





在数据的处理过程中,一般都需要进行数据清洗工作,如数据集是否存在重复,是否存在缺失,数据是否具有完整性和一致性,数据中是否存在异常值等.发现诸如此类的问题都需要针对性地处理,下面我们一起学习常用的数据清洗方法.
重复观测处理
重复观测:指观测行存在重复的现象,重复观测的存在会影响数据分析和挖掘结果的准确性,所以在数据分析和建模之前需要进行观测的重复性检验,如果存在重复观测,
还需要进行重复项的删除
在数据的收集过程中,可能会存在重复观测的出现,例如通过网络爬虫,就比较容易产生重复数据.如下表,是通过爬虫获得某APP市场中电商类APP的下载量数据(部分)
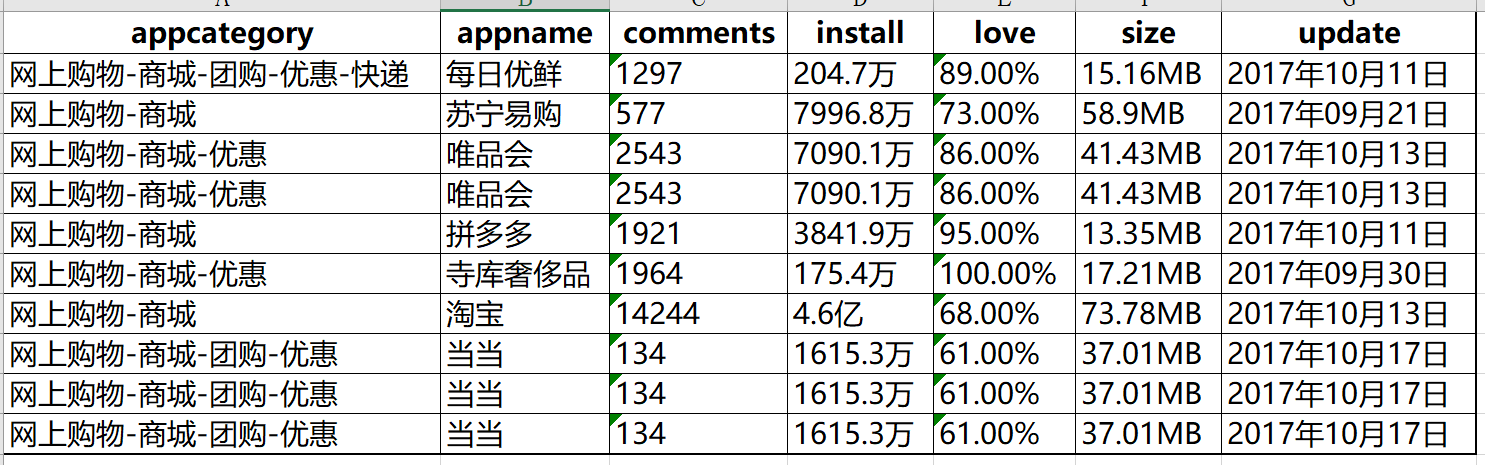
通过观测可以看出唯品会和当当出现了三次.如果收集上来的不是10行,而是10万行,甚至更多是,就无法通过肉眼的方式检测数据是否存在重复项了.
下面我们看用python怎么来处理重复项的检查,以及如何删除数据项中的重复项
代码:
import pandas as pd
df = pd.read_excel(r'D:\data_test04.xlsx')
print('数据集是否存在重复观测: \n',any(df.duplicated()))
out:
数据集是否存在重复观测:
True
代码就是简单的两行就处理好了
可以看出检测数据集的记录是否存在重复,使用duplicated (英文单词的意思就是重复,复制的意思)方法,但是该方法返回的是数据集每一行的检验结果,为了能够得到最直接的结果,可以使用any函数,该函数表示的是在多个条件判断中,只有一个条件为True,则any函数的结果就为True.正如结果所示,any函数的运用返回True值,说明
该数据集是存在重复观测的.
删除数据集中的重复观测:
df.drop_duplicates(inplace = True)
df
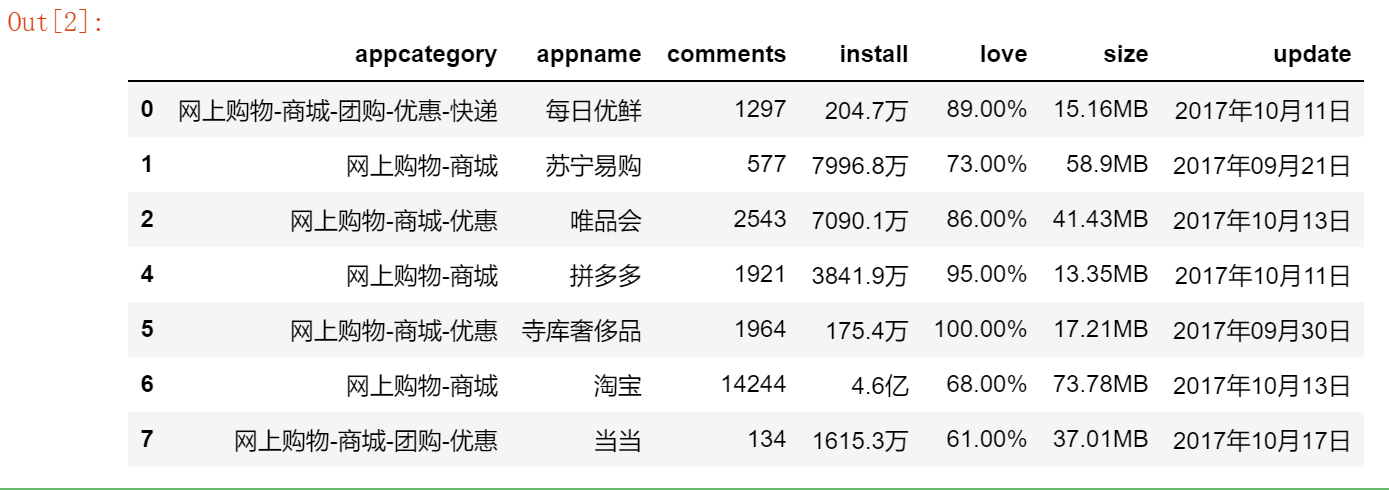
得出的结果如上图所示,原先的10行在派出重复项后得到7行,被删除的行号为:3,8和9.该方法中又有inplace参数,设置为True就表示直接在原始数据集上做操作
以上就是本次介绍的全部知识点,感谢大家对脚本之家的支持。














 3848
3848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









