







 本文详细介绍了2345公司在实时查询平台的升级过程中,如何利用Phoenix解决数据库异构、实时流Join等问题。通过引入Phoenix,实现了数据的高效存储和查询,避免了数据丢失和性能瓶颈。文章还探讨了Phoenix的索引优化策略,包括全局索引、本地索引、覆盖索引和函数索引,并分享了在数据铺底、补数、数据覆盖等方面遇到的挑战及解决方案。
本文详细介绍了2345公司在实时查询平台的升级过程中,如何利用Phoenix解决数据库异构、实时流Join等问题。通过引入Phoenix,实现了数据的高效存储和查询,避免了数据丢失和性能瓶颈。文章还探讨了Phoenix的索引优化策略,包括全局索引、本地索引、覆盖索引和函数索引,并分享了在数据铺底、补数、数据覆盖等方面遇到的挑战及解决方案。
本文介绍Phoenix在2345公司的实践,主要是实时查询平台的背景、难点、Phoenix解决的问题、Phoenix-Sql的优化以及Phoenix与实时数仓的融合思路。具体内容如下:
实时数据查询时客服系统中一个很重要的模块,提供全公司所有主要产品的数据的查询功能,由于各产品的数据库、数据表错综复杂、形式多样,在平台建设的初期走了很多弯路。本文后续会详细介绍实时数据查询迭代升级的过程、期间遇到的问题以及对应的解决方案。
目前公司的数据库类型主要有MySQL和MongoDB。它们本身是异构的,二者都会涉及分库、分表,还有冷表、热表。分库分表的字段不同、个数不同;冷热表的实现方式也不同,有些产品是冷热双写,有些则是热表过期插入到冷表;还有周表、月表、自定义分表逻辑等。
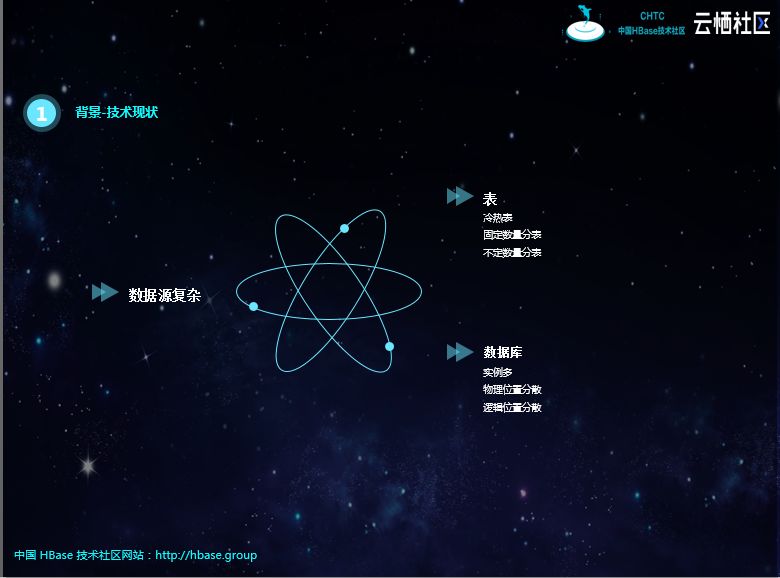
在物理位置上,这些数据库实例会分布在不同的节点,如果用JDBC查询需要配置不同的连接。再加上根据产品性质,一般会查询从库,而由于技术原因,从库的物理位置会变化,配置起来也会比较麻烦。
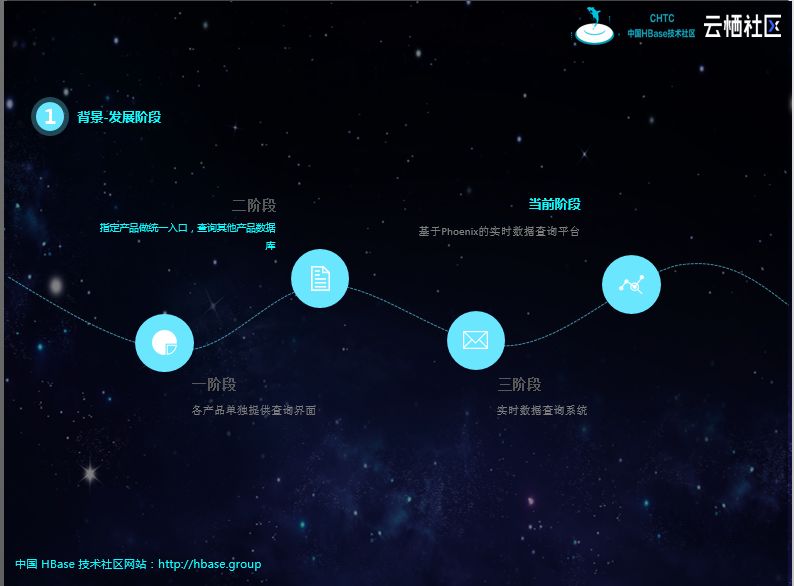
系统的迭代进程大概分为四个阶段。
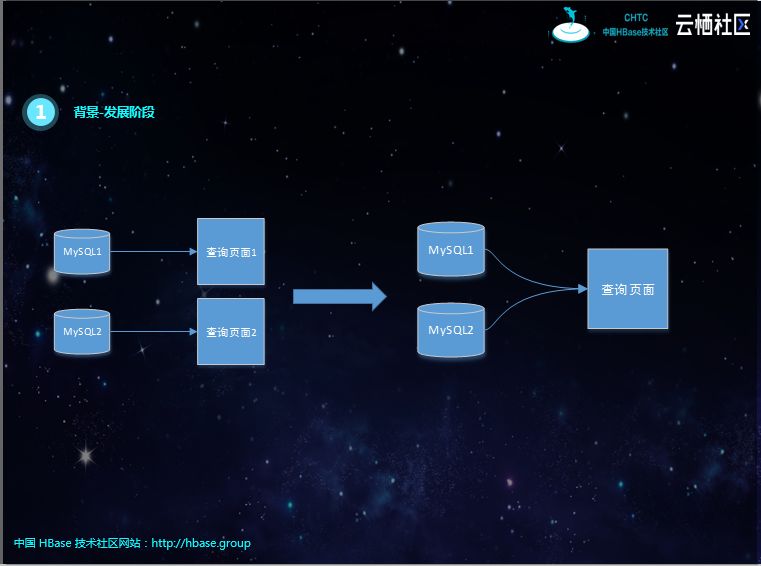
初期,产品少、数据库形式简单、库和表数量少,各产品单独提供查询页面。
后面各查询页面整合,提供统一的界面,但随着数据库、表结构形式复杂,开发任务逐渐变得繁重,难以为继。特别是查询条件复杂,需要上游业务表创建对应的索引,对业务具有一定的侵入性。
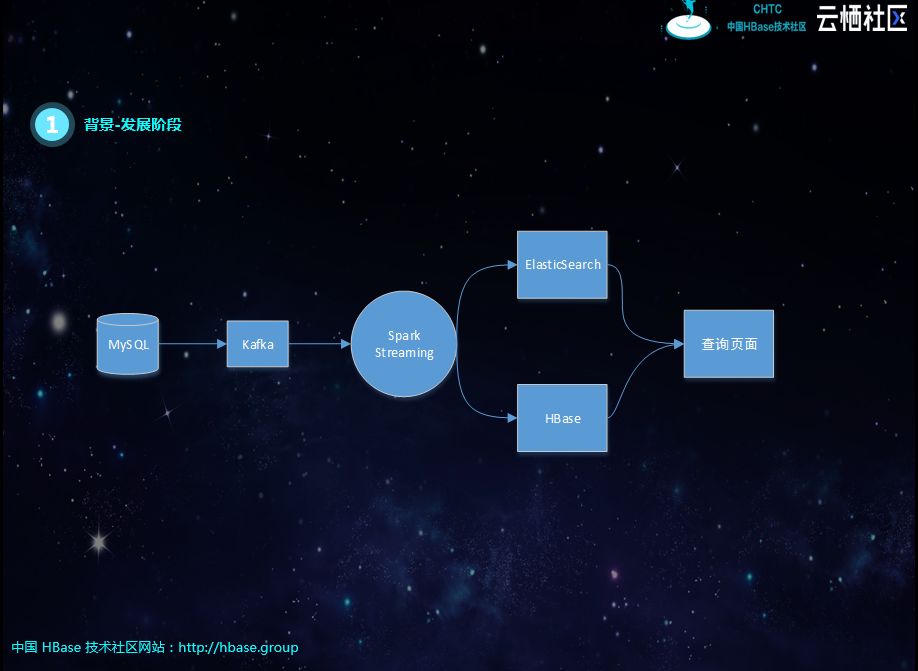
第三阶段,组件单独团队开发,将MongoDB、MySQL实时同步到Kafka,屏蔽分库、分表、冷热表等结构化差异,基于实时流的订阅机制,对数据进行聚合插入ElasticSearch和HBase。但会面临实时流Join,经常丢数据,造成数据不准;性能也跟不上,特别是新增查询表,需要全量铺底的时候。后期增加了T+1补数机制,虽然弥补了数据缺失的问题,但容易造成实时逻辑与离线逻辑不一致的问题。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









