





什么是卷积神经网络?
卷积神经网络(Convolutional Neural Networks, CNN)是一种主要用于图像分类的人工神经网络(Artificial Neural Networks, ANN)。它遵循的生物学原理是复制一种能够识别模式的结构,从而在不同的位置识别这些模式。它的灵感来自于诺贝尔奖得主Hubel和Wiesel在1962年出版的《Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex》一书中提出的猫视觉系统模型。1980年,Fukushima’s Neocognitron就是利用了这一灵感,尽管当时没有使用“卷积”这个词。卷积神经网络(CNN)不仅仅在图像识别方面的取得了成功,它们在处理时间序列和语音识别等时态数据时(甚至应用于图形时),也显示出了良好的结果。
卷积神经网络在赢得2012年Imagenet大型视觉识别挑战赛(ILSVRC)后变得非常受欢迎。Alex Krizhevsky和Ilya Sutskever在Geoffrey Hinton的指导下,提交了以“AlexNet”的命名的CNN架构。那时,Geoffrey Hinton已经在ANN领域做出了重大的科学贡献。他是1986年的反向传播算法和1983年的玻尔兹曼机的贡献者之一。这些就是杰弗里·辛顿被公认为深度学习之父的原因。
卷积、互相关
典型的CNN由一系列卷积层组成,这些卷积层充当特征提取器,然后是分类器,通常是多层感知器(MLP),也称为全连接层(FC层),如图1所示。
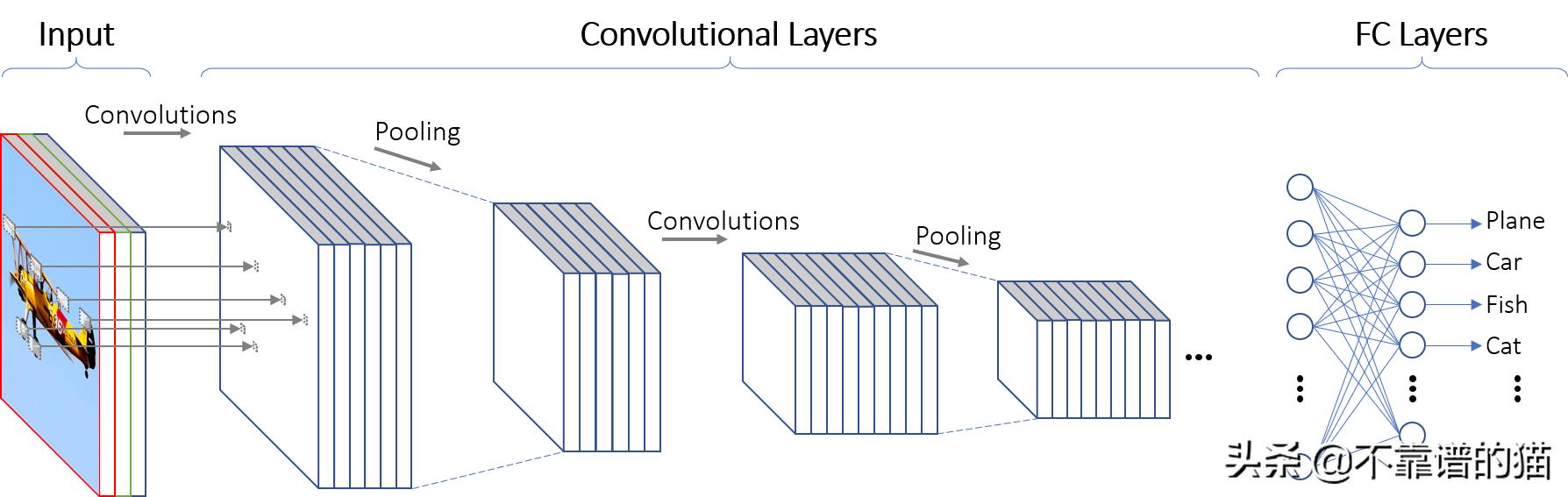
图1 基本卷积神经网络的体系结构
第一层接收以三种颜色通道(RGB通道)表示的输入图像。然后,第一层使用多个kernels对输入图像进行卷积,得到第一层的一组特征映射。每个特征映射决定一个特定特征的强度和位置。卷积层提取的特征映射可以提交到一个下行采样操作,称为池化。池化操作是可选的。池化层的结果是另一组特征映射,这些映射具有相同的数量,但是分辨率降低了。接下来的卷积层使用前一层的特征映射来执行更多的卷积并生成新的特征映射。最后一层的特征映射是分类器FC层的输入。
用*(星号)表示的卷积运算可以描述为:

x某种类型的输入(如传感器信号),t为给定时间,k为核应用。
卷积运算的一个重要特性是它是可交换的,这意味着(∗)=(∗)如下:
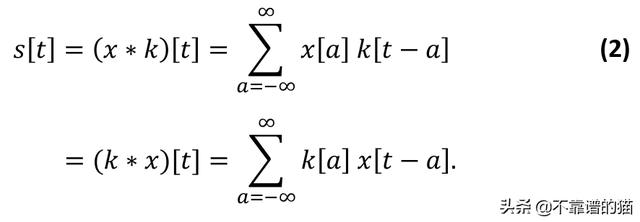
另一方面,用⋆(五角星)表示的互相关运算不是可交换的,可以描述为:

卷积的可换性来自于核相对于输入的翻转(flip)。翻转是索引操作的结果。注意,输入的索引为,核的索引为-。虽然交换性对于数学证明的编写是有价值的,但是它与神经网络的实现并不相关。实际上,许多机器学习库都实现了互相关而不是卷积,并且将这两种操作都称为卷积。结果,与方程式1所描述的实际实现卷积的库相比,在训练过程中学习的内核将被翻转。在本文中,我们将遵循相同的约定,并将其称为互相关卷积。
我们可以将等式3调整为适用于2D数据(例如灰度图像)的卷积:

[]卷积的离散输出,ℎ核的高度,核的宽度,(,)灰度图像的patch,[++]核。
换句话说,卷积运算从图像中提取多个像素块,以与核相乘。核基本上是权重矩阵。从图像中提取的像素patch通常被称为感受野(在生物学上,感受野是刺激神经元的感觉区域)。感受野与核之间的乘法包括每个像素与核中各个元素之间的逐元素乘法。乘法之后,将结果相加,以形成特征映射的一个元素(在等式4中由[,]定义)。
以下动画显示了5x5灰度图像和3x3核之间的卷积操作。该卷积的输出是3x3特征映射。

图2-逐步将5x5图像与3x3核进行卷积
动画中使用的实际图像如下面的图3所示。核中的值和特征映射被重新调整,以适应0到255之间,并以灰度像素表示。图中较亮的像素代表较高的卷积值,较暗的像素代表较低的卷积值。

图 3-5x5输入与3x3核的卷积
上面的卷积使用3x3核,因此,输入中有9个可能的感受野,每个感受野的大小为3x3。注意,由大多数白色像素或大部分由深色像素组成的感受野在卷积之后导致非常暗的像素。另一方面,由左侧的三个亮像素,中间的中间像素和右侧的暗像素组成的感受野在卷积后产生亮像素。这是因为这种类型的核可用于突出显示边缘,特别是边缘从左侧的亮区域过渡到右侧的暗区域。
现在,看看将相同的核应用于也包含相反过渡的图像(从左侧的暗区域到右侧的亮区域)时会发生什么。在图4中,表现出从暗到亮过渡的感受野产生了最暗的像素。请注意,以前的过渡(从亮到暗)仍然导致像素变亮。这意味着该核不仅可以检测从亮到暗的边缘过渡,还可以检测从暗到亮的相反边缘。一种类型的边导致最大的正值,而另一类型的边导致最大的负值。
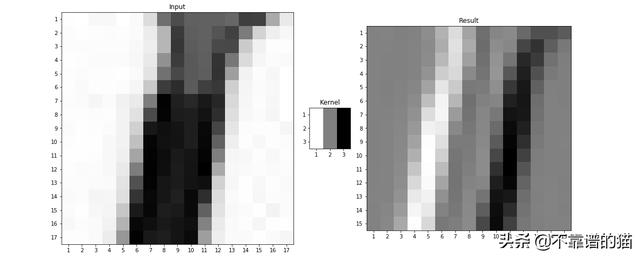
图4-带有边缘检测器核(3x3)的图像(17x17)的卷积
RGB图像的卷积与灰度情况非常相似。公式4可以适用于RGB图像,添加另一个循环以遍历RGB通道,如下所示:
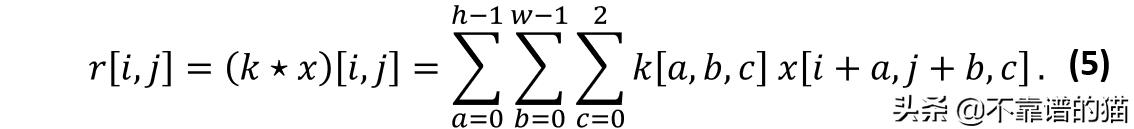
额外的循环变量允许在通道RBG上进行迭代。结果,总和是在三维数据上完成的,而不是二维数据,并且仍然为每个三维感受野和核产生一个单一值。
特征提取
让我们从一个实际的例子开始这个话题。查看图5中以下三个卷积的结果。为了说明卷积的结果,以下示例中的三个核中的每个核都包含一个从图像中提取的小patch。

图5-卷积示例
在第一个示例中,组成内核的面片包含白色的数字为6的平面区域。右侧的灰度图像本质上是核与图像之间卷积的结果。最暗的像素代表在感受野和核之间进行操作的最小结果,另一方面,最亮的像素代表在感受野和核之间进行操作的最高值。
在第二个示例中,核由构成平面轮盘的像素块组成。在第三个示例中,核由从飞机尾部复制的黄色像素组成。
注意,每个结果图像中亮像素对应于产生每个核的位置。在第一个例子中,它对应数字6的位置。在第二个例子中,它对应于轮子的位置。在第三个例子中,最亮的像素对应于平面的所有黄色区域。
Stride
Stride是每个感受野之间的距离。到目前为止,我们展示的所有示例都使用1。采取如此小的步伐会导致感受野之间出现很大的重叠。结果,在相邻的接收域中重复了很多信息,如图6所示。

图6 –步幅为1的感受野
对于大小为3x3的核,采用步幅为2会导致一列或一行与相邻的接受域重叠。这种重叠是为了保证stride不会跳过重要的信息。
增加步幅将减少卷积的计算成本。如果我们将步幅从1改为2,计算成本的减少大约是4。这是因为在两个维度上,步幅都会影响接受域之间的距离。类似地,如果我们将步幅增加三倍,我们可以期望计算成本减少大约九倍。由于步幅的增加减少了从输入中提取的感受野的数量,因此减少了计算量,从而减少了输出的维数。
图7显示了使用2、4、8和16步幅的卷积结果。卷积中使用的核大小是70x70。

图7-步幅为2、4、8和16的示例
在图7中,使用步幅为16的卷积结果的像素比使用步幅为8的结果少四倍。请注意,采用步幅为16的结果将导致54行或列的重叠,因为感受野的大小是70x70。当步幅为16时,仍然可以通过飞机轮子上最亮的像素来识别卷积的最大值。
正向传播
在本节中,我们将研究卷积层中正向传播的工作原理。为此,我们将了解单个卷积层如何工作,然后了解多层如何一起工作。在这项研究中,我们将学习两个新概念:非线性激活和池化操作。
在卷积层内
图8显示了典型卷积层中的正向传播,它包括三个阶段:卷积,非线性激活和池化。卷积运算已在第一部分中进行了讨论。现在,我们将看到其他两个操作。

图8-卷积层的三个阶段
非线性激活也称为detector stage。在此阶段,将卷积和偏差的结果提交给非线性激活,例如ReLU函数。非线性激活不会更改要特征的大小,它只会调制其中的值。
非线性激活
首先,什么是线性激活?线性激活是一个遵循f(x)=ax规则的函数,其中a是常数,x是变量。它的图形是一条通过原点(0,0)的直线。这意味着a和b为常数的f(x)= ax + b形状的函数不是线性的。两者都是仿射函数,只有一个常数乘以变量的是线性函数。
对于线性函数,当我们将输入乘以常数时,还应该看到输出乘以相同的常数。这意味着:

当我们在线性函数中应用两个输入的总和时,我们应该获得分别应用于函数的两个变量的总和的输出等效项:

为什么我们要使用非线性激活呢?因为当我们在线性函数中应用线性组合(加法或乘法)时,结果也是线性的。尽管许多模型可以用线性模型来近似,但在神经网络中使用非线性使其能够同时表示线性和非线性模型。换句话说,非线性使神经网络成为更强大的函数逼近器。
深度学习中最常用的非线性激活之一是ReLU函数。该函数由以下式提供:

当对该函数施加偏差时,结果如图9所示。

图9 — ReLU函数图
图10显示了ReLU如何调节卷积的结果。在这里,图2中的相同结果用于应用ReLU函数。
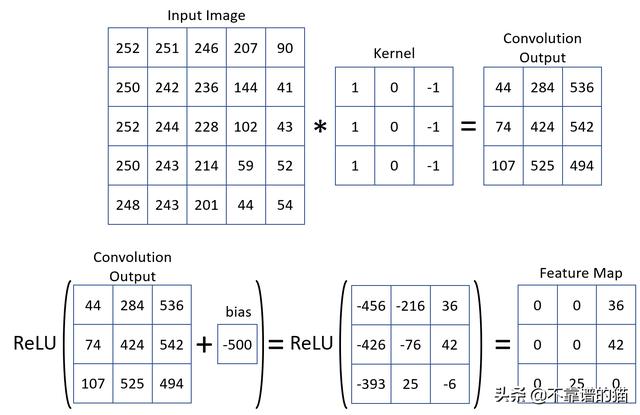
图10-卷积后应用的ReLU函数
上例中使用的ReLU函数的等效图像如图11所示。
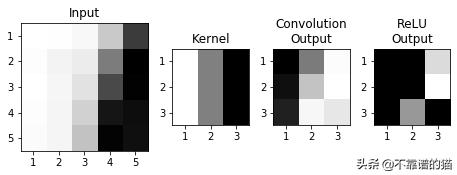
图11 —卷积后应用的ReLU函数的可视化表示
接下来,在图12中,您可以看到ReLU函数中的一些偏差选项。该函数将平面与包含轮子的图像块进行卷积的结果作为输入。请注意,偏差的行为类似于一个阈值,它决定显示什么和不显示什么。

图12 —平面和包含轮子的图像块之间的卷积结果的不同偏差值
图12中描绘的阈值行为类似于生物神经元,当它在某个阈值以下受到刺激时不会触发。如果刺激超过阈值,则神经元开始触发,并且随着刺激的增加,触发频率也会增加。在图12中,当偏差为500时,它有助于人工神经元的活动。但是,如果将偏差定义为-1000,则人工神经元只会以最强的刺激激发。
综上所述,ReLU函数是一个人工神经元。ReLU函数负责检测核提取的特征是否存在。因此,每个核都有一个偏差,因为每个特征都需要一个不同的阈值。
池化
这是对每个特征映射执行的下采样操作。它从特征映射中提取感受野,并用单个值替换它。可以通过不同的聚合标准(例如,最大值,均值或根据距中心距离的加权平均值)获得单个值。
除了聚合标准外,池化操作中还有其他两个超参数,即感受野大小和步幅。
与步幅相似,池化操作导致卷积处理的数据更少。一个区别是,池化操作不是跳过数据,而是尝试将感受野汇总为单个值。另一个区别是,在卷积之前应用了步幅,而在卷积的结果上应用了池化,从而减少了到下一层的数据量。此外,池化操作的感受野是二维的,因为它分别应用于每个特征映射,而卷积的感受野是三维的,包括一层中所有特征映射的一部分。
池操作的一个副作用是增加了网络对输入转换的不变性。如果更多的卷积层执行池化操作,这种效果将被放大。
图13显示了卷积步幅,ReLU函数的偏差,池化大小和池化步幅不同组合的影响。

图13 –卷积,ReLU和最大池中不同超参数的影响
卷积中的步幅和最大池化中的步幅的影响是累积的。当我们在卷积和最大池化中都使用2的步幅时,最终结果是特征映射的宽度和高度减少了大约四倍。
卷积中stride的值为16,max pooling的stride的值为4是不正常的。这里故意放大,以说明它们对卷积层最终结果的影响。
组合起来
我们将回到第一个著名的CNN架构AlexNet。这是了解CNN组件如何协同工作的一个很好的实际示例。AlexNet的构建块如图14所示。虚线金字塔表示使用输入的接收字段或上一层的特征图进行卷积的过程。大框代表要素图,而要素图中的小框代表接受区域。此CNN可以将对象分类为1000个不同的类。
我们回到AlexNet。这是一个了解CNN组件如何协同工作的很好的实际示例。AlexNet的构建块如图14所示。虚线表示使用来自输入的感受野或来自前一层的特征映射执行卷积。大框表示特征映射,小框表示感受野。这个CNN可以将对象分成1000个不同的类。

图14 — AlexNet CNN的体系结构
该架构的一个独特之处在于它是使用两个GPU进行训练的。
您可以在某些框架(例如PyTorch)上获得此卷积神经网络(CNN)训练。您还可以使用迁移学习将该体系结构应用于其他图像数据集。它需要一些数据处理才能对图像进行归一化和rescale,以符合AlexNet的要求。就像这样:
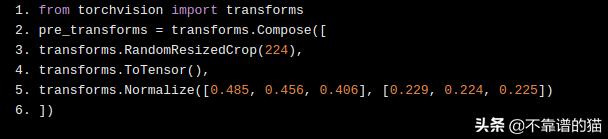
您可以按照以下步骤在PyTorch中导入模型:

您可以禁用对卷积层的训练,并创建自己的分类器以覆盖原始的AlexNet全连接层:
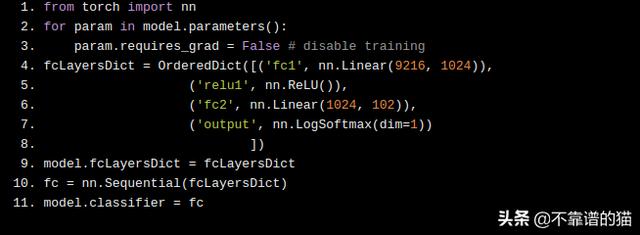
除了AlexNet,PyTorch中还有其他机器学习模型,可以根据需要进行自定义,从而对您自己的图像数据集进行分类。建议您测试这些机器学习模型,甚至从头开始构建自己的CNN,以了解CNN的工作原理。















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









