





《Visualizing and Understanding Convolutional Networks》总结
1 Introduction
- 上世纪90年代卷积网络用于手写数字分类和人脸检测
- 2012年convnet模型有不错的表现
- 可以应用到更大的数据集
- 超大型模型训练的实用性
- 更好的模型正则化策略,如dropout
- 需要将数据可视化,以便在训练过程中检测特征演变,诊断模型潜在问题。
- 方法:multi-layered 反卷积+遮挡图中不同部分进行敏感性分析
1.1 Related Work
- 传统方法无法对高层CNN特性进行可视化,也无法探索CNN的平移、缩放和旋转不变性
- 我们的方法可以观察训练集那些特征激活了feature map
2 Approach
- 输入
- ↓
- 卷积
- ↓
- Relu激活
- ↓
- (maxpooling)
- ↓
- (归一化)
- ↓
- 全连接层
- ↓
- softmax分类
- 网络中的可训练参数:卷积核的权重、全连接层的权重
- 反向传播、梯度下降
2.1 Visualization with a Decovnet
- 本文用反卷积网络deconvnet来实现映射(将featuremap映射回输入像素空间)
- deconvolution/上采样up-sampling/反卷积/转置卷积transposed conv是一样的
- 反卷积(转置卷积、反激活Relu,反池化)用于非监督学习
- 每层附加反卷积神经网络,提供返回图像像素连续路径
- 将输入给卷积神经网络→计算各层特征
- 检查convnet激活,将该层其他设置为0,并将特征映射作为输入传递到附加的deconvnent层,
- 依次反池化unpooling、反激活Rectification、反卷积Filtering重建所选激活层
- 反池化unpooling:最大池化是不可逆的,但是我们可以存储最大像素的位置(switch),反池化时即可还原,但不可避免会丢失非极大值像素的信息
- 反激活Rectification:仍然用Relu,正向Feature map因为Relu使用均为正,反向卷积时也用Relu确保都为正值
- 反卷积Filtering:使用转置后卷积核
- 重复直到达到输入像素空间
- 虽然池化时会丢失一部分信息,但重构得到的图和原始输入图依旧很像,亮暗轮廓体现出特定feature map反映的特征
3 Training Details
- 与前人不同(Krizhevsky's layer 3,4,5被紧密连接替代;layer1,2是检查了可视化后调整的)
- 数据集:模型在ImageNet 2012训练集上训练的,
- 数据预处理:每个RGB图像预处理是调整最小尺寸为256×256,减去每个像素平均值,
- 数据增强:使用10个大小为224×224的子图像(边缘、中心翻转或无翻转),
- 优化器、超参数:随机梯度下降更新参数用到大小为128的mini batch,学习率10-2,动量0.9。验证错误趋于停滞时,减小学习率。dropout用于全连接层6,7,速率为0.5,
- 正则化:所有权重初始化为10-2,偏差设置为0
- 卷积层每一个RMS值超过固定半径10-1的过滤器进行重新正则化。、
- 增加训练集大小(通过多尺度、翻转)
- 70个epoch后停止训练,花费12天
4 convnet Visualization
- feature visualization:



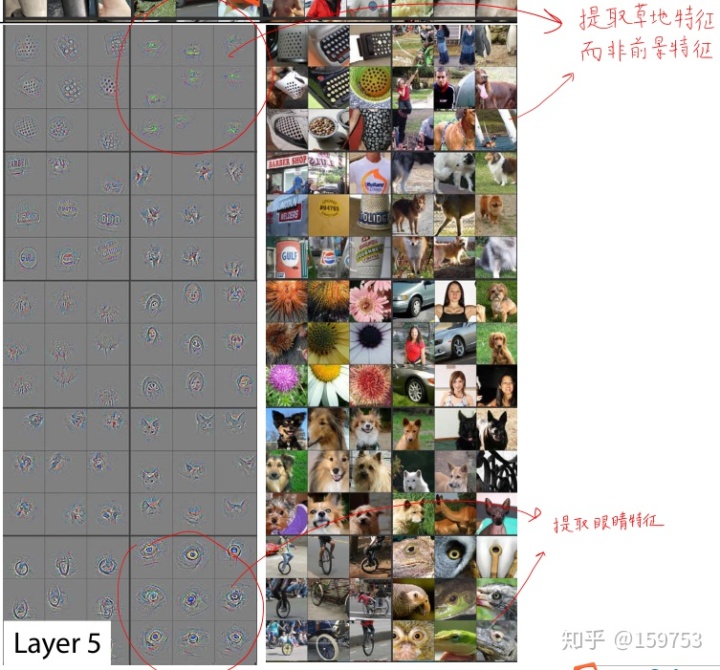
- Feature Evolution during training特征演化
- 训练过程中特征收敛底层快,高层慢
- 特征不不变性
- 竖直平移、缩放、旋转
- 场景图像对竖直平移、缩放敏感,每旋转90°都能被正确识别
4.1 Architecture selection
- 使卷积的步幅由4变为2。这种新的结构在第一层和第二层结构中保留了更多的信息
4.2 Occlusion Sensitivity遮挡敏感性分析
4.3 Correspondence Analysis
深度学习模型没有显式定义图像中各部分的关系
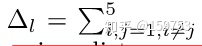
越小说明第l层捕捉到个特征之间越相关
越深的层更加关注语义信息,而非
5Experiments
5.1 ImageNet 2012
- 训练集:1.3M;验证集:50k;测试集:100k
- 用小卷积核,小步长改进AlexNet
- 错误率显著提升
- 全连接层尺寸大小对性能几乎没有影响,增加中间卷积层大小在性能上有显著提高,但也有过拟合可能
5.2 Feature Generalization
- 识别重叠图像,并将其去除后重新训练,避免结果污染
5.3 Feature Analysis
- 逐渐提升预训练模型中保留的层数,把特征送到SVM和softmax中分类,层数越深,特征越有用















 723
723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









