





协同过滤分类
基本的协同过滤类算法分为两类:
- 基于用户
- 基于物品
基于用户
基于用户的可以简述为向用户推荐相似用户喜欢的物品,所谓"爱屋及乌".
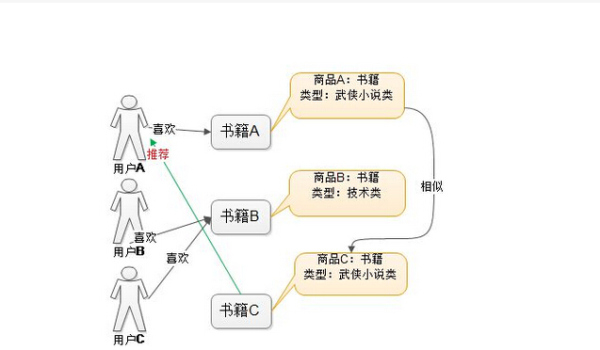
基于物品
基于物品的可以简述为当用户表达出对一个物品的喜爱后,推荐与该物品相似的物品.
基于物品的代码实现
# !/usr/bin/python
# -*- coding: UTF-8 -*-
"""
Created on MAY 28, 2019
@author: woshihaozhaojun@sina.com
"""
import os
import sys
from scipy.sparse import csr_matrix
from sklearn.preprocessing import normalize
from sklearn.metrics.pairwise import cosine_similarity
import warnings
import gc
warnings.filterwarnings("ignore")
def item_based(rating, rating_test=None, sim_min=0, score_min=0):
"""基于物品的协同过滤
1. 每个物品按照L-2归一化后,物品向量相乘获得相似度
2. 每个用户对新物品的评分为该用户评过分的旧物品乘以旧物品和新物品的相似度,然后除旧物品和新物品的相似度,作为预测评分
Args:
rating(scipy.sparse.csr_matrix) :- 评分矩阵, on scale from 1 to 5
rating_test(scipy.sparse.csr_matrix) :- 用于测试的元素构成的评分矩阵, on scale from 1 to 5
sim_min(float) :- 物品相似度的阈值,低于该阈值的相似物品过滤掉
score_min(float) :- 推荐时采用的最小评分
Returns:
pred, scipy.sparse.csr_matrix, 预测的评分矩阵, on scale from 1 to 5
"""
# 计算物品相似度
comic_sim = cosine_similarity(rating.transpose(), dense_output=False)
# 每个物品和其他所有物品的相似度用L-2来归一化,来过滤不怎么相似的物品
if sim_min > 0:
comic_sim_indicator = normalize(comic_sim, axis=0, norm='l2')
comic_sim = comic_sim.multiply(comic_sim_indicator >= sim_min)
print(f"只保留相似度大于等于{sim_min}的物品")
# 每个用户只考虑评分高于score_min的
if score_min > 0:
rating = rating.multiply(rating >= score_min)
print(f"只保留评分大于等于{score_min}的物品")
rec = rating * comic_sim
# 计算weight,weight用来标准化预测
weight = (rating != 0) * comic_sim
del rating
gc.collect()
# 如果有测试元素,只保留测试元素上的预测
if rating_test is not None:
rec = rec.multiply(rating_test > 0)
weight = weight.multiply(rating_test > 0)
# 保证rec和weight有一样的非零元素,这样直接用两个矩阵的data除来代替点除
rec = rec.multiply(weight > 0)
rec = filling(1 * (weight != 0), rec)
return csr_matrix((rec.data/weight.data, rec.indices, rec.indptr), shape=weight.shape)
def filling(indicator, tofilled, filler=0.01):
"""把tofilled中为空但indicator为1的元素用filler补全
比如
indicator: [[1, 0], [1, 1]]
tofilled: [[0, 2],[3, 0]]
filler: 1
返回则为 [[1, 2], [3, 1]]
Args:
indicator(scipy.sparse.csr_matrix) :- 指示矩阵, 元素为0或1
tofilled(scipy.sparse.csr_matrix) :- 要补齐的矩阵
filler(float) :- 要补齐的值
Returns:
scipy.sparse.csr_matrix, 补齐的矩阵
"""
tofilled_i = 1 * (tofilled != 0)
lack_i = indicator - tofilled_i.multiply(indicator)
return tofilled + filler * lack_i













 372
372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









