





数据结构 list 的详细实现及其相关算法

从向量到列表
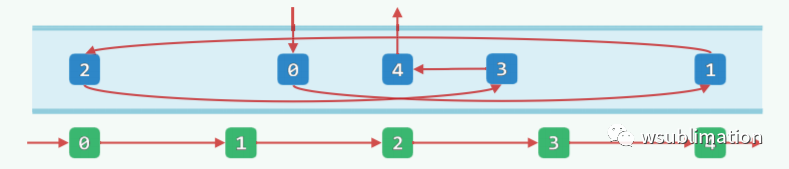
通过指针或引用彼此连接,在逻辑上构成一个线性序列 相邻节点互称为前驱和后继,没有前驱或后继称作首和末节点
也有秩,但是寻秩访问就会变得特别慢,因为物理空间并不连续,转用节点之间的相互引用找到特定的元素
接口与实现
列表节点 ListNode 模板类
#define position(T) ListNode*
template <typename T> //简洁起见,完全开放而不过度分装
struct ListNode { //列表节点模板类(以双向链表的形式实现)
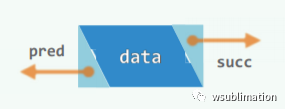
T data; //数值
position(T) pred; //前驱
position(T) succ; //后继
ListNode() {} //针对 headeer 和 trailer 的构造
ListNode(T e, position(T) p = NULL, position(T) s = NULL)
: data(e), pred(p), succ(s) {}
//默认构造器
position(T) insert_as_pred(T const& e); //前插入
position(T) insert_as_succ(T const& e); //后插入
}
列表 ADT 接口

作为列表的基本元素,列表节点首先需要独立的“封装”实现
为此,可设置并约定若干基本的操作接口
列表:list 模板类
#include "ListNode.h" //引入列表节点类
template <typename T>
class List {
private:
int _size; //规模
position(T) header; //头尾哨兵节点
position(T) trailer;//这两个对外不可见
protected: /*内部函数*/
public:
/*构造函数,析构函数,只读接口,可写接口,遍历接口*/
};

构造空列表
template <typename T>
void List::init() {
header = new ListNode; //创建两个 ListNode 模板类空间
trailer = new ListNode;
header->succ = trailer ;header->pred = NULL; //互联
trailer->pred = header;
trailer->succ = NULL ; //互联
_size = 0; //记录当前规模
}无序列表
无序列表的相关算法
重载 []
实现通过秩读取元素
template <typename T> //效率十分低下,可以偶尔为之
T list::operator[](Rank r) const {
Position(T) p = first();while (0 p = p->succ;return p->data; //目标节点
} //任一节点的秩,等于他的前驱总数查找算法
在节点 p(可能是 trailer)的第 n 个(真)前驱中,找到等于 e 的最后者
template <typename T> //顺序查找,O(n)
position(T) List::find(T const& e; int n; position(T) p) const {while (0 //从右向左逐个将 p 的前驱与 e 进行比对if (e == (p->pred)->data)return p; //命中return NULL; //若越出左边界,意味着查找失败
}当存在多个相同元素时也满足返回最后一个元素
可以有参数顺序不同的两种接口 find(e,n,p) find(e,p,n) , 函数参数的显式功能语义要和实际意义一样
插入算法

template <typename T>
position(T) List::insert_before(position(T) p, T const& e) {
_size++;return p->insert_as_pred(e); // e 当作 p 的前驱插入
}前插入算法(后插入算法与其对称)
template <typename T>
position(T) ListNode::insert_as_pred(T const& e) {
position(T) x = new ListNode(
e, pred,this); //为传入的新变量创建一个 position 空间,同时使用默认构造器初始化 x//ListNode(T e, position(T) p = NULL, position(T) s = NULL) : data(e), pred(p), succ(s) {}// pred 为新变量前驱 this 为新变量后继
pred->succ = x;
pred = x;return x; //重置连接,返回新节点位置//完整的一个 link 需要两次绑定 Don't lose the link;
}像微创手术一样,不会影响其他变量的位置和整体结构,所以插入数据的速度就比向量更快
基于复制的构造
template <typename T> //基本接口
void List::copyNodes(position(T) p, int n) { // O(n) 从 p 开始的 n 个节点
intit(); //创建头尾哨兵并作初始化while (n--) { //将起自 p 的 n 项依次作为末节点插入
insert_as_last(p->data);
p = p->succ;
}
}
insert_as_last = insert_before_trailer删除和析构
删除节点,微创手术型,常数时间内完成
template <typename T>
T List::remove(position(T) p) {
T e = p->data; //备份
p->pred->succ = p->succ;
p->succ->pred = p->pred; //和电线一样的感觉delete p;
_size--;return e;
}析构函数
template <typename T>
List::~List() {
clear(); //清空列表中的所有可见节点delete header;delete trailer; //释放头尾哨兵节点
}template <typename T>int List::clear() {int old_size = size;while (_size > 0)
remove(header->succ);//remove 函数中存在了 size--//因为 remove 函数中已经对 size 进行了自减操作,所以此 while 循环中不用写//size--操作return old_size;
} // o(n), 线性正比于列表规模唯一化
剔除重复元素
template <typename T>
int List::wuxu_weiyi() {if (_size 2)return 0; //两节点列表不可能重复int old_size = _size; //记录原规模
position(T) p = first();
Rank r = 1;// p 从首节点开始,依次直到末节点while (trailer != (p = p->succ)) {
position(T) q = find(p->data, r, p); // p->data==e//在 p 的 r 个前驱中查找与之雷同者
q ? remove(q) : r++; //若的确存在,则删除之,否则秩递增
}return old_size - _size; //返回被删除元素总数
}删除的是前面的元素 q,而不是后面的 p,删除 q 是更加安全的方法
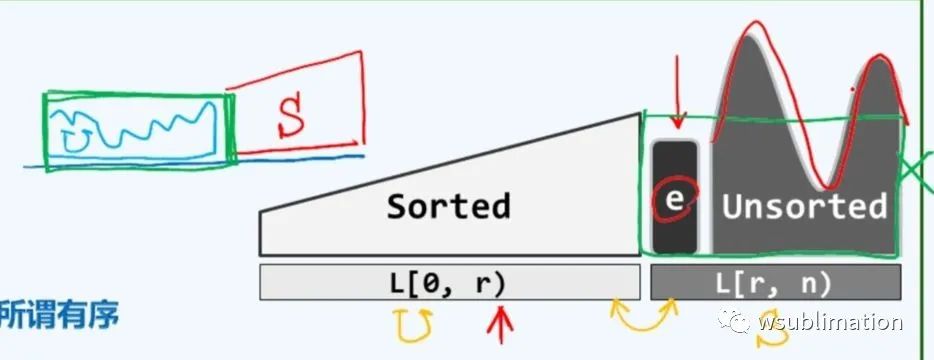
有序列表
唯一化
按照大小关系有序排列,故可以更快的完成
通过 remove 接口多次操作雷同节点,保留同一区间的首节点
template <typename T>
int List::uniquify() {if (_size 2)return 0; //确保包含两个元素int old_size = _size;
ListNodePosi(T) p = first();
ListNodePosi(T) q;// p q 为两个节点,p 为各区段起点,q 为其后继while (trailer != (q = p->succ)) //反复考察 p 的后继是否为 trailerif (p->data != q->data)
p = q; //若后继和本身互异,则转向下一有序区段else
remove(q); //相等的话就将后继 q 移除return ols_size - _size; //返回被删除量
} //只需遍历一遍 list remove 操作也不会对其他元素有影响 (faster),
时间完成,因为删除极快,删除时不需要额外的遍历
查找
template <typename T> //在有序列表 p 的 n 个前驱中
position(T) List::search(T const& e, int n, position(T) p) const {while (0 //从右向左 逐个将 p 的前驱与 e 进行比对if (e == (p->pred)->data)break;return p; //直至命中、数组越界后返回最终查找位置
}复杂度正比于区间宽度,列表有序无序的查找算法复杂度无太大区别
选择排序
每一次挑选一直挑选最大的元素 (selection_sort)

bubble_sort 其实也是不折不扣的 selection_sort,每次都挑选一个最大的将数据分成两个区间
->
函数实现
//对列表中起始位置为 p 的连续 n 个元素做选择排序
template <typename T>
void List::selection_sort(position(T) p, int n) {
position(T) head = p->pred; // head 不变,为位置 p 的前一个位置
position(T) tail = p; // tail 可能每次向前移动一个节点for (int i = 0; i tail = tail->succ;
} //循环 n 次 将 tail 指向 p+n 的位置,因为不能直接操作+nwhile (n > 1) { //反复从待排序区间内找出最大者,并移至有序区间前端
insert_before(tail, remove(selection_max(head->succ, n)));//从 head 后继的 n 个元素中选择一个最大元素,并通过 insert_before//移至有序区间前端
tail = tail->pred;
n--; //待排序区间 tail 前移一位,有序区间的范围缩小一位
}
}
因为 insert 操作和 remove 操作会用到 new 和 delete 操作,动态分布内存的时间大概是基本操作的 100 倍。所以实际中应该尽量少使用
所以最简洁的那句 insert_before(tail,remove(selection_max(head->succ,n))); 其实应该换为更加简洁的操作(更改两处的引用链接,或者直接交换有序块第一位和无序块最大位的数据域)
当最后 max 值刚好为 tail 值就不用执行那一次多余的移动操作,但因为这种情况出现概率极低,所以会得不偿失 !
selection_max 函数实现
template <typename T>
position(T) List::selection_max(position(T) p, int n) {
position(T) max = p; //暂定一下为 pfor (position(T) current = p; 1 //后续节点逐一与 max 进行比较//如果不小于,更新 maxif (not_less_than((current = current->succ)->data, max->data)) {
max = current;
} // painter's algorithm , 并且刚刚好选中的是后面的最大元素
}return max; // PS:// 我以后写变量名就要用全称,这样简写除了代码短一点点以外没有任何好处,读起来太难受了
}//painter's algorithm 画!

性能
相比于冒泡排序优化的时间是交换数据域的时间,由 n 变成了 1
selection_max 算数级数remove 和 insert_before 均为
总体复杂度仍为 尽管如此,元素的移动操作远远少于起泡排序,也就是主要来自比较操作,成本相对更低
插入排序
一个习以为常的算法,我们通常用来排序扑克牌,找一个差不多大小的位置,进行插入
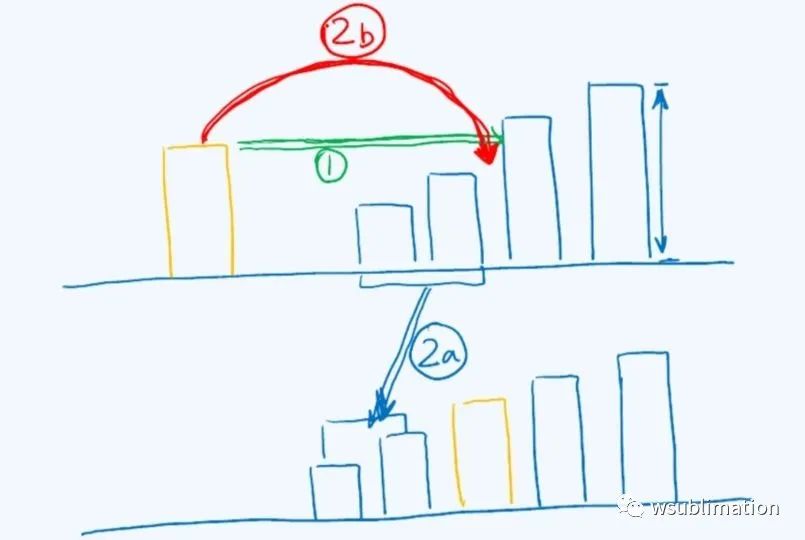
插入动作既是名字由来
并且由于是列表,插入一个元素的行为就会更加快速
与选择排序
后面元素有多大和此前归入列表中的元素无任何关系,且对未排序的元素没有任何限制(数量,大小)
e插入红色箭头的位置,左为选择排序,右为插入排序
实现
//对列表中起始于位置 p 的连续 n 个元素做插入排序
template <typename T>
void List::insertion_sort(position(T) p, int n) {for (int r = 0; r insert_after(search(p->data, r, p), p->data);// search 函数 R-P 找到不大于 p->data 的最后一个位置,insert_after 将 p 插入
p = p->succ;
remove(p->pred); //转向下一节点
} // p 为需要插入的那张排
} // n 次迭代,每次 O(r+1)仅使用 O(1) 的辅助空间,属于就地算法
性能
完全有序时,需要 O(n) 的复杂度,线性时间内完成,最坏还是
当查找算法使用向量 binsearch 时,使用向量虽然查找比较速度会变为 , 但是当在物理空间上将新元素插入到查找出来的位置时,就会变得很慢很慢
所以改用向量使用此算法就于事无补了
逆序对
如果逆序对规定为后一个元素的属性,那么每次插入一个元素时的比较次数就和逆序对的个数相等 所以每次插入排序的比较次数总和等于每个元素逆序对数的总和
所以插入排序属于,输入敏感算法,对性能影响非常大















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









