






关注你的技艺。
《程序员修炼之道》
(滑动向下?)
▼
弗兰克(妇男科):学习遇到问题了吗?
张三:没有
Frankie:视频加载倒计时3.2.1
不要瞎练,请找弗兰克(妇男科)!
微信:gdkj1111
备注,领取编程书籍!

最坏的情况
通常,在分析程序时,最坏情况下的执行时间才是最重要的。
最坏情况下的执行时间是指给定大小的输入需要最长时间运行的情况。
对于查找来说,就是当关键字是索引中的最后一个条目,或者根本不在索引中的时候。
观察代码会让你更好地理解为什么时间会有这样的比例,以及更坏情况和平均情况下的运行时间。这是上一节的代码:
def add_to_index(index,keyword,url): for entry in index:if entry[0] == keyword: entry[1].append(url) return# not found, add new keyword to index index.append([keyword,[url]]) def lookup(index, keyword): for entry in index: if entry[0] == keyword: return entry[1]return Nonelookup 做的是通过列表。对于每一个条目,它都会检查它是否与关键字相等。下面是索引的结构。

循环的迭代次数取决于索引。索引的长度是代码通过循环的最大次数。如果关键字被提前找到,循环完成的时间就会更早。
另一个相关的事情是 add_to_index 是如何构造列表的。
它循环检查所有条目,看关键字是否存在,如果不存在,它就将新条目添加到列表的末尾。第一个添加的条目被添加到索引的开头,最后一个添加到末尾。这就是为什么'aaaaaaa'是索引中的第一个条目。

让查询变得更快
怎样才能让查找速度更快?为什么这么慢?因为它要经过整个for循环,所以很慢。
for entry in index: if ...来查找是否有一个关键字不存在。这不是你在现实生活中使用索引的方式。
当你拿起一本书,并在索引中查看,你不会从A开始,然后一直工作到Z,以知道是否有一个条目不在那里。
你会直接去到它应该在的地方。你可以在索引中跳来跳去,因为它是按顺序排列的。你知道条目所属的位置,因为它是按字母顺序排列的。
如果它不在其所属的地方,它就不在索引中的任何地方。
你可以用你的代码中的索引做一些类似的事情。
如果你有一个排序的索引,你可以直接进入你想要的条目。
排序是一个有趣的问题,但在本课程中不会涉及。你将学习另一种方法来知道在哪里寻找你感兴趣的条目,而不是必须按照特定的顺序保持索引。
这个方法将是一个函数,称为哈希函数。给定一个关键字,哈希函数(hush function)将告诉你在索引中的何处查找。
它将把关键字映射到一个数字上(这意味着它接收一个关键字并输出一个数字),这个数字就是在索引中你应该寻找关键词的位置。这意味着你不必从头开始,一直在索引中寻找你要找的关键词。
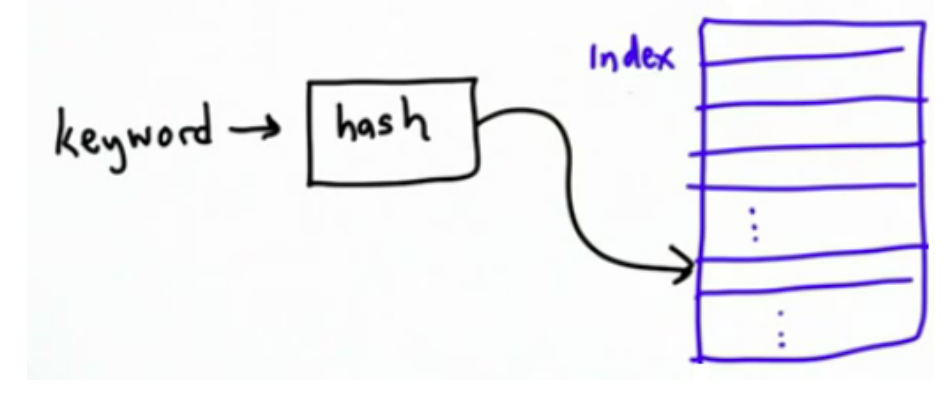
有很多不同的方法可以做到这一点。
一个简单的方法是根据每个关键词中的第一个字母。这就像一本书中的索引的工作方式。索引中的每个条目将对应一个字母,并将包含所有以该字母开头的关键词。
这不是最好的方法。它可以减少搜索所有关键词的时间,因为你只需要搜索以该字母开头的关键词,但不会加快那么多。
它最多只能加快26倍的查找速度,因为有26个桶,所以如果所有桶的大小都一样的话,每个列表会小26倍。这对英语来说就不是那么好了,因为以S或T开头的单词比以X或Q,所以桶的大小很不一样。如果你有几百万个关键词,速度会更快,但不够快。有两个问题需要解决:
根据整个单词来制作一个函数
使函数将关键词均匀地分布在各桶之间
所述的表叫做哈希表(hash table)。
这是一个非常有用的数据结构。事实上,它是如此有用,以至于它被内置于 Python 中。有一个Python类型(类型就是索引和字符串之类的东西)叫做字典。它提供了这个功能。
在这几篇文章结束的最后,你将学会修改你的搜索引擎代码来使用 Python 字典。
然而,在学习之前,你将学会自己实现它,以确保你理解哈希表的工作原理。

哈希函数
接下来,定义一个满足这些属性的哈希函数。它将被称为 hash_string。它的输入是一个字符串和 buckets 的数量,并输出一个介于0和b-1之间的数字。

你需要的是一种将字符串变成数字的方法,这一点还没有讨论过。
你可能还记得,在生成大索引的代码中,有两个运算符,make_big_index,没有解释。
这两个运算符分别是ord(代表序数)和 chr(代表字符)。运算符ord将一个单字母字符串变成一个数字,而chr将一个数字变成一个单字母字符串。
ord() → Number
chr() →
例如:
print ord('a')97print ord('A')65print ord('B')66print ord('b')98注意,大写字母和小写字母的映射是不同的。同时注意,'B'的数字比'A'高,'b'的数字比'a'高。
ord和chr的一个属性是,它们是反向的。这意味着,如果你向 ord 输入一个单字母字符串,然后将答案输入 chr,你将得到原来的单字母。
同样地,如果你输入一个数字到chr,然后把答案输入到ord,你会得到原来的数字(只要这个数字在一定的范围内),这意味着对于任何特定的字符,我们称之为α,chr(ord(α)) → α。例如,在代码中:
print chr(ord(u))u print ord(chr(117))117你可以在下面看到,如果你输入的数字太大,会发生什么:
print ord(chr(123456))Traceback (most recent call last): File "C:\Users\Kelly\Documents\courses\python\testing.py", line 1, in <module> print ord(chr(123456)) ValueError: chr() arg not in range(256)从错误信息的最后一行,ValueError: chr() arg not in range(256)。
你可以看到,chr()要求它的输入是在range(256)给出的整数列表中,这是一个从0到255(含)的所有整数的列表。
ord给出的数字是基于ASCII字符编码的。对于制作哈希表的目的来说,这些数字是什么并不重要。重要的是它们对每个字母都是不同的。你可以使用ord将字符转化为数字。
它只能接受一个字母作为输入。如果你尝试输入更多,你会得到一个错误信息。
print ord('webside')Traceback (most recent call last):File "C:\Users\Sarah\Documents\courses\python\testing.py", line 2, in<module>print ord('webside') TypeError: ord() expected a character, but string of length 7 found最后一行告诉你,你应该只输入一个字符,即一个字母字符串,但你却输入了一个长度为7的字符串。
现在,你有了一种将单字符字符串转换为数字的方法,这就是ord。接下来,你将需要一种方法来处理哈希函数必须具备的另一个属性,即把关键字映射到0到b-1的范围。

作者 | ?君 | 当值编辑 | Sunteen
















 9176
9176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









