







数据仓库开发中,ETL是主要的部分,在涉及到单表数据量比较大时(千万以上)会遇到两方面的问题:
- 抽取效率(时间长)
- 性能问题(服务器内存资源有限)
比如最近项目中要抽取一个2000万条数据的表,存储大概7.5G左右。直接用kettle的表输出-表输出,完成抽取大概要花费接近50分钟。
于是抱着想办法优化的目的,在网上寻找解决方案,发现用kettle分页循环导入可以达到目的,于是模仿相关博文原理(链接放在文章末尾)自己实现了一遍,中间有些小坑,好在没卡多久。
在这里记录一个详细版本,交代每一步的步骤,对小白会比较友好吧,如果这篇文章对你有帮助,请不要吝啬你的赞。

实现过程
一、原理简介:
所谓分页循环,其实就是将表里的数据按照rownum分页,比如每页5000条,然后循环逐页抽取
源表数据量:2000W+
每页数据量:5000
页数:4000+
源表:table1
目标表:table2
主流程
kettle分页循环.kjb
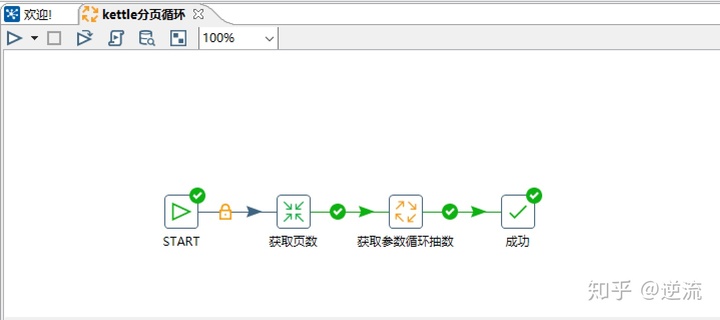
主job结构:
【1】转换:获取页数.ktr ——用来获取页数表结构
【2】作业:获取参数循环抽数.kjb —— 获取分页数,设置参数,获取参数进行循环抽数。
先来看第一个转换(获取页数)的结构
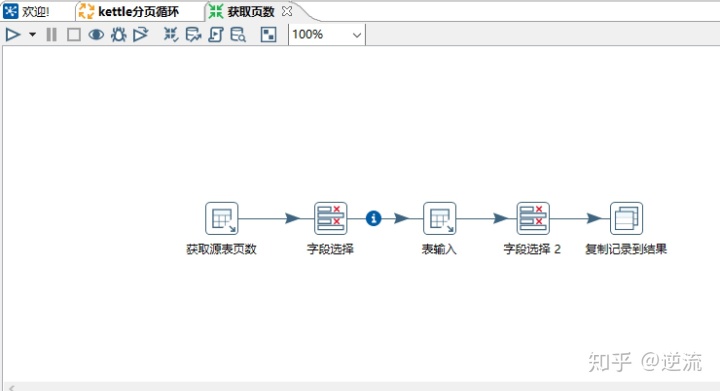
1.获取源表页数
这里用表输入组件,sql句子的含义是计算源表行数除以5000,再用ceil函数向上取整。
注意比如 行数/5000 = 4101.4,这个时候我们要的结果页数应该是4102。
SELECT ceil(count(1)/5000) as pages FROM table1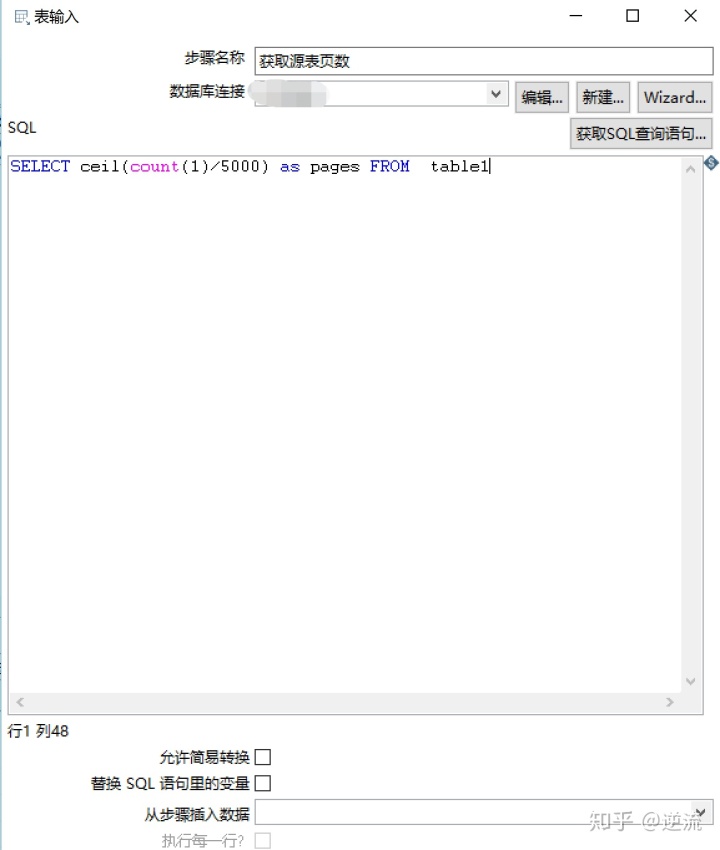
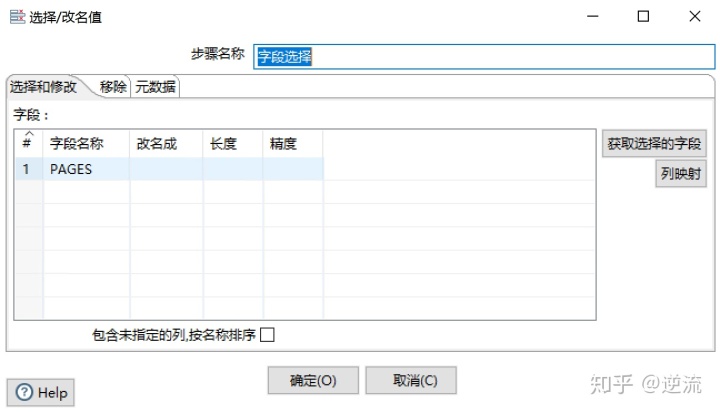
2.字段选择
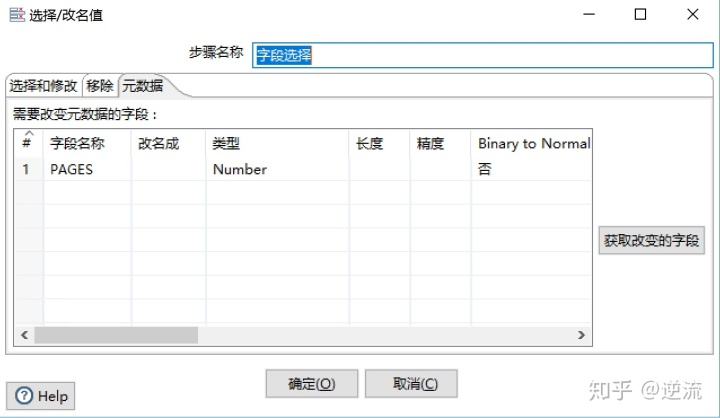
这里就简单设置一下从上一步获取的字段,类型为Number
3.表输入
注意红框标注位置,?代表取前一个步骤的常量结果,在下方红框区域要选择前一个步骤。
select rownum as P_PAGE from table1 where rownum<=?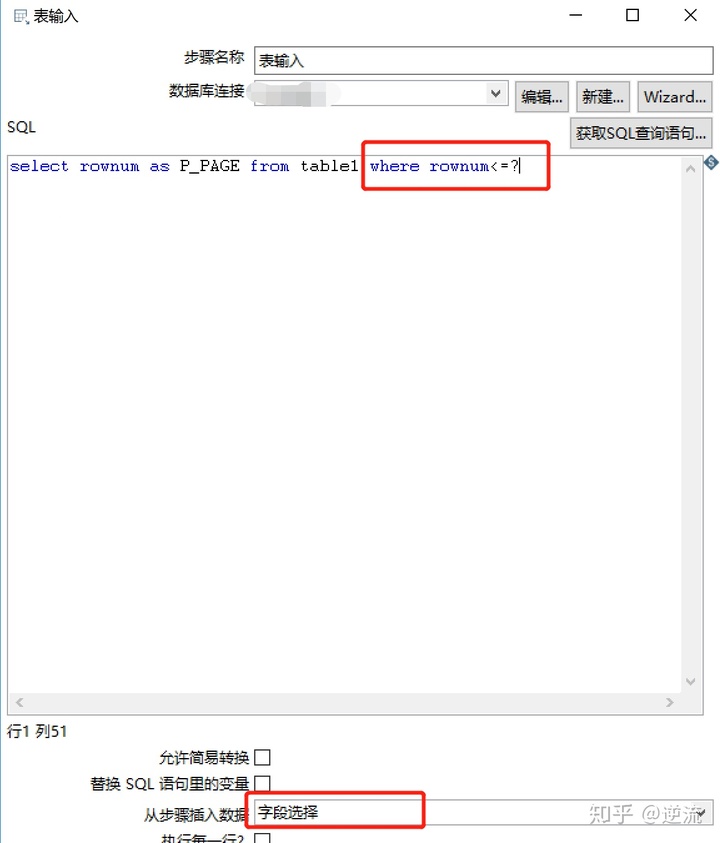
这里会借助rownum 获取一个类似下面这样的表结构
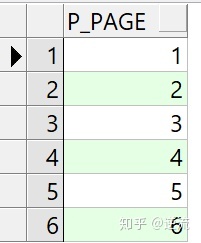
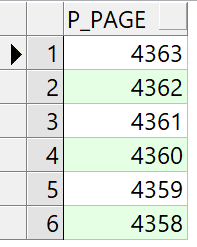
也就是类似从1到4363(最大页数)的一个序列
4.字段选择
和步骤2的字段选择设置差不多
5.复制结果到记录
直接拖拽作业控件中的复制记录到结果组件过来连线即可
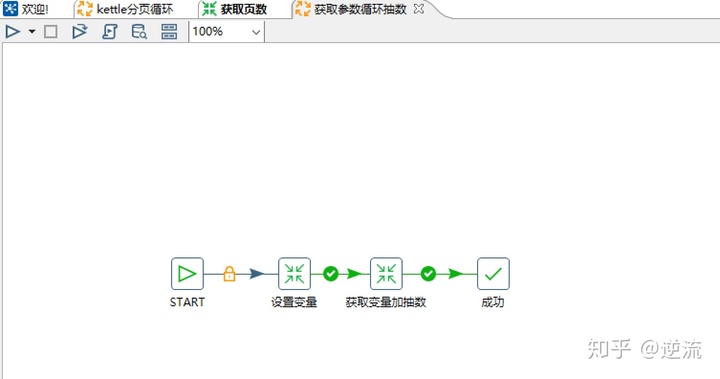
再看第二个作业
这个作业由2个转换组成,一个是设置变量,一个是获取变量加抽数
转换:设置变量
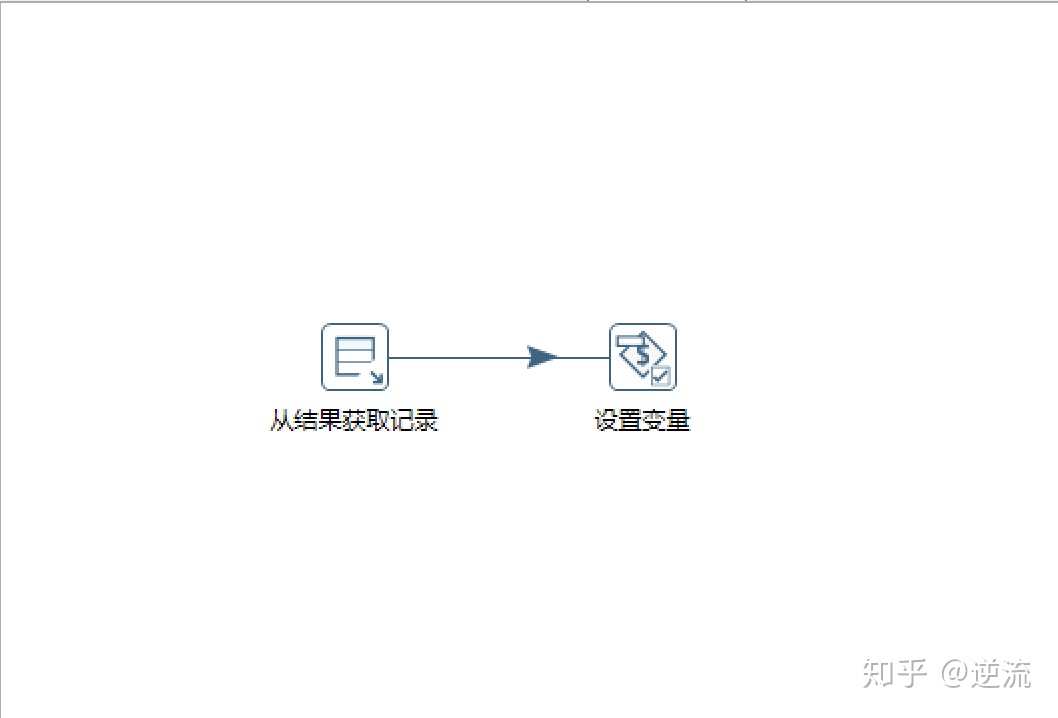
1.从结果获取记录
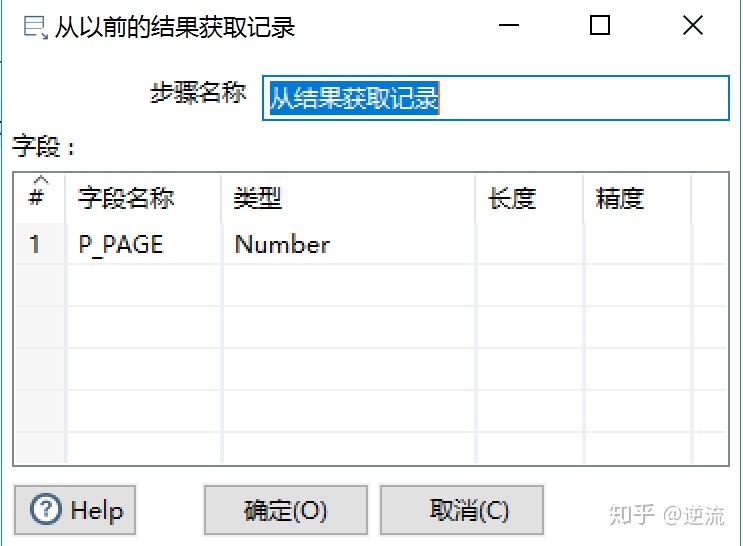
2.设置变量
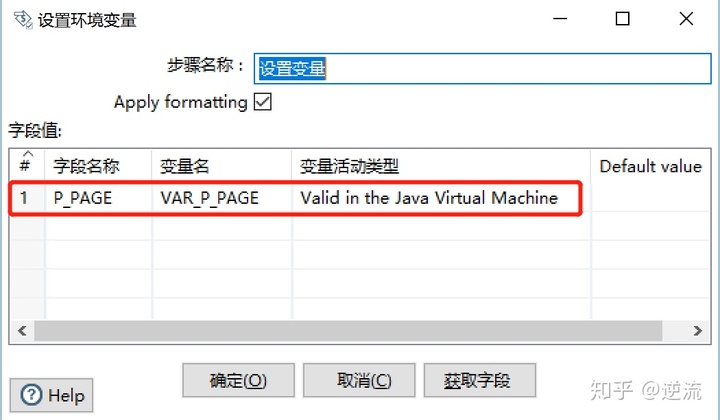
转换:获取变量加抽数
这里就是简单的表输出到表输出,但具体设置有一点区别。
表输入
这是最终版的设置,也就是说在设置完表输出之后,要回来将SQL设置成以下内容:
SELECT B.rn,B.* FROM
(
SELECT A.*, ROWNUM RN
FROM (SELECT * FROM table1) A
WHERE ROWNUM <= (${VAR_P_PAGE}*5000)
) B
WHERE RN >= ((${VAR_P_PAGE}-1)*5000+1)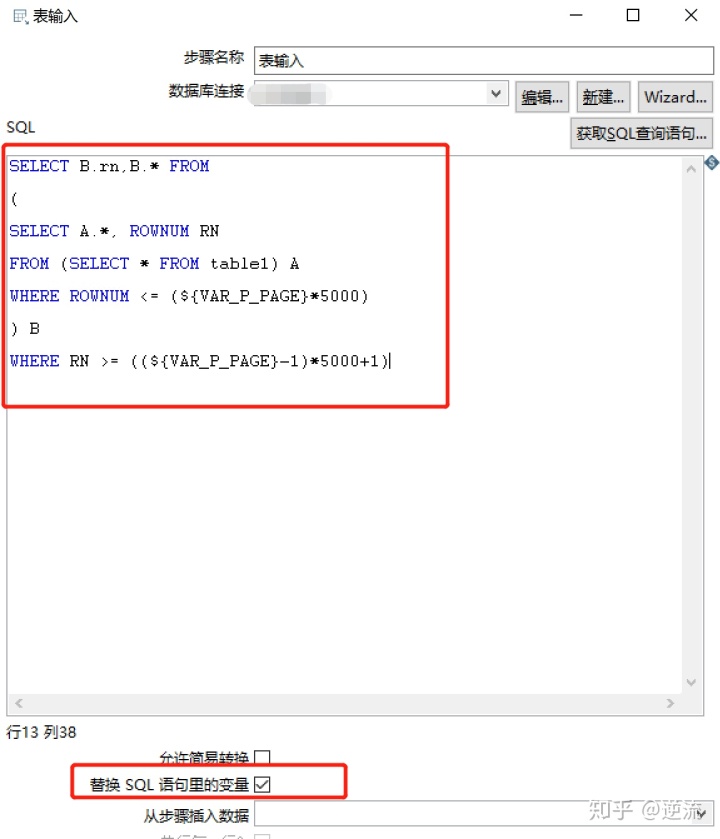
但设置表输出之前,要先把变量替换成1,不然无法获取表输出的对应字段。
SELECT B.rn,B.* FROM
(
SELECT A.*, ROWNUM RN
FROM (SELECT * FROM table1) A
WHERE ROWNUM <= (1*5000)
) B
WHERE RN >= ((1-1)*5000+1)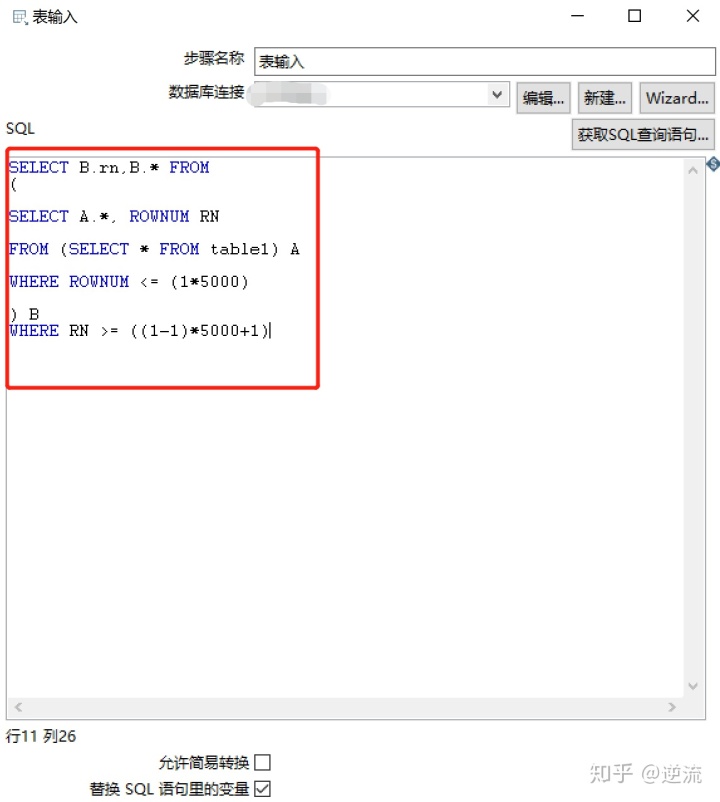
设置表输出中对应字段时,记住把多余的RN字段删除掉,然后回到表输出改成最终版即可。
最后还要记住,因为要遍历上一次的执行结果,主流程第二个作业要勾选执行每一个输入行
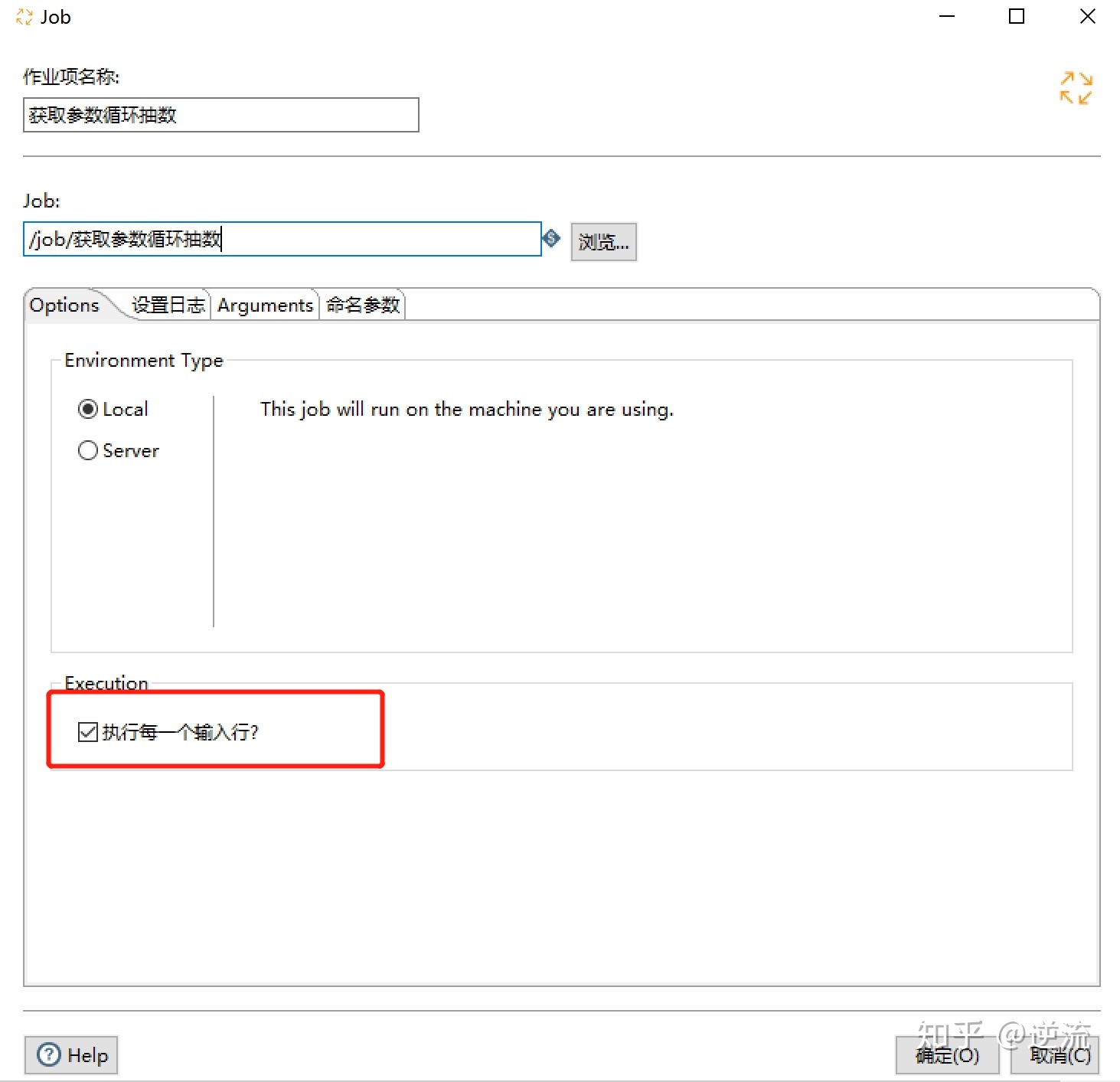
设置全部完成,可以开始跑作业了
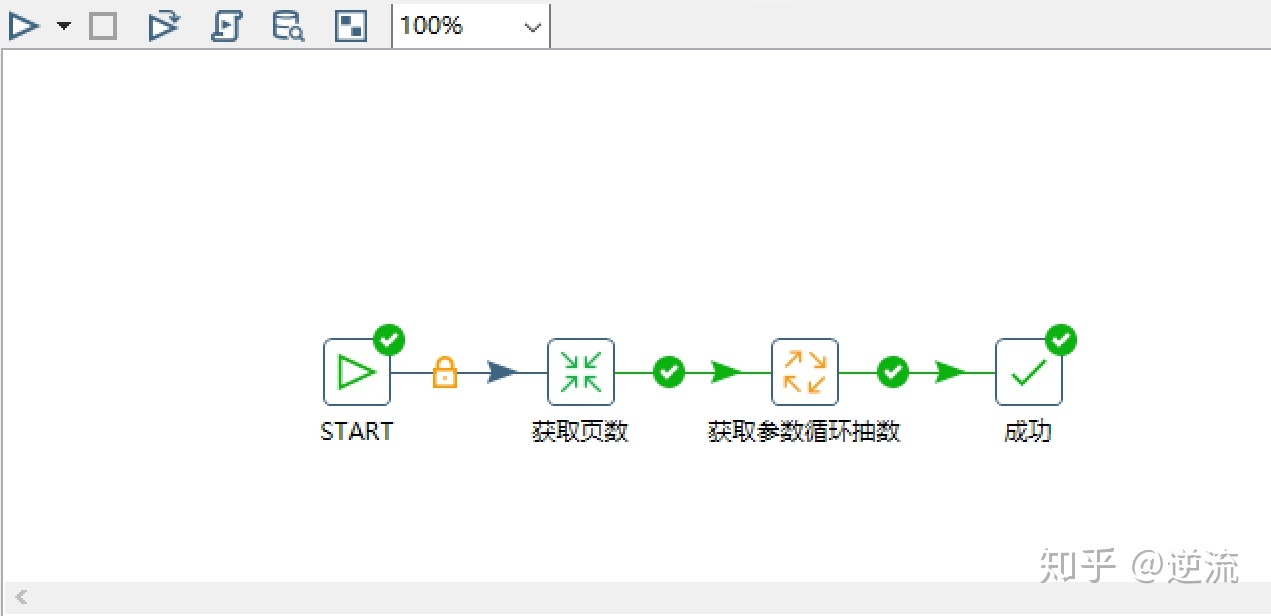
成果展示
经过分页循环的优化,我抽取2000W数据的表只用了30分钟左右,而直接进行抽取大概花费50分钟,且非常占用服务器内存。
对你有帮助的话,请点个赞
参考博文链接:采用Kettle分页处理大数据量抽取任务 - Grey Zeng - 博客园














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









