





 本文介绍了Python数据分析库Pandas中Index.get_loc()函数的使用方法,该函数能够帮助用户快速定位索引标签的位置,并提供了不同情况下的处理方式。
本文介绍了Python数据分析库Pandas中Index.get_loc()函数的使用方法,该函数能够帮助用户快速定位索引标签的位置,并提供了不同情况下的处理方式。
Python是进行数据分析的一种出色语言,主要是因为以数据为中心的python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas Index.get_loc()函数返回所请求标签的整数位置,切片或布尔掩码。该函数适用于已排序索引和未排序索引。如果传递的值不存在于索引中,它将提供各种选项。仅当对索引标签进行排序时,才可以选择将上一个值或下一个值返回为传递的值。
用法: Index.get_loc(key, method=None, tolerance=None)
参数:
key:标签
method:{None,“ pad” /“ ffill”,“ backfill” /“ bfill”,“ nearest”},可选
->default:仅完全匹配。
->垫/填充:如果不完全匹配,请找到PREVIOUS索引值。
->回填/填充:如果不完全匹配,则使用NEXT索引值
->nearest:如果不完全匹配,则使用NEAREST索引值。首选较大的索引值可以打破捆绑距离。
返回:loc:int如果唯一索引,则切片,如果单调索引,否则为mask
范例1:采用Index.get_loc()函数查找传递值的位置。
# importing pandas as pd
import pandas as pd
# Creating the Index
idx = pd.Index(['Labrador', 'Beagle', 'Labrador',
'Lhasa', 'Husky', 'Beagle'])
# Print the Index
idx
输出:
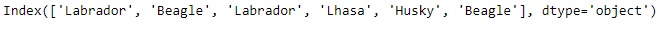
让我们找出“拉萨”在索引中的位置。
# Print the location of the passed value..
idx.get_loc('Lhasa)
输出:

正如我们在输出中看到的,Index.get_loc()函数已返回3,表示传递的值存在于索引中的此位置。
范例2:采用Index.get_loc()函数查找传递值的位置。如果传递的值不存在于索引中,则返回刚好小于传递的值的先前值的位置。
# importing pandas as pd
import pandas as pd
# Creating the Index
idx = pd.Index([1, 2, 3, 14, 25, 37, 48, 69, 100])
# Print the Index
idx
输出:
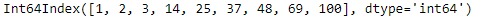
让我们找到值33在索引中的位置。
# Find the position of 33 in the index.
# If it is not present then we forward
# fill and return the position of previous value.
idx.get_loc(33, method ='ffill')
输出:
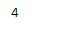
如我们所见,函数返回了输出3。由于索引中不存在33,但按排序顺序,刚好小于33的值为25,其位置为4。因此,输出为4。如果未设置方法参数,则如果不存在该值,则会导致错误。

















 802
802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









