





第一次在知乎上发文章,缘由是上周末看到蓝色和杨军两位大佬对于TVM和XLA的非常有价值的讨论,还看到了高叔叔(多年计算库开发经验)关于自动代码生成和计算库bare-metal式优化的对比,感觉非常有意思,所以也想谈谈自己的看法。我的背景是GPU系统结构和算法加速,从去年开始接触TVM有小一年的时间。
这两篇文章里已经对TVM有了非常好的讨论,我想从下面几个方面谈一下:1)代码生成与自动代码生成;2)TVM和XLA的IR区别;3)TVM可能的应用场景;4)目前来看自动代码生成技术有待提高的地方。
1)代码生成与自动代码生成
代码生成是传统编译器后端模块之一,解决的问题是将优化后的机器无关IR,经过指令选择、寄存器分配和求值顺序等步骤,生成二进制机器代码。另外,传统编译器里将语法解析器到三地址表示转化的过程,也称为中间代码生成。那么我们来看一下TVM里的代码生成做了什么,TVM的输入为:tensor、一系列lambda表达式和相应的schedule,然后解析器生成中间表达,中间表达经过一系列编译优化,最后通过代码生成器产生相应的源代码或机器代码。事实上,对于NVIDIA GPU而言,有两种方式输出代码,一种是直接生成CUDA源码,另一种是通过LLVM生成PTX code,再经过cuda runtime driver编译成cubin代码。我们对比了这两种方式的性能差异,发现第一种方式,也就是仅生成源码的方式,性能甚至会比第二种高出一个数量级。所以,从这个意义上来看,我觉得TVM充当的角色应该是通过将计算和调度分离,在一个大的搜索空间内快速完成代码优化,而代码编译的工作还是应该交给设备提供商。所以,从代码生成的角度来看TVM,我觉得这里的代码生成更多的是将一个只有计算没有调度的代码,也就是 lambda表达式,通过一系列优化转化成一个拥有了一个好的调度的代码(例如输出的CUDA代码),当然这样做的前提也和Halide的一样,Halide自己的定位式DSL,TVM也需要有深度学习的计算多是Tensor类这种嵌套循环计算模式的大前提。从这个意义上来讲,我们将自动代码生成拆解成两部分来看,先看“自动”,我理解自动的意思是将schedule自动加到计算上,而不用人来手工进行优化操作;“代码生成”的意思是一种src2src的代码转化。
2)TVM与XLA的IR区别
a. TVM的IR主要针对嵌套循环优化,因此核心部分很清晰,下面节选了部分:
Program -> Stmt Program | Null
Stmt -> RealizeStmt |
ProduceStmt |
ForStmt |
AttrStmt |
IfThenElseStmt |
ProvideStmt |
LetStmt
Expr
Realize -> realize TensorVar(RangeVar) {Program}
ProduceStmt -> produce TensorVar {Program}
ForStmt -> for (IterVar, Expr, Expr) {Program}
AttrStmt -> TensorVar Attribute {Program}
IfThenElseStmt -> if (Expr) then {Program} |
if (Expr) then {Program} else {Program}
ProvideStmt -> TensorVar(Params)=Expr
LetStmt -> let ScalarVar=Expr {Program}
Expr -> Const |
TensorVar |
ScalarVar |
IterVar |
RangeVar |
Binary |
Unary |
Call 由parser生成IR之后,scheduler和lower部分不断对IR进行更新,生成的IR已经非常像一段源代码了,最后经过字符串拼接转换成CUDA源代码。因此,TVM IR的特点是专注在嵌套循环部分,有意保留嵌套循环之间的信息,然后不断更新嵌套循环关系以及与之相关的memory操作。
上述部分是TVM偏算子端的IR,偏计算图端的部分是Relay(NNVM的后继),Relay部分提供了DAG和A-Normal两种类型表达计算图的方式,其中A-Normal是lambda表达式计算续体传递风格(CPS)的一种管理性源码规约,分别供偏好于深度学习和计算语言的人员使用,两者是基本等价的。可以看到,TVM对于图部分的IR和算子部分的IR,有明显的分层。
b. XLA的IR
XLA的IR为HLO IR,HLO为High Level Optimizer的缩写,顾名思义,这一层的IR主要描述的是设备无关优化,而设备相关优化会借助LLVM后端来完成。HLO IR相比TVM IR最大的区别是:HLO IR中既表示DAG,又表示加减乘除这些细节的运算,以及相关的辅助功能,比如layout相关的reshape。TVM IR的分层标准是计算图和算子,而HLO IR的分层标准是设备无关和设备相关。
XLA IR在优化中,会将一些具名算子节点(BatchNormalization)直接替换为包含计算细节(+-*/),同时插入一些相关的add、multiply和maximum等节点;或者将另外的具名算子(Conv)替换为cuDNN API,并且插入相应的call、reshape等节点。接下来,会做一些fusion和dse等优化操作。更细致的讨论,我们稍后会以学习笔记的形式共享出来。以下是一些相关的优化总结:
1. optimization
zero_sized_hlo_eliminatioin
dynamic-index-splitter
gpu_hlo_support_checker
CallInliner
dot_decomposer
convolution-group-converter
stable-sort-expander
element_type_converter
simplification
batchnorm_expander
algsimp
simplify-sorts
tuple-simplifier
while-loop-constant-sinking
simplify-while-loops
slice-sinker
dce
reshape-mover
constant-folding
simplify-conditional
hlo-get-dimension-size-rewriter
zero_sized_hlo_elimination
transpose-folding
cse
dce
while-loop-trip-count-annotator
2. conv_canonicalization
consolver-rewriter
cudnn-conv-rewriter
cudnn-fused-convolution
cudnn-conv-padding
constant-folding
3. layout_assignment
layout-assignment
4. post-layout_assignment
algsimp
cudnn-conv-algorithm-picker
tuple-simplifier
cse
5. fusion
variadic-op-splitter
fusion (x2)
fusion_merger
multi_output_fusion
cse
dce
6. reduce-precision
7. GPU-ir-emit-prepare
dce
flatten-call-graph
copy-insertion
adding_copies_to_resolve_interference
removing_unnecessary_copies
adding_special-case_copies
sanitize-constant-names 3)TVM可能的应用场景
我们将TVM可能的应用场景分成了两种,一种是离线支持敏捷算子优化,通过TVM自动代码生成的功能,部分解放优化人员手动添加优化的负担。具体地,给定一个计算,优化人员进行workload characterization分析完计算访存pattern之后,可以拟定几种可能的优化方案,如果TVM的schedule中包含,那么可以直接应用TVM来生成包含该优化的代码。然后借助profiler来分析代码的瓶颈,进一步修正或者更新优化方案,再试图借助TVM的自动生成能力,如此循环往复。到最后,如果TVM代码的可读性足够的话,优化人员可以在其上做手动优化;如果可读性不好的话,TVM也可以帮助优化人员快速确定优化方案。
另外一种场景是,运行时代码生成。当研究员在试验新的算子时,由于没有可供调用的计算库,同时缺乏CUDA等高性能代码开发经验,因此很多情况下是通过裸跑python代码来调用新算子的。PyTorch已经在今年5月份开始将TVM接入到PyTorch中实现运行时代码优化编译,目前已经可以运行了。具体的方式如下图(来源于PyTorch/TVM的github):
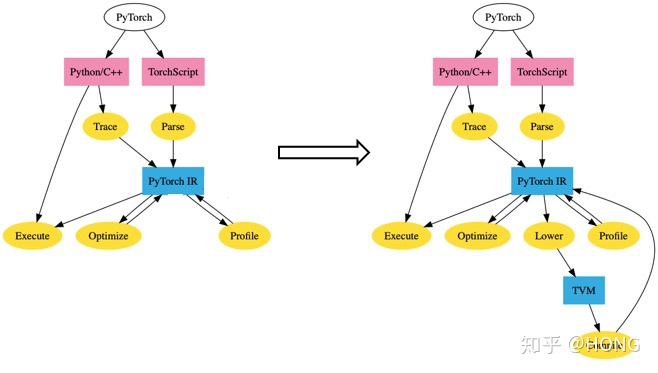
左图为PyTorch本来的编译优化流程,通过script和trace两种方式,进入到PyTorch IR优化流程中,IR进行优化之后,经由执行引擎来进行执行。右图为TVM接入的方式,通过修改PyTorch工程中script和trace的部分,将TVM IR以及相关优化勾到PyTorch IR上,因此首先需要一个Lower部分,做PyTorch IR到TVM IR之间的解析转化,然后通过TVM IR来做相应优化,最后在编译到PyTorch IR上。这样做的方式很像MLIR中将不同IR连通起来,合作优化的思路,不过这样连通两个IR已经有非常大的工程量,如果不同IR的数据结构和实现细节差异较大,多个IR的连通会非常困难,MLIR的部分还没有非常深入的研究,暂时不做过多评价。
4)目前来看自动代码生成技术有待提高的地方
自动代码生成技术目前仍然有许多需要完善的地方,以下几点是我个人的思考:
a. 目前TVM生成代码在多数情况下需要已知Tensor的形状,而这使得TVM被拿来做推理引擎以及JIT来使用。这个局限背后的原因是,在做各种各样的嵌套循环优化时会对循环的边界进行多次操作,如果循环边界未知的话,多次操作之后,对于循环边界的推断将变得非常麻烦,目前的区间分析技术,还不能完全胜任。因此,支持未知Tensor形状的代码生成,对于拓宽自动代码生成技术的应用非常重要,却又非常难做。
b. TVM需要人为来写schedule,这个问题在很多文章里都有提及,Halide和TVM也都做了很多尝试,auto-tuning更多的是去explore对应schedule的参数,如何高效地auto-schedule还是个开放问题。
c. 接上一条,polyhedron model是一个做auto-schedule的思路,不过从Tensor Comprehesion的例子来看,想把它用好还非常困难,在阅读相关源代码时,当时的contributor对里面的实现也并不满意,甚至会发出sigh的感叹。不过由于目前TVM对不完美循环,或者循环变量有依赖的情况没有办法处理,这种情况也可以考虑使用polyhedron model来做。
d. 进一步提高代码可读性
以上是我的一些思考,关于XLA IR、Glow IR和TVM IR到底哪一种更好,或者该如何协同使用,现有深度学习框架中的IR如何借鉴使用这些工作,都是非常开放的问题,最终会收敛到什么样子,现在还不能轻下判断。更多的深度学习编译器的实践、体会和学习笔记,供大家批评指正。















 2879
2879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









