> create table tbl_reverse_idx(id number,text varchar2(30));
Table created.
SQL> insert into tbl_reverse_idx select rownum,object_name from dba_objects;
87084 rows created.
SQL> create index idx_reverse_id on tbl_reverse_idx(id) reverse;
Index created.SQL> select * from tbl_reverse_idx where id=999;
Execution Plan
----------------------------------------------------------
Plan hash value: 1916889338
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 150 | 135(0)| 00:00:02 |
| 1 | TABLE ACCESS BY INDEX ROWID| TBL_REVERSE_IDX | 5 | 150 | 135(0)| 00:00:02 |
|* 2 | INDEX RANGE SCAN | IDX_REVERSE_ID | 321 | | 1(0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
这样对范围查询来说,使用索引效率就非常低。SQL> select /*+INDEX(T IDX_REVERSE_ID)*/* from tbl_reverse_idx T where id between 1000 and 1010;
11 rows selected.
降序索引
对于单列索引,使用降序索引没有意义,因为索引可以重两端扫描。对于复合索引,并且查询语句需要对复合索引中的列按不同顺序排列。
例如查询SQL> select last_name,department_id from hr.employees order by last_name ASC, department_id DESC;
要想避免排序,需要建立如下索引CREATE INDEX emp_name_dpt_ix ON hr.employees(last_name ASC, department_id DESC);
基于函数索引SQL> select * from emp where LOWER(ename)='king';
如果上面的查询要使用索引,则必须建立函数索引SQL> create index idx_emp_ename_lower on emp(lower(ename));
Index created.SQL> select * from emp where LOWER(ename)='king';
Execution Plan
----------------------------------------------------------
Plan hash value: 2294275149
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | |1 | 38 |2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP |1 | 38 |2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_EMP_ENAME_LOWER |1 | |1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------
部分数据索引
考虑有个表中有一字段PROCESSED_FLAG,它有两个取值N或者Y,Y表示该数据已经被处理过。对于业务来说,每次查询只关心PROCESSED_FLAG=N的,并且PROCESSED_FLAG=N的数据只占用表的很小一部分。如果在该字段上建立普通的索引,那么索引中将有大量的Y,并且还不被查询使用。为了提高效率及减少存储。我们可以在建立索引时做如下变更。SQL> create table big_table as select * from dba_objects;
Table created.
SQL> select distinct TEMPORARY from big_table;
SQL> select TEMPORARY,count(*) from big_table group by TEMPORARY;
T COUNT(*)
- ----------
Y 228
N 86859
SQL> create index idx_big_table_temporary on big_table(decode(TEMPORARY,'Y','Y',null));
SQL> select * from big_table where decode(TEMPORARY,'Y','Y',null)='Y';
228 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1057379504
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 228 | 47652 | 2(0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| BIG_TABLE | 228 | 47652 | 2(0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_BIG_TABLE_TEMPORARY | 228 | | 1(0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------
DML操作与创建索引是互斥的,也就是说正在创建索引时,表不能执行DML操作,正在进行DML的时候不能创建索引。
Oracle引入了online关键字,使得创建索引与DML可以同时进行。
会话1,执行更新操作,但是不提交SQL> update big_table set object_name=lower(object_name);
87087 rows updated.
会话2建立索引SQL> create index idx_big_table_oname on big_table(object_name);
create index idx_big_table_oname on big_table(object_name)
*
ERROR at line 1:
ORA-00054: resource busy and acquire with NOWAIT specified or timeout expired
在线建立索引。SQL> create index idx_big_table_oname on big_table(object_name) online;
Index created.
三、索引维护
修改索引的存储属性
ALTER INDEX emp_ename
STORAGE (PCTINCREASE 50);
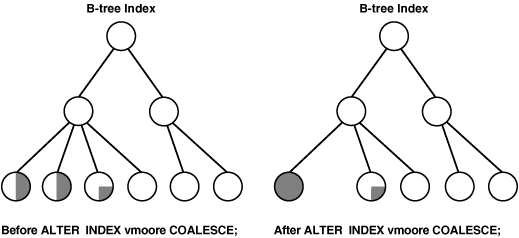
当索引中有碎片时,可以使用索引重建或者合并来解决。

重建索引ALTER INDEX emp_name REBUILD;ALTER INDEX emp_name REBUILD ONLINE;
索引合并ALTER INDEX vmoore COALESCE;
将索引标记为unusable
当索引为unusable时,优化器将忽略索引,并且DML不再维护索引(如果是唯一索引,dml操作将报错)。当需要大批量数据导入时,可以将索引unusable以提高导入的性能。ALTER INDEX emp_email_uk UNUSABLE;ALTER INDEX i_emp_ename MODIFY PARTITION p2_i_emp_ename UNUSABLE;
unusable的索引要想再次生效,必须使用rebuild index。
将索引标记为Invisible
当索引为Invisible时,优化器将忽略索引,但是DML继续维护索引。分区索引不能单独的将某个分区Invisible。ALTER INDEX index INVISIBLE;ALTER INDEX index VISIBLE;
重命名索引ALTER INDEX index_name RENAME TO new_name;
监控索引是否被使用
系统建立索引后,到底业务查询有没有使用呢?SQL> alter index idx_big_table_oname monitoring usage;
Index altered.
Oracle提供如下视图监控索引的使用情况SQL> select * from V$OBJECT_USAGE;
INDEX_NAME TABLE_NAME MON USE START_MONITORING END_MONITORING
------------------------------ ------------------------------ --- --- ------------------- -------------------
IDX_BIG_TABLE_ONAME BIG_TABLE YES NO 09/09/2015 20:10:56
当索引被使用以后SQL> select object_name from big_table where object_name='EMP';
OBJECT_NAME
--------------------------------------------------------------------------------------------------------------------------------
EMP
SQL> select * from V$OBJECT_USAGE;
INDEX_NAME TABLE_NAME MON USE START_MONITORING END_MONITORING
------------------------------ ------------------------------ --- --- ------------------- -------------------
IDX_BIG_TABLE_ONAME BIG_TABLE YES YES 09/09/2015 20:10:56
监控索引的使用空间
当表频繁的插入、删除、更新。有可能索引会有碎片。可以通过如下方式来检查索引的空间使用率。
生成一张表CREATE TABLE t1
AS
SELECT ROWNUM rn,
DBMS_RANDOM.string ('u', 20) name1,
DBMS_RANDOM.string ('u', 15) name2
FROM DUAL
CONNECT BY LEVEL
create index i1 on t1(rn);
analyze index i1 validate structure;
SQL> select height,lf_rows,del_lf_rows,lf_blks,del_lf_rows btree_space,used_space,pct_used from index_stats;
HEIGHT LF_ROWS DEL_LF_ROWS LF_BLKS BTREE_SPACE USED_SPACE PCT_USED
---------- ---------- ----------- ---------- ----------- ---------- ----------
3 99999902226 0 16006445 90
SQL> delete from t1 where mod(rn,2) =1;
500000 rows deleted.
SQL> analyze index i1 validate structure;
Index analyzed.
SQL> select height,lf_rows,del_lf_rows,lf_blks,del_lf_rows btree_space,used_space,pct_used from index_stats;
HEIGHT LF_ROWS DEL_LF_ROWS LF_BLKS BTREE_SPACE USED_SPACE PCT_USED
---------- ---------- ----------- ---------- ----------- ---------- ----------
3 695404 1954052226 195405 11132925 63
SQL> alter index i1 rebuild online;
Index altered.
SQL> analyze index i1 validate structure;
Index analyzed.
SQL> select height,lf_rows,del_lf_rows,lf_blks,del_lf_rows btree_space,used_space,pct_used from index_stats;
HEIGHT LF_ROWS DEL_LF_ROWS LF_BLKS BTREE_SPACE USED_SPACE PCT_USED
---------- ---------- ----------- ---------- ----------- ---------- ----------
3 49999901113 0 7998149 90
索引的集群因子
什么是集群因子(Clustering Factor)呢?集群因子是通过一个索引扫描一张表时需要访问的表的数据块的数量。集群因子的计算方法如下:
(1) 扫描一个索引;
(2) 比较某行的ROWID和前一行的ROWID,如果这两个ROWID不属于同一个数据块,那么集群因子增加1;
(3) 整个索引扫描完毕后,就得到了该索引的集群因子。
以上面集群因子的计算方式可以看出,集群因子反映了索引范围扫描可能带来的对整个表访问过程的IO开销情况,如果集群因子接近于表存储的块数,说明这张表是按照索引字段的顺序存储的。如果集群因子接近于行的数量,那说明这张表不是按索引字段顺序存储的。在计算索引访问成本时,集群因子十分有用。集群因子乘以选择性参数就是访问索引的开销。
如果这个统计数据不能反映出索引的真实情况,那么可能会造成优化器错误地选择执行计划。另外,如果某张表上的大多数访问是按照某个索引做索引扫描,那么将该表的数据按照索引字段的顺序重新组织,可以提高该表的访问性能。
我们看两个图就明白了集群因子


可见集群因子越高,范围扫描的性能越低。
查看索引的集群因子SQL> SELECT INDEX_NAME, CLUSTERING_FACTOR
FROM ALL_INDEXES
WHERE INDEX_NAME IN ('PK_EMP','IDX_EMP_ENAME_LOWER'); 2 3
INDEX_NAME CLUSTERING_FACTOR
------------------------------ -----------------
IDX_EMP_ENAME_LOWER 28
PK_EMP 2
重建索引并不能减少集群因子















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









