





散列表(哈希表、Hash Table)是基本的数据结构之一,综合了数组和链表的优点,平均情况下,在查找、删除、插入操作上,都能实现O(1)的复杂度。本文介绍哈希表的内部基本原理:hash()函数的设计和冲突的解决;并简单介绍python内部dict的实现。
hash()函数:将key映射为index
哈希表中内部有一块连续的内存区域,即数组,但与数组不同,哈希表通过 hash()函数将一个元素的key映射成该内部数组的索引,该key可以为字符串、整数、浮点数、或复杂的数据结构(比如Python的元组Tuple)。
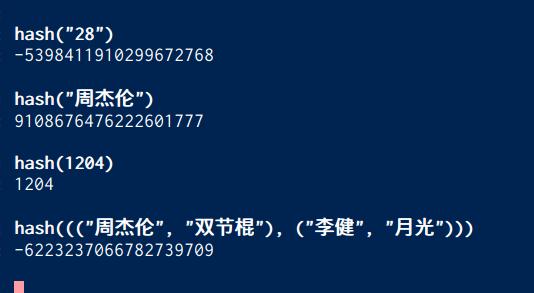
hash例子
一个好的hash()函数的设计,需要满足均匀散列假设,即每个关键字都等概率的映射为内部数组中的任意一个索引。一个极端的设计反例,所有的关键字都映射为同一个索引,这种情况下或等价于链表(如果冲突通过链表解决),或等价于数组(如果冲突用数组实现),哈希表的优点就体现不出来。
最好一个元素的key的所有位(bit) 均参与hash()的生成, 如果用除法散列法,hash(x) = x % m, 一个不太接近2的整数幂的素数,通常是一个较好的选择。
冲突的解决方法
虽然我们可以通过精心设计散列函数来尽量减少冲突的概率,但冲突是不可避免的。解决冲突的常用方法有两类:一类是通过链接法(Chaining),一类是开放寻址法(Open Addressing)。
对于一个能存放n个元素的,具有m大小的内部数组的哈希表,定义装载因子 (Load factor)定义为a=n/m。
链接法中,冲突的元素都放在一个链表中,如果hash()设计好,链表会很短,性能也会很好。在简单均匀散列假设下,可以证明查找的复杂度为O(1+a)
另外一种方法,是开放寻址法,所有的元素存放在内部数组中,没有链表。插入一个元素,会不断尝试检查散列表,直到成功为止。映射函数 hash(key)会通过为hash(key, 0), hash(key, 1), …, hash(key, m-1)不断尝试,这个过程称为探查,最长的探查次数为m,这m次探查对应的索引为 0,1,…,m-1的一个排列。
可以证明,在简单均匀散列假设下,对于一次不成功的查找,复杂度为 O(1/(1-a)),对于一次成功的查找,为O(1/a log(1/(1-a))。a越大,性能越差,举例如下:
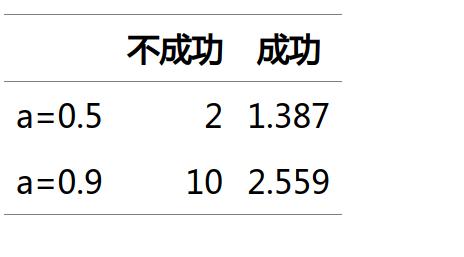
python字典内部实现
python的字典类内部是通过Hash Table实现的,冲突解决方案为开放寻址法,需要说明的,内部的数组,会动态扩容以保证性能(看上图,通过降低装载因子,来提高性能),这也是为什么python中字典对象可以一直往里面插入元素的原因之一。具体实现详情可看cpython 的源码,对应dictobject.c文件。
可以通过插入时间的分析,来有个感性的感受。下图中的插入时间会有毛刺现象,毛刺的产生(即插入时间的突然变大),应该就是在内部的数组在扩容导致。
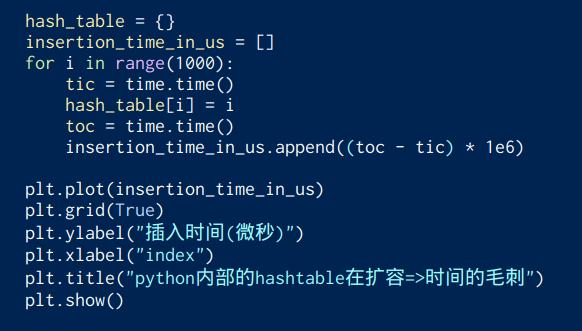
散列表的插入时间源码
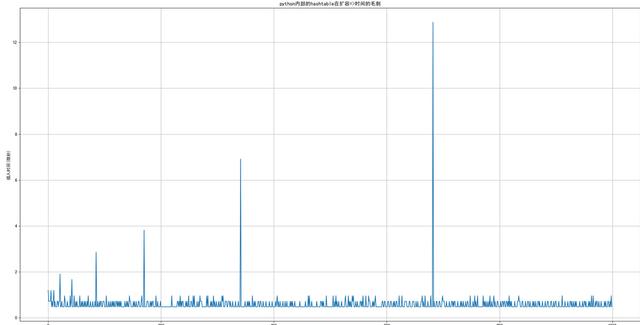
横坐标为索引;纵坐标为的插入时间
总结
散列表内部的原理主要是hash()函数的设计和冲突的解决,来达到O(1)的插、删、查的复杂度。Python字典的实现,就是散列表,内部通过扩容,保证性能和易用。明白上述观点,在以后的编程中对何时用dict会提高性能会了然于胸,比如最简单的两数之和。















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









