





一、概况
上一篇我们用一个表情网站入门了爬虫,爬了很多表情。今天我们继续在爬的路上,今天就爬个校花吧,毕竟妹子属于稀缺资源,要不妈妈总会问,你到底找不找女朋友了,爬点校花吧,以后跟妈妈聊天,可以哭着对她说,这就是我女朋友,漂亮吧~。行了,为了妈妈不担心,我们开始行动吧。
二、准备
在爬之前,我们要确定我们爬取的网站以及要爬取的哪些信息。
- 目标网站:校花网(http://www.xiaohuar.com/list-1-1.html)
- 获取信息:
- 校花的名字
- 校花的照片
- 校花的详细资料
确定好要爬的东西,就开始分析网站,其实我特别想获取联系方式,可是实力不允许呀。没有~
三、首页分析
- URL地址变化分析
- 第一页:http://www.xiaohuar.com/list-1-0.html
- 第二页:http://www.xiaohuar.com/list-1-1.html
- 第五页:http://www.xiaohuar.com/list-1-4.html
不解释了,每页的地址应该能看的清清楚楚,明明白白。
- 提取信息分析 我们确定了每张图片都是一个独立的div标签,那么我首要任务就是把每页的div标签全部在爬下来
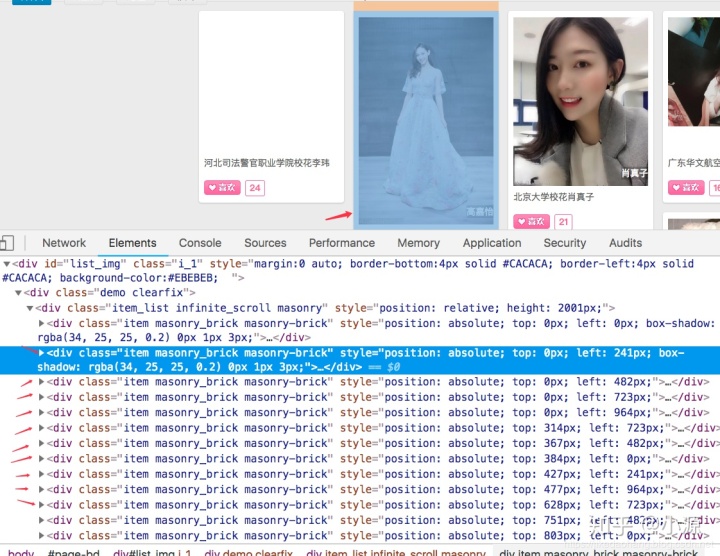
我们随便点一个div,看看里面的标签,从每个div里面我们可以取出下面这些信息。那么详细信息我们去哪取,对,校花的详细信息在详情链接,我们要把详情链接取出来,在去里面看看有什么?
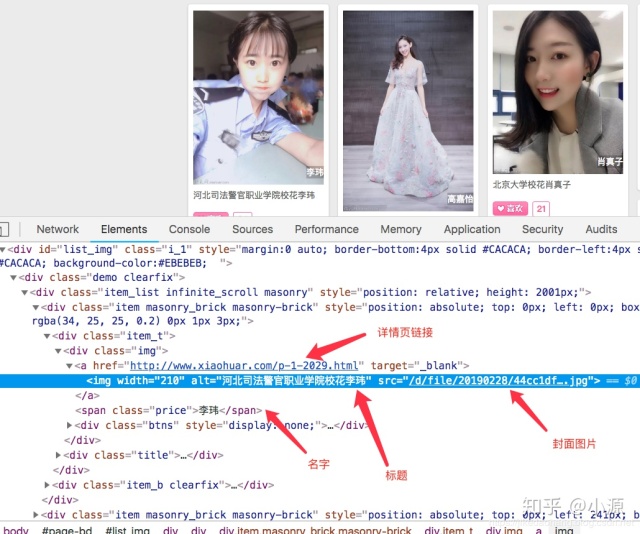
打开详细链接,我们可以看到如下信息,是我们想要的,有些信息确实没有,那也没办法了。
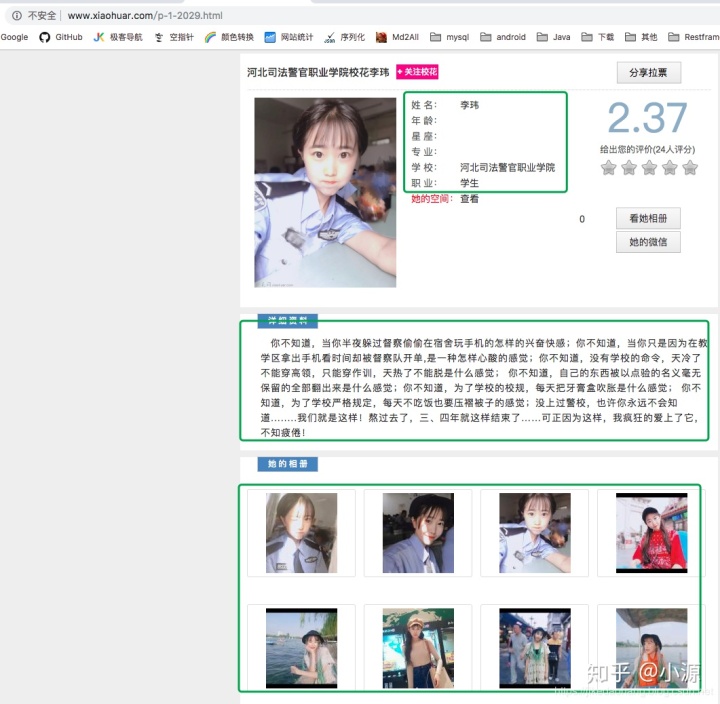
先分析到这,详情页的信息,我们先不管在哪个标签下,先把我们目前想要的这些信息获取出来在说。
四、首页提取
我们用xpath插件先简单定位一下,xpath有个特别好用的功能,就是模糊定位,我们发现想要的div标签class属性都包含一个一样的样式名字。 - 注意: 一定确保只是你想要的内容包括的样式。如果下面这个包含的是item属性,就会取出126个,这肯定是不对的。功能虽好,但是一定要慎重使用。
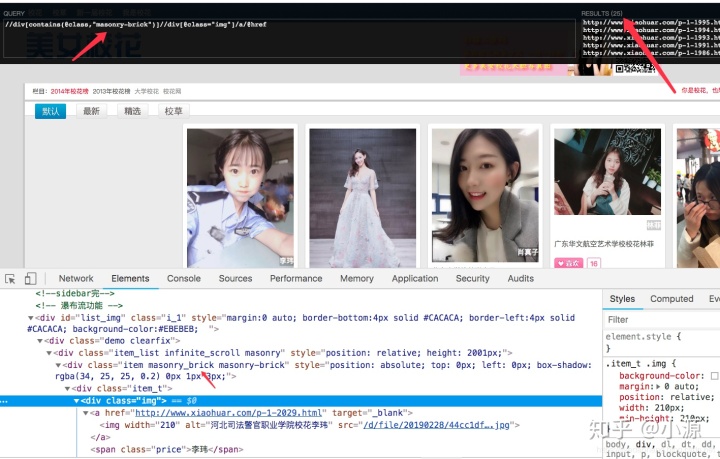
我们已经把最重要的信息详情地址爬取下来了,剩下的就是代码实现,代码跟上一篇的斗图啦项目的逻辑差不多。
import 上面有大家两个注意的地方 - 网站的编码格式 可以通过查看源码看到网站编码格式,可以看到这个网站并不是UTF-8的编码格式,我们可以直接用reponse.text让它自己东西编码解析。

- 代码里面请求网站源代码是否和浏览器的源代码是否一致 如果没出现取不到的情况,可以忽略这个问题。如果出现了,可以考虑一下是否是这出现的影响,在代码里面有注释。
五、详情页分析
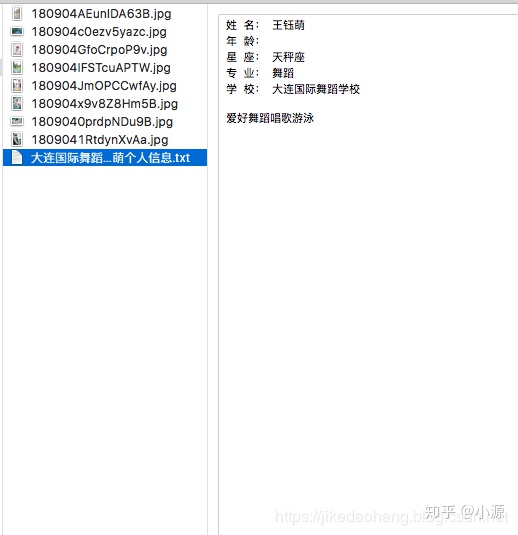
- 资料 随便点开一个详情页地址,先取出资料信息,取前7个tr标签,最后一个标签不取。暂时看了几个网页,好像都是这几个,后面如果遇到问题,在做容错处理。
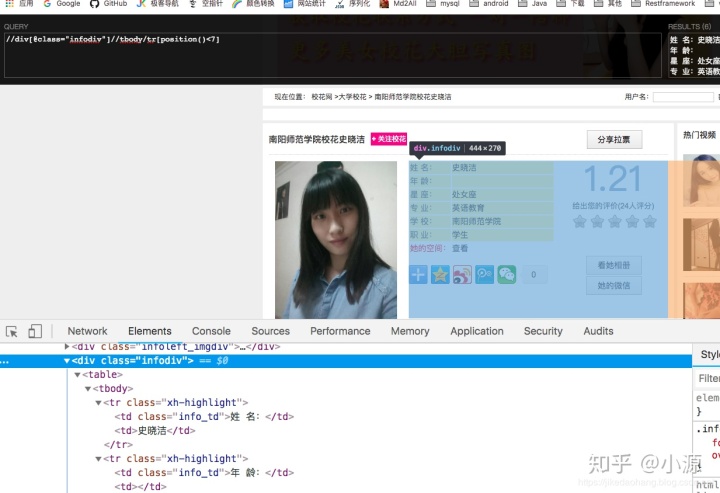
- 详细资料 详细资料比较好取,但是有需要注意的地方,有的校花没有详细资料。所以得做判空处理,有的详细资料标签不一样,所有咱们取父级div里面所有的文本就行。 特别提醒我这里面使用的//代表父标签任意的地方的文本。
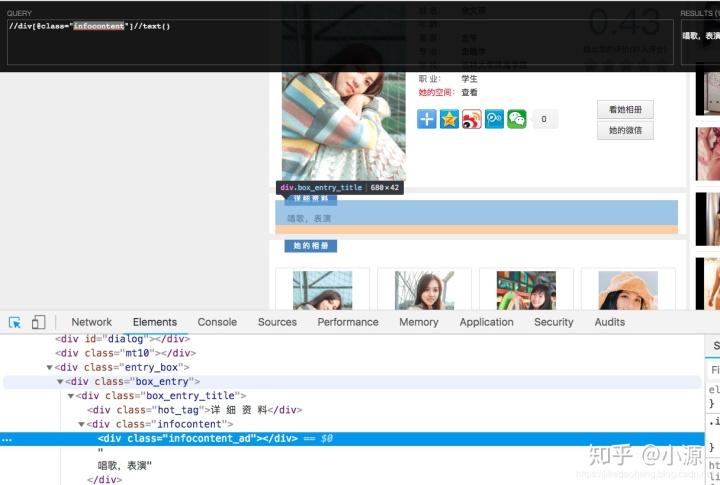
看起来直接取父亲标签下所有的内容应该是没问题。
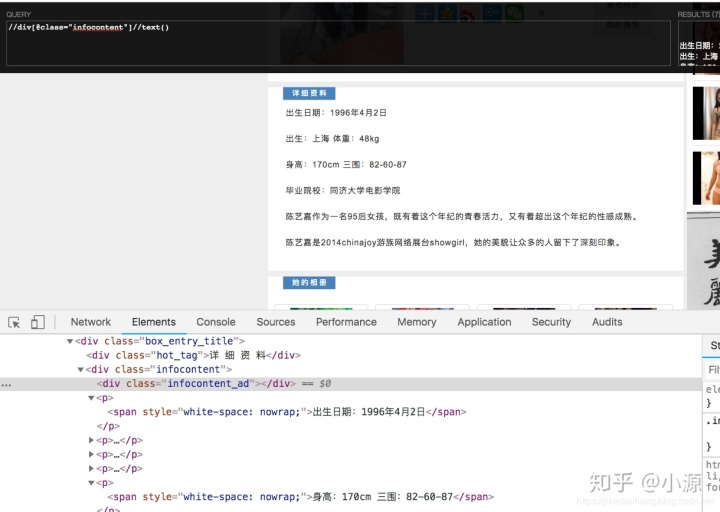
- 相册 我们相册都是小图,这不能是我们忍受的,我们要高清大图,但是要高清图片还要进入她的空间取获取。所以在相册这,我们只要获取到校花的空间地址就可以了。
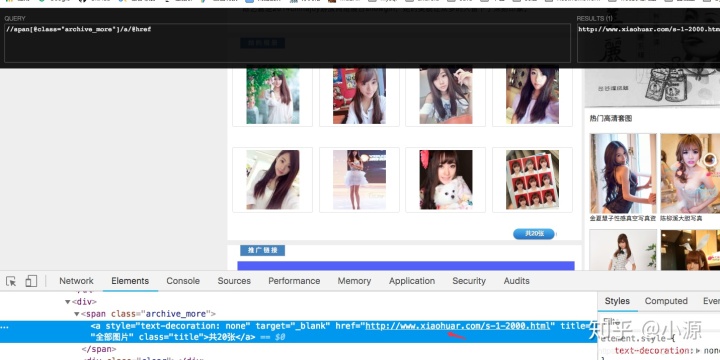
这详情页基本上我们就需要取这些字段,去用代码一点一点爬下来。
import 六、高清大图
这个页面我们最重要的就是把高清大图的链接找到,链接加上域名就是完整的大图地址。
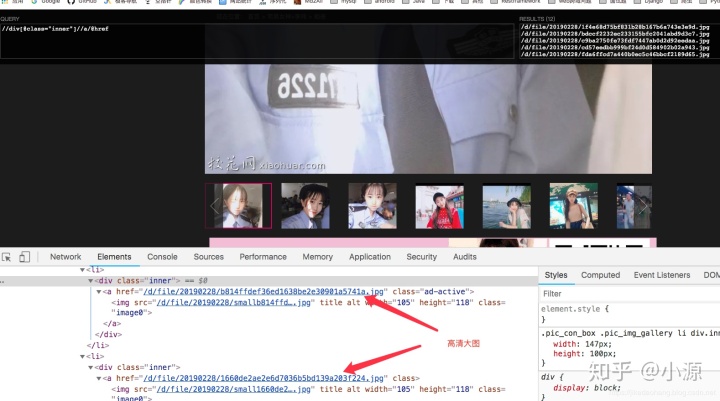
在爬的过程中,我们发现有的图片是以Http开头,有的不是,并且的有是错误的图片地址,所有我们需要做容错处理。
import 先暂时下载一些,为了九牛二虎之力,终于可以看到点比较喜欢的校花了。先来预览一张高清大图吧

还不错。但是我们需要重新整理一下代码,我们根据校花的名字创建文件夹,然后把校花的资料、详细信息、空间相册的图片全下载进去。方便我们以后管理。又到我们考虑问题的时候了 - 文件夹的命名 我们在首页提取的标题字段可以做文件夹的名字 - 图片的名字 图片的名字可以拿图片地址后多少位进行命名 - 个人信息命名 个人信息的名字也可以拿首页的标题
那么开始实现吧,在每个函数实现创建文件夹的操作。还是实现多页下载。
全部代码:
import 最终我们在本地看到有如下的文件夹:
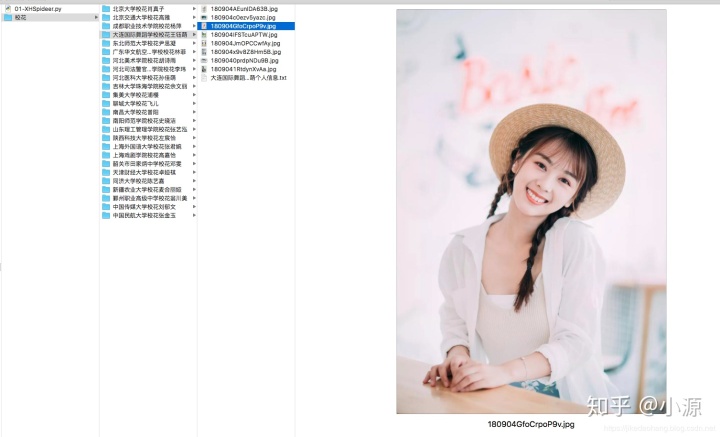
我只爬取了第一页,大家有兴趣的可以多爬取几页。还有一个问题,大家可以自己处理,就是把代码简单的封装一下,比如发起网络请求可以单独封装一个方法。
七、总结
我们又通过一个例子,对爬虫有了一定的理解,在爬取的过程还是会遇到很多问题的,有些问题我们可能前期就能想到,而有的问题可能在运行代码的时候才会发现。不过既然是问题,就有解决办法。所有在打算爬取一个网站的时候,还要简单分析: - 我们要提取哪些信息 - 网页地址的URL变化 - 信息应该在哪个页面提取,有的页面信息重复 - 多爬取一些信息,每个网页的结构可能不一样 - 请求的网站源代码跟浏览器里面的源代码是否有区别(以请求下来的源码为准)
好了,反正不管如何,我们把校花图片爬下来了,妈妈在也不会担心我们不给她发女朋友的照片了。
- 此项目仅供学习,请勿用于商业用途
- 源码
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









