







一:一元线性回归
线性回归是机器学习中很基础的知识,这里复习推导一下。
在中学时代我们就接触过一元线性方程, 由x->y。
线性回归就是,我们通过y->x的过程。这里我们通过计算预测值y,和真实值的差距
单个样本点差距
整个数据集的差距和的均值
代入上述公式得
第一种方法:牛顿法NewTon
思想:对现有极小值点附近对f(x)做二阶泰勒展开,进而找到下一个估计值。
我们知道,当时,f(x)取最小值。
进而:
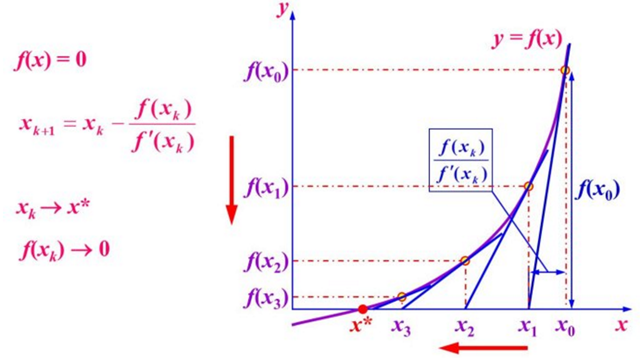
第二种:最小二乘法
1:先对w求导
2:再对b求导
令:
第三种:梯度下降法
这里使用均方误差
根据链式求导法则 ,对w求导
对b求导
更新 w,b
二:多元线性回归
三:逻辑回归
1:机器学习中按照目的不同可以分为两大类:回归和分类.
- 线性回归的线性关系可以来拟合一个事情的发生规律,找到这个规律的表达公式,将得到的数据带入公式以用来实现预测的目的,我们习惯将这类预测未来的问题称作回归问题.
- 逻辑回归就可以用来完成分类任务.
输入变量与输出变量均为连续变量的预测问题是回归问题,输出变量为有限个离散变量的预测问题成为分类问题.
2: 逻辑回归———分类问题
首先解决离群值问题将线性的 替换为非线性的
函数表达形式
根据极大似然估计, 就是所有样本预测正确的概率相乘得到的P(总体正确)最大
令
上述公式最大时公式中W的值就是我们要的最好的W.下面对公式进行求解.我们知道,一个连乘的函数是不好计算的,我们可以通过两边同时取log的形式让其变成连加.
得到的这个函数越大,证明我们得到的W就越好.因为在函数最优化的时候习惯让一个函数越小越好,所以我们在前边加一个负号.得到公式如下: 这个函数就是我们逻辑回归(logistics regression)的损失函数,我们叫它交叉熵损失函数.
3:求解——梯度下降
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









