






子查询
子查询可以理解为是一种嵌套查询(放在括号内作为输入值),他可以将查询结果作为另一个查询的输入值,它一般出现在如下几个语句中:
- WHERE子句中
- 使用 IN 或 NOT IN
- 比较运算符中
- 使用 EXIST 或 NOT EXISTS
- 使用 ANY 或 ALL
- FROM 子句中
- SELECT
在 WHERE 子句中的使用 :
案例1:
目前有如下数据,需求为:查询有哪些员工的工资大于平均水平。
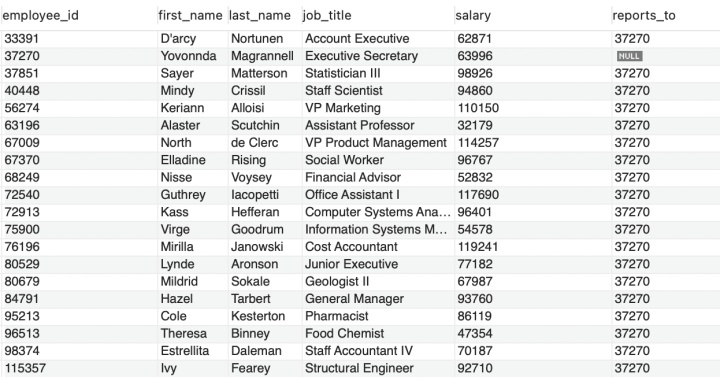
SELECT *
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
)案例2
目前有如下数据,需求为:查询有哪些蔬菜的价格高于id为3的品类:
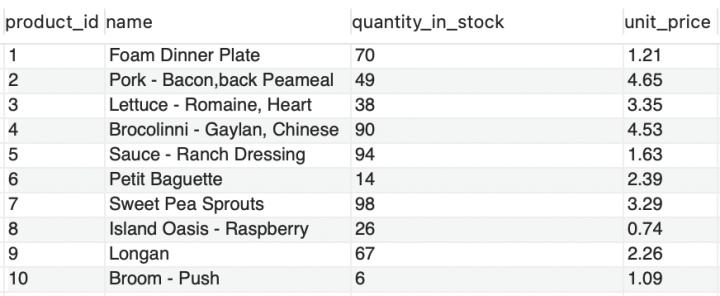
SELECT *
FROM products
WHERE unit_price > (
SELECT unit_price
FROM products
WHERE product_id = 3
)在 IN 和 NOT IN中使用
案例1:
有如下数据,需求:查看哪些客户没有发票 / 有发票
clients数据如下:
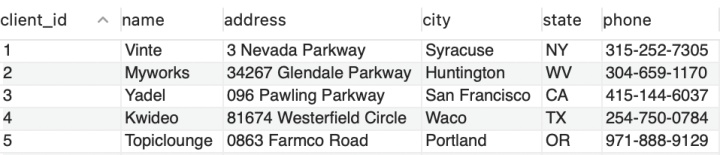
invoices 数据如下:
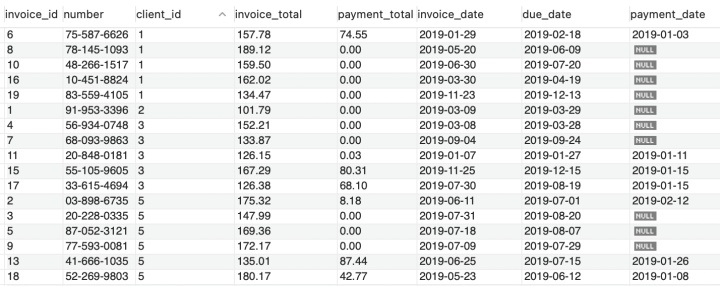
查询有发票的客户:
SELECT *
FROM clients
WHERE client_id IN (
SELECT DISTINCT client_id
FROM invoices
)查询没有发票的客户:
SELECT *
FROM clients
WHERE client_id NOT IN (
SELECT DISTINCT client_id
FROM invoices
)配合ALL使用
ALL 是一个逻辑运算符,它将单个值与子查询返回的单列值集进行比较。
必须以比较运算符开头,例如:>,>=,<,<=,<>,=,后跟子查询。
有如下数据,需求:查询所有金额大于 client_id 为3的最大值
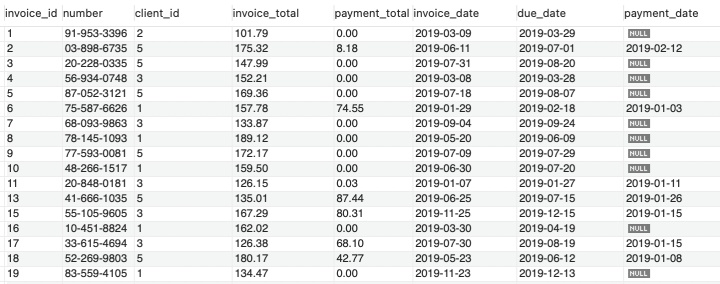
如果不使用ALL 代码如下:
SELECT *
FROM invoices
WHERE invoice_total > (
SELECT MAX(invoice_total)
FROM invoices
WHERE client_id = 3
)使用ALL ,代码如下:
SELECT *
FROM invoices
WHERE invoice_total > ALL(
SELECT invoice_total
FROM invoices
WHERE client_id = 3
)> ALL 大于最大值;>= ALL 大于或等于最大值
< ALL 大于最小值;<= ALL 小于或等于最小值
<> ALL 不等于任何值;= ALL 等于任何任意值
关联子查询:
一般在细分的组内进行比较时会用到关联查询,比如说:某公司一共有3个部门,现在要找出每个部门中,大于本部门收入平均水平的员工。
案例:
现有如下数据:需求是找出大于同一客户所有发票金额平均值的发票号。
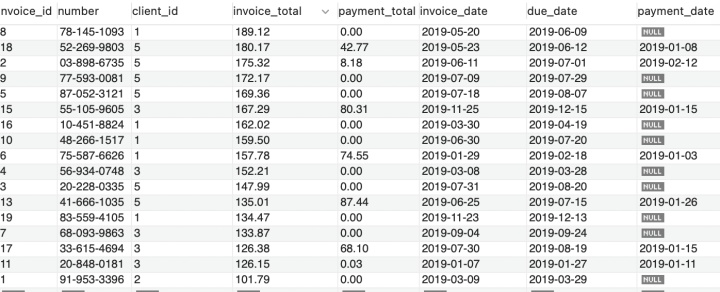
SELECT *
FROM invoices i
WHERE invoice_total>(
SELECT AVG(invoice_total)
FROM invoices
WHERE client_id = i.client_id
)
ORDER BY client_id在子查询中使用的 WHERE client_id = i.client_id 就是关联子查询,这里需要连接自身,所以需要设置一个别名。
我们也可以在SELECT 中使用关联子查询,还是刚刚的例子,我们要加入列,列内容为每个客户的平均发票金额:
SELECT
invoice_id,
client_id,
invoice_total,
(SELECT AVG(invoice_total)
FROM invoices
WHERE client_id = i.client_id) avg_invoice_total
FROM invoices i
WHERE invoice_total>(
SELECT AVG(invoice_total)
FROM invoices
WHERE client_id = i.client_id
)
ORDER BY client_id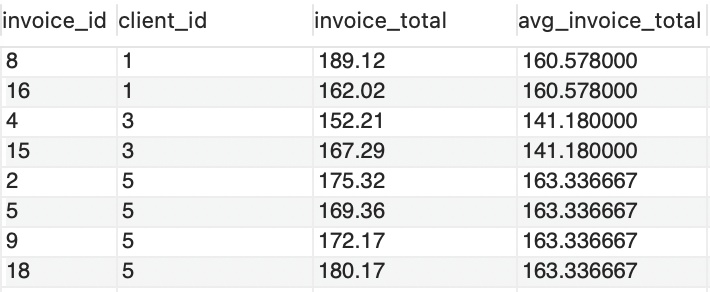
使用EXIST
EXIST 运算符来测试子查询是否包含任何行。它 IN 的作用比较类似,但是在数量多的情况下,其运行效率要好过 IN 。
案例:
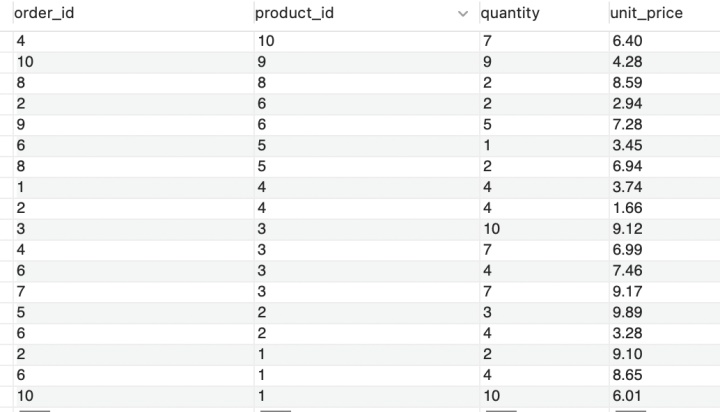
现有如下数据,需求为找出没有销售过的产品
order_items 数据
products数据
SELECT *
FROM products p
WHERE NOT EXIST (
SELECT product_id
FROM products
WHERE product_id = p.product _id
)也可使用IN来达到同样的目的:
SELECT *
FROM products
WHERE product_id IN (
SELECT product_id
FROM products
)














 119
119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









