





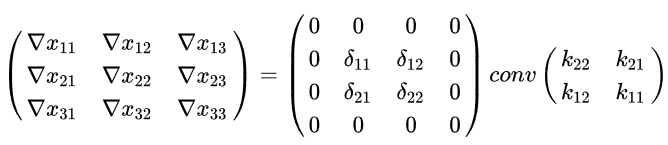
最好的学习方法就是把内容给其他人讲明白。
如果你看了我的文章感觉一头雾水,那是因为我还没学透。
CNN卷积层的反向传播相对比较复杂一点。
一、首先来看看前向传播算法
(1)单通道---极简情况
为了简单起见,设输入X为3* 3,单通道,卷积核K为2*2,输出Y为2*2,单通道。
这里
所以,卷积运算最终转化为矩阵运算。即X、K、Y变形在之后对应矩阵变为XC、KC、YC,则
Y和K只要reshape一下就可以了,但X需要特别处理,这个处理过程叫im2col(image to column),就是把卷积窗口中的数拉成一行,每行
#这是一个非常朴素的实现,优点是简单易懂,缺点是性能,可以慢到你想哭,后面再谈谈优化算法
def im2col(image, ksize, stride):
# image is a 4d tensor([batchsize, width ,height, channel])
image_col = []
for i in range(0, image.shape[1] - ksize + 1, stride):
for j in range(0, image.shape[2] - ksize + 1, stride):
col = image[:, i:i + ksize, j:j + ksize, :].reshape([-1])
image_col.append(col)
image_col = np.array(image_col)
return image_col(2)多通道---真实情况
下面是一张被广泛引用的说明图,图中显示的输入是3通道(3层,比如R、G、B共3个channel),输出是2通道(channel),于是总共有3*2=6个卷积核,每个核有4个元素,3*4=12,所以6个卷积核排成一个12*2的核矩阵,即为权重矩阵,把这6个KC的组合(权重矩阵)记为WC(^_^)。
图中最底下一行表示两个矩阵乘积运算,就是卷积层的前向传播算法。实际编码时还会加上偏置,而且还要考虑Batchs。
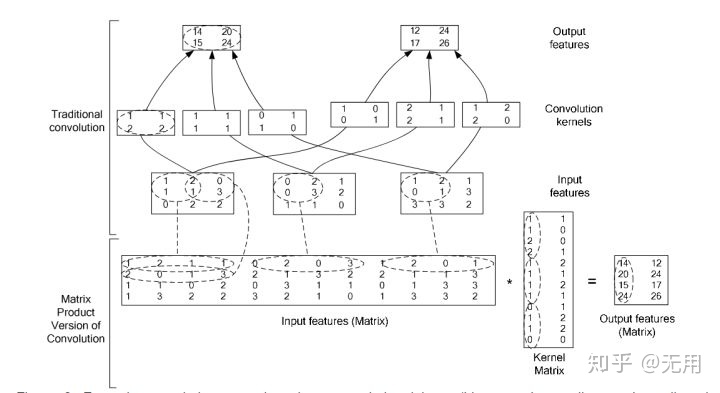
图中显示,如果
那么,这个图显示的矩阵乘法的维度是:
然后
如果
二、反向传播
反向传播只与前向传播相关,在看完了前向传播之后,我们来看反向传播。
为了书写方便,记
1、
这跟全连接网络没多大区别。
2、求
根据反向传播公式,
但是, 从
根据前向传播
可以计算每个
所以
设上面三个矩阵分别为
从而可见
还是一个卷积计算。
不过是对
计算过程:
(1)把
(2)把K映射到
方法一:做中心对称(旋转180度),flipup(fliplr(K))(先左右对称,再上下对称),再reshape得到
方法二:先reshape,再在这个维度上取逆序。请看代码片段:
#self.weights维度为(k,k,self.input_channels, self.output_channels)
#方法一
# flip_weights = np.flipud(np.fliplr(self.weights))
# flip_weights = flip_weights.swapaxes(2, 3)
#方法二
flip_weights=self.weights.reshape([-1,self.input_channels,self.output_channels])
flip_weights=flip_weights[::-1,...]
flip_weights = flip_weights.swapaxes(1, 2)
#以下相同
col_flip_weights = flip_weights.reshape([-1, self.input_channels])注:在numpy文档中已经说明:flipud(m)等价于m[::-1,...],等价于flip(m,0),而fliplr(m)等价于m[:,::-1,...],等价于flip(m,1)。显然flip(m,i)和“::-1”这个操作可以作用到任何维度上,所以更加灵活。
(3)由
计算
三、
卷积核为
此时
所谓的图片的通道(channel)就是图片的深度(depth)。
一张图片其实是三维的立体:高度、宽度、深度,shape是(heigth,width,depth),其中(heigth,width)构成一张图片的一层,比如有R、G、B就有三层,depth=3,或者说channel=3.
输入X(h,w,d)-->变换到
再把 输出
可见
四、same和valid
正常情况下(valid),一个大小为
例如:
(5,5)--conv(5,5)-->(1,1)
(5,5)--conv(3,3)-->(3,3)--conv(3,3)-->(1,1)
结论是:一个conv(5,5)相当于两个conv(3,3),但是一个conv(5,5)有25个参数,两个conv(3,3)只有18个参数,所以节省25-18=7个参数。
再如:
(11,11)--conv(11,11)-->(1,1)
(11,11)--conv(3,3)-->(9,9)--conv(3,3)-->(7,7)--conv(3,3)-->(5,5)--conv(3,3)-->(3,3)--conv(3,3)-->(1,1)
可见一个conv(11,11)相当于5个conv(3,3),而11*11-5*3*3=76,所以现在一般倾向于用小的卷积核,但多弄几层。
但是层数多了会产生梯度消失或爆炸,这个问题被残差神经网络(ResNet)很好的解决了,残差神经网络搞上千层都没问题。
但是,ResNet由于每隔两层要直接加X(input),所以要保持大小不变(same)。
卷积完了要保持大小不变(same),就是在四周填充0(padding),比如宽度从w减少到w-k+1,减少了k-1,所以在两边各填充(k-1)/2个0,从而k必须是奇数。所以现在看到的卷积核基本都是(3,3)。上面已经讨论过(1,1)卷积主要作用是整形,改变图片深度。
另外,ResNet由于每隔两层要直接加X,必然会梯度爆炸,所以必须有一个BatchNormal层,对数据正则化,下一篇讨论BatchNormal的反向传播。
五、速度优化
卷积层的绝大部分(几乎全部)时间都耗在im2col上,所以其他优化措施作用都很小。
1、把涉及batch的循环用矩阵乘法代替,可以减少10%不到的时间:
def forward(self, x):
col_weights = self.weights.reshape([-1, self.output_channels])
if self.method == 'SAME':
x = np.pad(x, (
(0, 0), (self.ksize // 2, self.ksize // 2), (self.ksize // 2, self.ksize // 2), (0, 0)),
'constant', constant_values=0)
self.col_image=im2col(x, self.ksize, self.stride)
conv_out =np.dot(self.col_image, col_weights) + self.bias
conv_out= np.reshape(conv_out,np.hstack(([self.batchsize], self.eta[0].shape)))
return conv_out
def gradient(self, eta):
self.eta = eta
col_eta = np.reshape(eta, [ -1, self.output_channels])
self.w_gradient = np.dot(self.col_image.T,
col_eta).reshape(self.weights.shape)
self.b_gradient = np.sum(col_eta, axis=0)
# deconv of padded eta with flippd kernel to get next_eta
if self.method == 'VALID':
pad_eta = np.pad(self.eta, (
(0, 0), (self.ksize - 1, self.ksize - 1), (self.ksize - 1, self.ksize - 1), (0, 0)),
'constant', constant_values=0)
if self.method == 'SAME':
pad_eta = np.pad(self.eta, (
(0, 0), (self.ksize // 2, self.ksize // 2), (self.ksize // 2, self.ksize // 2), (0, 0)),
'constant', constant_values=0)
flip_weights=self.weights[::-1,...]
flip_weights = flip_weights.swapaxes(1, 2)
col_flip_weights = flip_weights.reshape([-1, self.input_channels])
col_pad_eta=im2col(pad_eta, self.ksize, self.stride)
next_eta = np.dot(col_pad_eta, col_flip_weights)
next_eta = np.reshape(next_eta, self.input_shape)
return next_eta
def im2col(image, ksize, stride):
# image is a 4d tensor([batchsize, width ,height, channel])
image_col = []
for b in range(image.shape[0]):
for i in range(0, image.shape[1] - ksize + 1, stride):
for j in range(0, image.shape[2] - ksize + 1, stride):
col = image[b,i:i + ksize, j:j + ksize, :].reshape([-1])
image_col.append(col)
image_col = np.array(image_col)
return image_col2、换掉im2col方法
im2col是最常用的方法,比如caffe也是用这种方法。
不过有的研究表明,winograd方法可能更快,不过我还不懂,还请移步百度吧。
参见:
卷积神经网络中的Winograd快速卷积算法 - Mr-Lee - 博客园www.cnblogs.com
3、使用numpy的as_strided函数实现im2col,
def split_by_strides(self, x):
# 将数据按卷积步长划分为与卷积核相同大小的子集,当不能被步长整除时,不会发生越界,但是会有一部分信息数据不会被使用
N, H, W, C = x.shape
oh = (H - self.ksize) // self.stride + 1
ow = (W - self.ksize) // self.stride + 1
shape = (N, oh, ow, self.ksize, self.ksize, C)
strides = (x.strides[0], x.strides[1] * self.stride, x.strides[2] * self.stride, *x.strides[1:])
return np.lib.stride_tricks.as_strided(x, shape=shape, strides=strides)def forward(self, x):
if self.method == 'SAME':
x = np.pad(x, (
(0, 0), (self.ksize // 2, self.ksize // 2), (self.ksize // 2, self.ksize // 2), (0, 0)),
'constant', constant_values=0)
conv_out=self.split_by_strides(x)
conv_out=np.tensordot(conv_out,self.weights, axes=([3,4,5],[0,1,2]))
return conv_out在np里这样可以大大提升性能,图片比较大的时候可以达到100X的性能提升
详情请看
永远在你身后:卷积算法另一种高效实现,as_strided详解zhuanlan.zhihu.com4、使用CUDA实现,比如用pycuda或numba加速。不过话又说回来了,用numpy写不就是为了算法简单透明吗,当性能优先需要用到CUDA加速的时候,还有什么理由不用pytorch或者TensorFlow呢?
五、参考:
(1)卷积神经网络(CNN)反向传播算法
(2)反向传播原理 & 卷积层backward实现<一>
(3)
sebgao/cTensorgithub.com
(4)
leeroee/MNNgithub.com
(5)
ddbourgin/numpy-mlgithub.com
六、源码:https://github.com/fmscole/backpropagation















 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









