






前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
喜欢的朋友欢迎关注小编,除了分享技术文章之外还有很多福利,私信学习资料可以领取包括不限于Python实战演练、PDF电子文档、面试集锦、学习资料等。
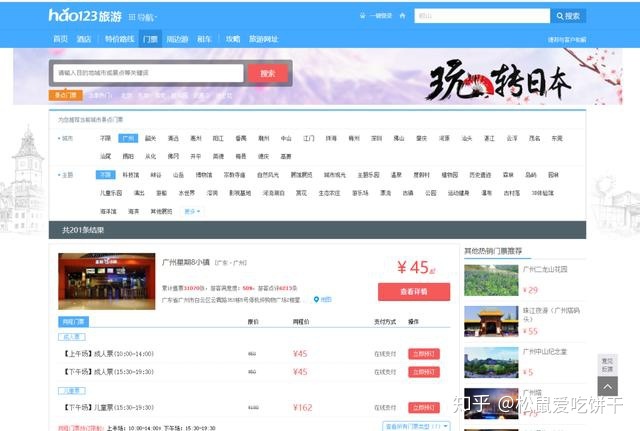
当我们出去旅游时,会看这个地方有哪些旅游景点,景点价格、开放时间、用户的评论等。
本文基于Python网络爬虫技术,以hao123旅游网为例,获取旅游景点信息。
项目目标
获取网站的景点名称、开放时间、精彩点评、价格等信息。
涉及的库和网站
先列出网址,如下所示:
网址:https://go.hao123.com/ticket?city=%E5%B9%BF%E5%B7%9E&theme=all&pn=1网址city=%E5%B9%BF%E5%B7%9E指的是广州这个城市、pn指的是页数。
需要用到的库:requests、lxml、pprint
具体实现
1. 导入我们需要的库
import requests
from lxml import etree
from pprint import pprint2. 导入库之后,我们定义一个class类,然后定义一个init方法继承self再定义一个主函数main,定义一个init方法:首先准备url地址,headers,如下图所示。

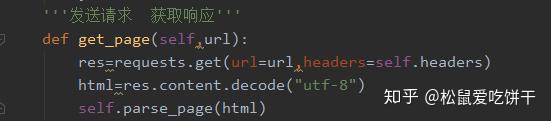
3. 定义一个请求函数,获取响应数据函数:
4. 请求到数据后,我们需要把这个数据进行解析:

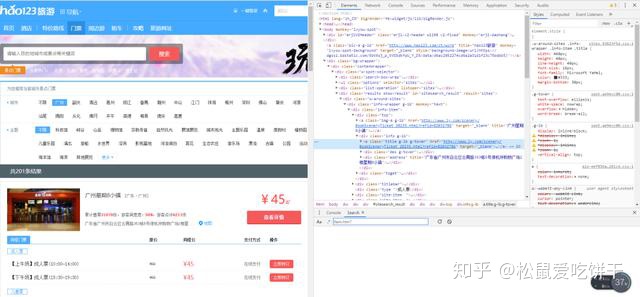
5. 获取景点名称二级页面链接:使用xpath查找链接路径用谷歌浏览器选择开发者工具或者按F12,选择Elements按数字1、2操作找到旅游景点名称二级页面链接。
6. 根据分析,我们可以撸下代码。
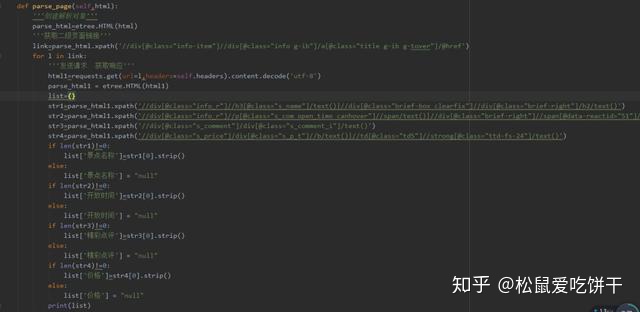
7. 获取二级页面链接后,发送请求获取响应,解析数据。定义一个字典,保存景点名称、开放时间、精彩点评、价格。使用判断语句判断里面内容是否是空的。
8. 最后定义一个main函数,如下图所示。

效果展示
点击绿色按钮运行,将结果显示在控制台,如下图所示。输入你要爬取的页数。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









