









看了好多代码,目前为止都是散乱的分享,接下来将整理作为专题,进行系统化的一个分享整理,也是我自己学习的过程。第一个的系统化的分享专题——python办公自动化。代码后面的#所表示的是注释,对本行代码进行解释的内容,用#号开头是让程序理解这是注释不需要运行的意思。
本模板旨在分享和解读完整代码,只要你有安装配置好python环境,在pycharm里安装相应的第三方文件库,黏贴代码即可运行,我会尽量在代码后面都进行标注解读。我们以实用型为目的学习。编程类学习,从模仿中掌握突破。需要python教学视频和资料的在公众号菜单栏获取,有任何问题欢迎公众号后台联系我或加我微信。python安装教程
注:import后导入的模块需要单独安装,有些是自带的,但是要实现更复杂的功能一般是安装第三方模块。安装方法:
1.win+r,调出命令提示窗口,输入cmd再按回车键。
2.输入安装指令(电脑要联网,推荐使用国内镜像网站,安装更快,不然很慢)
Python pip安装第三方库的国内镜像
Windows系统下,一般情况下使用pip在DOS界面安装python第三方库时,经常会遇到超时的问题,导致第三方库无法顺利安装,此时就需要国内镜像源的帮助了。
使用方法如下:
例如:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xxx(这里的xxx是模块名),这样就会从清华这边的镜像去安装pyspider库。

1
模块安装和基础操作,
以下的操作是基本的数据拆分定位处理,对下一步的操作打下基础。
安装命令:
* pip install xlrd
1)Excel 表格述语
这里需要大家仔细查看图中的每一项内容,知道什么是“行(row)、列(column)”?什 么是“格子(cell)”?什么是“sheet 表”?
提一下,一个Excel文件,就相当于一个“工作簿”(workbook),一个“工作簿”里面可以包含多个“工作表(sheet)”
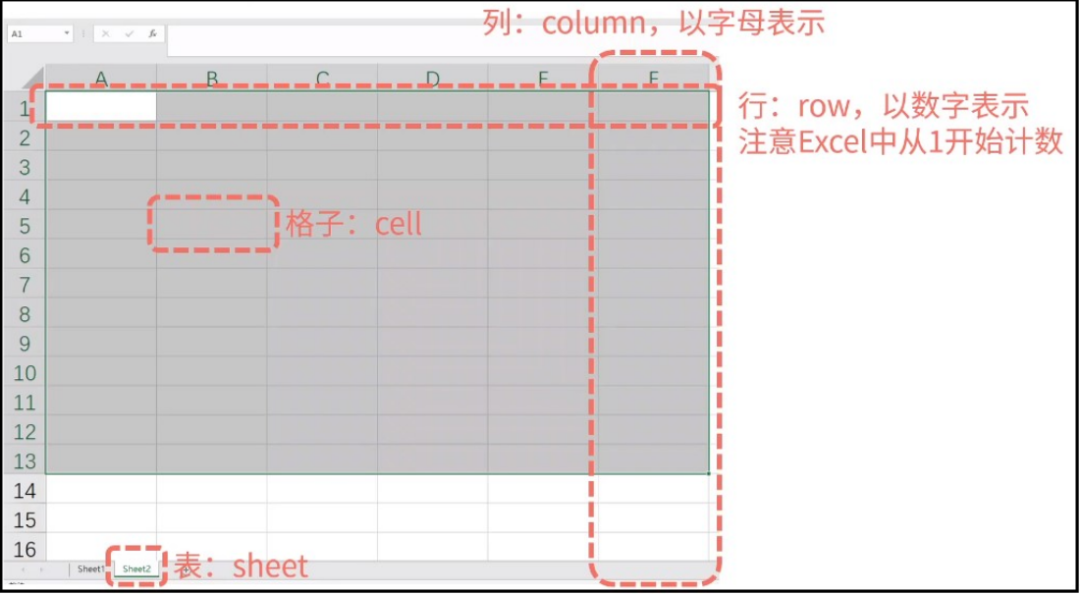
用下面这个表格进行实例操作
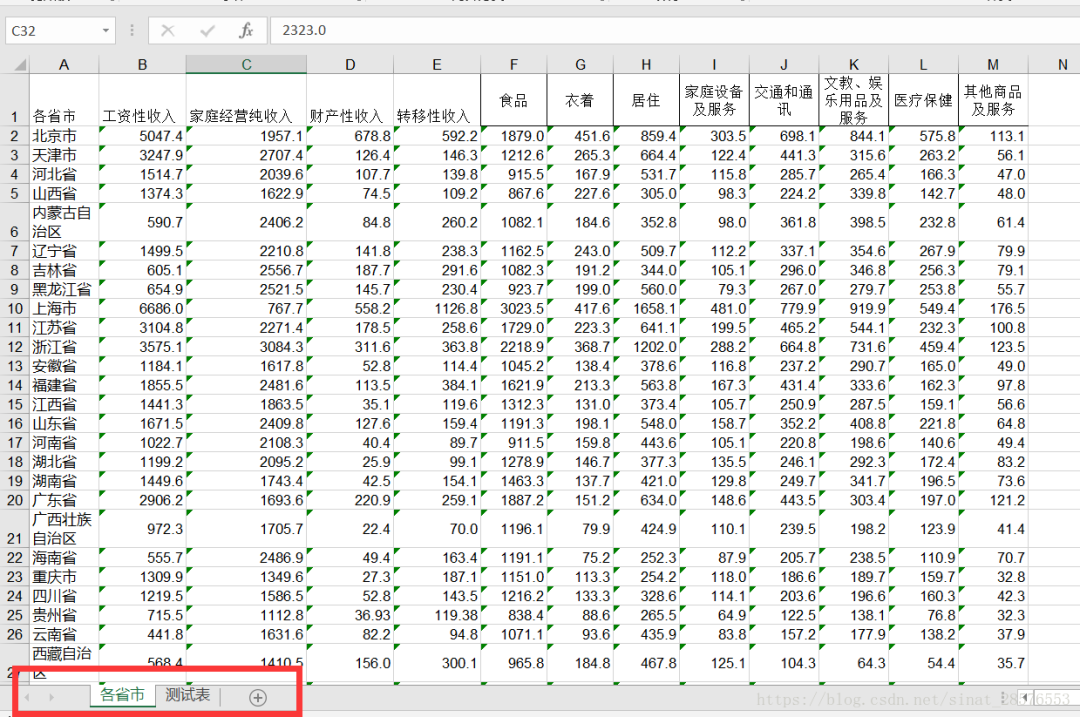
2)获取工作簿对象
import xlrd #引入模块 #打开文件,获取excel文件的workbook(工作簿)对象workbook=xlrd.open_workbook("DataSource/Economics.xls") #文件路径3)获取工作表对象
我们知道一个工作簿里面可以含有多个工作表,当我们获取“工作簿对象”后,可以接着来获取工作表对象,可以通过“索引”的方式获得,也可以通过“表名”的方式获得。
'''对workbook对象进行操作''' #获取所有sheet的名字names=workbook.sheet_names()print(names) #这里的结果是['各省市', '测试表'] 输出所有的表名,以列表的形式 #通过sheet索引获得sheet对象worksheet=workbook.sheet_by_index(0)print(worksheet) #0x000001B98D99CFD0> #通过sheet名获得sheet对象,通俗点,就是通过工资表的名字定位worksheet=workbook.sheet_by_name("各省市")print(worksheet) #0x000001B98D99CFD0> #由上可知,workbook.sheet_names() 返回一个list对象,可以对这个list对象进行操作sheet0_name=workbook.sheet_names()[0] #通过sheet索引获取sheet名称print(sheet0_name) #结果是打印各省市
4)获取工作表的基本信息
在获得“表对象”之后,我们可以获取关于工作表的基本信息。包括表名、行数与列数。
'''对sheet对象进行操作'''name=worksheet.name #获取表的姓名print(name) #打印的结果各省市 nrows=worksheet.nrows #获取该表总行数print(nrows) #告诉你总共有32行 ncols=worksheet.ncols #获取该表总列数print(ncols) #135)按行或列方式获得工作表的数据
有了行数和列数,循环打印出表的全部内容也变得轻而易举。注意:这里采用for循环进行读取打印,这是最基本的循环结果,必须掌握。
for i in range(nrows): #循环打印每一行 print(worksheet.row_values(i)) #以列表形式读出,列表中的每一项是str类型 #['各省市', '工资性收入', '家庭经营纯收入', '财产性收入', ………………] #['北京市', '5047.4', '1957.1', '678.8', '592.2', '1879.0,…………] col_data=worksheet.col_values(0) #获取第一列的内容print(col_data)6)获取某一个单元格的数据
我们还可以将查询精确地定位到某一个单元格。在xlrd模块中,工作表的行和列都是从0开始计数的。#通过坐标读取表格中的数据cell_value1=sheet0.cell_value(0,0)cell_value2=sheet0.cell_value(1,0)print(cell_value1) #打印结果是各省市print(cell_value2) #打印结果是北京市 cell_value1=sheet0.cell(0,0).valueprint(cell_value1) #各省市cell_value1=sheet0.row(0)[0].valueprint(cell_value1) #各省市2
使用xlwt模块对xls文件进行写操作
1)创建工作簿
# 导入xlwt模块import xlwt #创建一个Workbook对象,相当于创建了一个Excel文件book=xlwt.Workbook(encoding="utf-8",style_compression=0)#Workbook类初始化时有encoding和style_compression参数#encoding:设置字符编码,一般要这样设置:w = Workbook(encoding='utf-8'),就可以在excel中输出中文了。默认是ascii。#style_compression:表示是否压缩,不常用。0是不需要的意思2) 创建工作表
创建完工作簿之后,可以在相应的工作簿中,创建工作表。 # 创建一个sheet对象,一个sheet对象对应Excel文件中的一张表格。sheet = book.add_sheet('test01', cell_overwrite_ok=True)# 其中的test是这张表的名字,cell_overwrite_ok,#表示是否可以覆盖单元格,其实是Worksheet实例化的一个参数,默认值是False3) 按单元格的方式向工作表中添加数据
创建完工作簿之后,可以在相应的工作簿中,创建工作表。 # 向表test中添加数据sheet.write(0, 0, '各省市') # 其中的'0-行, 0-列'指定表中的单元,'各省市'是向该单元写入的内容sheet.write(0, 1, '工资性收入') #也可以这样添加数据txt1 = '北京市'sheet.write(1,0, txt1) txt2 = 5047.4sheet.write(1, 1, txt2)
最后被文件被保存之后,上文语句形成的“工作表”如下所示: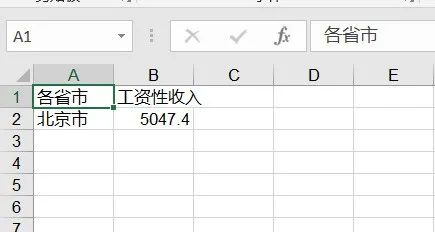
4) 按行或列方式向工作表中添加数据
为了验证这个功能,我们在工作簿中,再创建一个工作表,上个工作表叫“test01”,那么这个工作表命名为“test02”,都隶属于同一个工作簿。在下面代码中test02是表名,sheet2才是可供操作的工作表对象。
#添加第二个表sheet2=book.add_sheet("test02",cell_overwrite_ok=True) Province=['北京市', '天津市', '河北省', '山西省', '内蒙古自治区', '辽宁省', '吉林省', '黑龙江省', '上海市', '江苏省', '浙江省', '安徽省', '福建省', '江西省', '山东省', '河南省', '湖北省', '湖南省', '广东省', '广西壮族自治区', '海南省', '重庆市', '四川省', '贵州省', '云南省', '西藏自治区', '陕西省', '甘肃省', '青海省', '宁夏回族自治区', '新疆维吾尔自治区'] Income=['5047.4', '3247.9', '1514.7', '1374.3', '590.7', '1499.5', '605.1', '654.9', '6686.0', '3104.8', '3575.1', '1184.1', '1855.5', '1441.3', '1671.5', '1022.7', '1199.2', '1449.6', '2906.2', '972.3', '555.7', '1309.9', '1219.5', '715.5', '441.8', '568.4', '848.3', '637.4', '653.3', '823.1', '254.1'] Project=['各省市', '工资性收入', '家庭经营纯收入', '财产性收入', '转移性收入', '食品', '衣着', '居住', '家庭设备及服务', '交通和通讯', '文教、娱乐用品及服务', '医疗保健', '其他商品及服务'] #填入第一列for i in range(0, len(Province)): sheet2.write(i+1, 0, Province[i]) #填入第二列for i in range(0,len(Income)): sheet2.write(i+1,1,Income[i]) #填入第一行for i in range(0,len(Project)): sheet2.write(0,i,Project[i])5)保存创建的文件
最后保存在特定路径即可。
# 最后,将以上操作保存到指定的Excel文件中book.save('DataSource\\test1.xls')执行出来的工作表test02如下所示
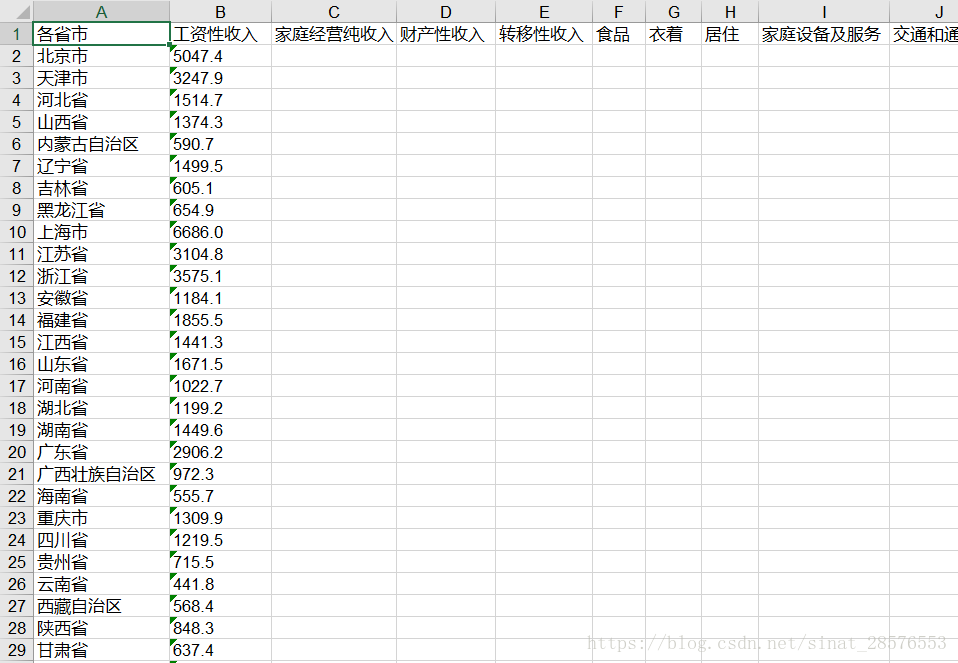
okok,今天的分享到此结束,欢迎各位三连 。长按下方图片关注公众号。
。长按下方图片关注公众号。
















 6018
6018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









