






超参数是机器学习模型的重要组成部分,在这篇文章中,我们将讨论:
- 机器学习建模中的调整阶段
- 机器学习模型(尤其是GBDT模型)的重要参数,
- 常见的四种调整方法(手动/网格搜索/随机搜索/贝叶斯优化)。
1.通用超参数调整策略
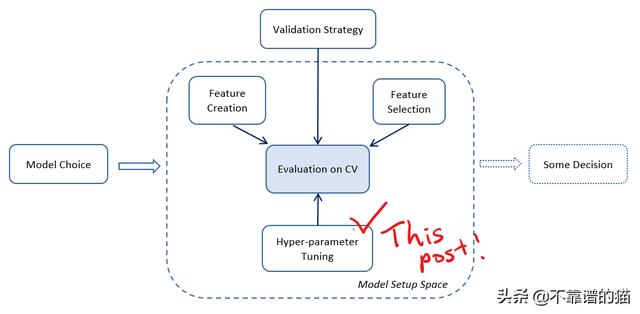
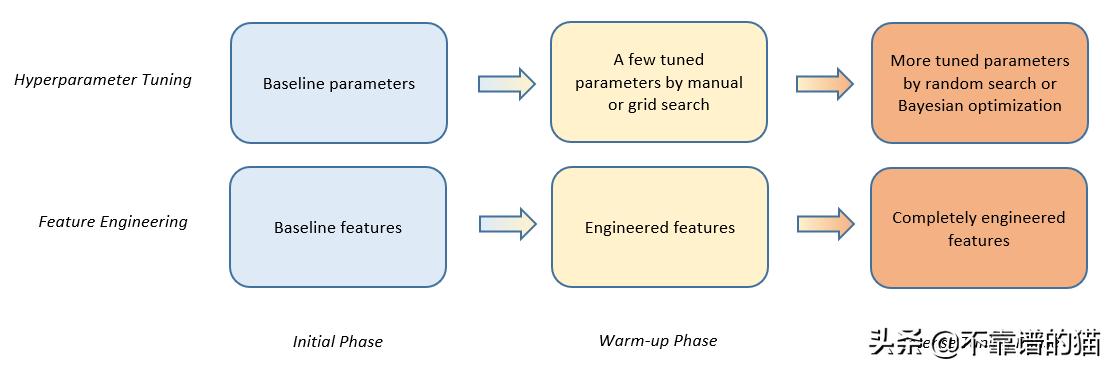
1.1特征工程的参数整定分为三个阶段
我们应该记住以下常见步骤:
- 初始阶段:启动基线参数和基线特征工程
- 预热阶段:使用一些搜索候选项对一些重要参数进行手动调优或网格搜索
- 调整阶段:更多参数的随机搜索或贝叶斯优化,最终特征工程
1.2什么是超参数基线,哪些参数值得调整?
然后,您将遇到另一个问题:“超参数基线是什么,哪些参数值得调整?”
每个机器学习模型的参数是不同的,因此我不能在这里讨论每个模型的参数。注意参数的选择一直是数据科学家的工作。
在这篇文章中,我将重点关注GBDT模型,xgboost、lightbgm和catboost,这些模型是用来讨论的入门模型。
下面的图表是一个总结:
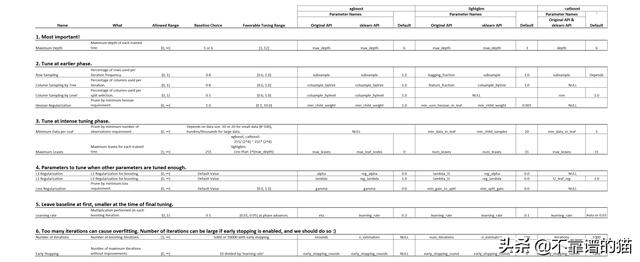
三种GBDT模型的重要超参数列表,它们的基线选择和调整范围
使用Python包对GBDT进行建模的人通常选择原始函数版本(' original API ')或 sklearn API。大多数情况下,您可以根据自己的喜好进行选择,但是要记住,除了catboost包之外,原始API和sklearn API可能有不同的参数名称,即使它们表示相同的参数。
2.超参数调整的四种基本方法
#1手动调整
通过手动调整,根据当前参数的选择及其评分,对部分参数进行修改,再次对机器学习模型进行训练,并检查评分的差异,在参数的选择过程中不自动改变参数值。
手动调整的优点是:
- 您可以记住超参数的行为,并在另一个项目中使用。因此,我建议至少对主要模型进行一次手动调优。
缺点是:
- 需要手工作业。
- 可能会过多地考虑分数的意外变化,而不去尝试和检查它是否是广义变化。
手动调整的示例:
- 当发现有太多无用的变量输入模型时,您将增加正则化参数的权重。
- 当你认为模型中没有考虑很多变量的相互作用时,你可以增加拆分数量(GBDT情况)。。
您可能会说,如果手动调优远不是获得全局最佳参数的最佳方法,那么我们为什么要进行手动调优呢?在实践中,在早期阶段使用这种方法可以很好地了解对超参数更改的敏感性,也可以在最后阶段进行调优。
令人惊讶的是,许多顶级高手都更喜欢使用手动调整来进行网格搜索或随机搜索。
#2网格搜索
网格搜索是这样一种方法,我们从准备候选超参数集开始,为每个候选超参数集训练模型,并选择性能最好的超参数集。
设置参数和评估通常是通过支持库自动完成的,比如sklearn.model_selection的GridSearchCV。
这种方法的优点是:
- 您可以涵盖所有可能的预期参数集。
缺点是:
- 一次运行一个超参数集需要花费一些时间。整个参数集的运行时间可能很长,因此要探索的参数数量有实际限制。
Python代码示例
# lightgbm sklearn API ver.from lightgbm import LGBMRegressor# importing GridSearchCV.from sklearn.model_selection import train_test_split, GridSearchCVimport pandas as pdimport numpy as np# importing some dataset and prepare train/test data for sklearn functions.df = pd.read_csv 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2427
2427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









