







申明:
我不是大神,更不是爬虫大神,题目我也写好申明,仅仅适合入门级别的,对爬虫感兴趣的人员,虽然我分享了很多Python书籍,但我本人真的无法全部带领大家学习,所以,只能有多大力气,干多少事情,希望各位理解。(如果涉及到网站,我本人学习,探究时,对网站产生了不利影响,希望及时通知我,私信我,我会及时修改,重新发布,本文仅仅时学习使用,不针对任何网站,不大规模收集任何网页数据,中国的教育,有很多人需要廉价的、免费的、高质教育,希望本文可以尽心尽力,码字可能会慢,但希望大家督促!共同成长,进步)
目的:
帮助有Python基础的同学,朋友,学玩基础的人,不知道干嘛,指明一条道路。码字不易,不需要你捧钱场,如果你感觉有用,收藏起来,和我一起学习,也请各位网络大神,尊重原创。
爬虫主要分为两种:web端爬虫、app端爬虫
何为爬虫,简单来说,就是发送一个请求到服务器,服务器返回对应的网页源码,利用网页规则进行解析,提取,拿到对应的数据。就这么简单,对,说起来就这么简单!
- 以百度为例
1.采集百度网首页
# requests 模块,需要自行安装
import requests
# 百度网址
url = 'https://www.baidu.com/'
# 发送一个get请求
tem = requests.get(url)
# 拿到请求的文本信息
result = tem.text
# 将文本信息写到‘baidu.html’文件里
with open('baidu.html', 'w', encoding='utf8') as f:
f.write(result)此时,你右击以记事本打开“baidu.html”文件时,你会发现,有乱码的情况出现,如下图所示:

双击打开baidu.html文件时,会出现如下图所示的页面:

显然,这不是我们想要的,如何解决?(headers)
import requests
url = 'https://www.baidu.com/'
# 新添加一个headers字典就好了
# 目的是告诉百度,我是浏览器访问的
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 将headers放入到requests模块中
# 新添加了一个timeout,防止访问失败,程序卡顿
tem = requests.get(url, headers=headers, timeout=10)
result = tem.text
with open('baidu.html', 'w', encoding='utf8') as f:
f.write(result)
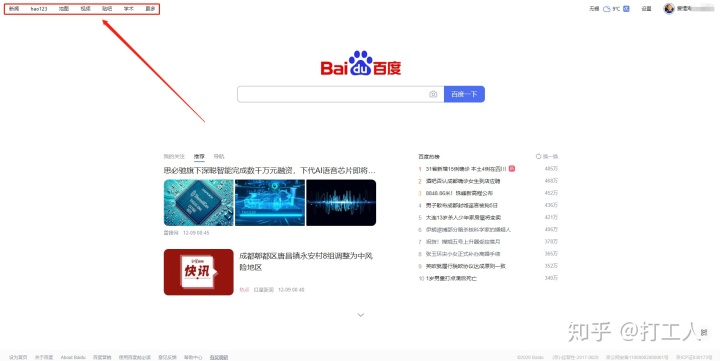
此时,重复上面的打开步骤,你会发现,字正常了,如下图:

双击打开baidu.html文件时,会出现如下图所示的页面:
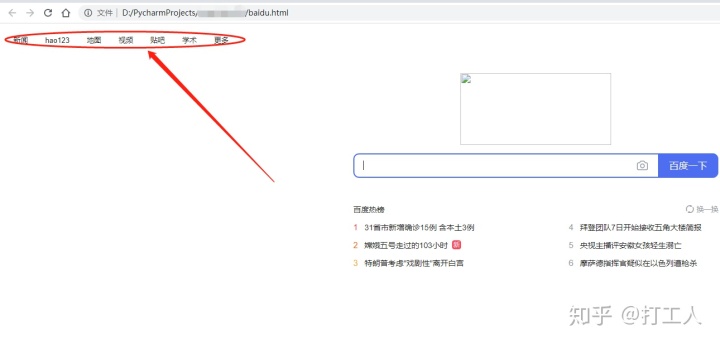
简直是完美,值得注意的是,我新添加了两个参数,headers和timeout
headers:模拟浏览器请求,属于爬虫里最基础的反爬手段
timeout:超时参数,防止访问超时,依然在那里访问,设置10,说明,10s到时,还未拿到结果,就放弃,和谈恋爱一样,不能死缠烂打,要适可而止,互相尊重,换个新的,或者隔断时间再访问一下,看看有没有新的变化,也许,她突然爱上你了呢,突然你就拿到数据了呢~
2.提取百度首页部分内容
首先,需要安装lxml库,用于提取目标字段
pip install lxml

安装好后,在原有代码导入lxml库
from lxml import etree
利用xpath解析源码,代码如下
import requests
# 导入 lxml
from lxml import etree
url = 'https://www.baidu.com/'
# 新添加一个headers字典就好了
# 目的是告诉百度,我是浏览器访问的
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 将headers放入到requests模块中
# 新添加了一个timeout,防止访问失败,程序卡顿
tem = requests.get(url, headers=headers, timeout=10)
result = tem.text
# 将网页内容 result 传入到etree 中
html = etree.HTML(result)
# 利用xpath解析网页内容
left_text = html.xpath('//div[@id="s-top-left"]/a/text()')
# 打印我们需要的目标内容,值得注意的是:这里没有显示“更多”
print(left_text) # ['新闻', 'hao123', '地图', '视频', '贴吧', '学术']如何找xpath?
打开百度首页,右击,选择检查,就会出现源代码
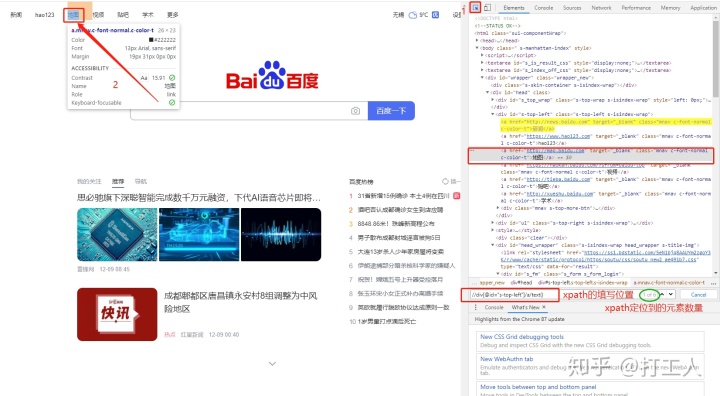
按照上图的步骤,学会定位到元素;
xpath部分,可以一个个敲着试,比如先写一个//div
--> 再加入div属性 //div[@id="s-top-left"]
--> 再加入a标签 //div[@id="s-top-left"]/a
--> 最后写全xpath //div[@id="s-top-left"]/a/text()
看看每一步的变化,不要光看不练,动手才会出结果
写好xpath,就可以把上述小代码走一遍啦
恭喜你,已写好人生第一个小爬虫!!!
以上就是百度首页采集的全部内容啦~
欢迎讨论,交流,有时间再加一个把数据保存到本地的代码
虽然我写的很简单,但只是想帮助新手,增加一点信心
嘿嘿,过几天,我们再见~
打工人专属安利:
Python编程入门2021攻略,书籍推荐,视频推荐,每天更新















 1055
1055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









