





前言:本文主要是分享下利用python爬取百度指定贴吧的全部帖子以及帖子回复内容,主要是利用python的request库获取网页信息,通过正则等方式解析我们需要的数据并存储到数据库中,并且后续可以用于情感分析、热词分析等分析,这些分析操作可以看我的另一篇文章。
https://www.bizhibihui.com/blog/article/38
下面我们开始正式介绍如何从零开始完成百度贴吧的数据采集代码
首先,我们还是一如既往的打开我们要爬取的目标网站进行分析,如下图所示
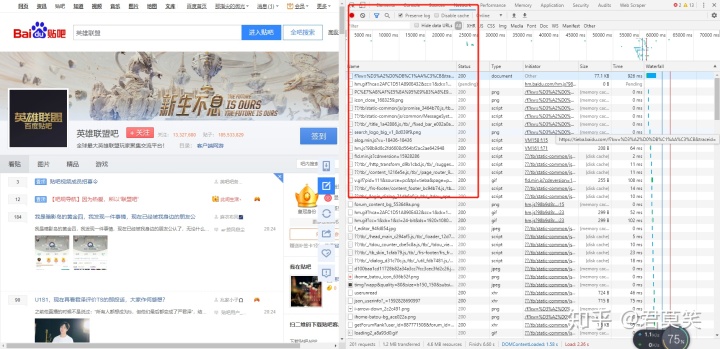
我们还是从上到下,挨个寻找返回具体信息的接口请求,我们可以很容易就发现第一个请求里就返回了数据
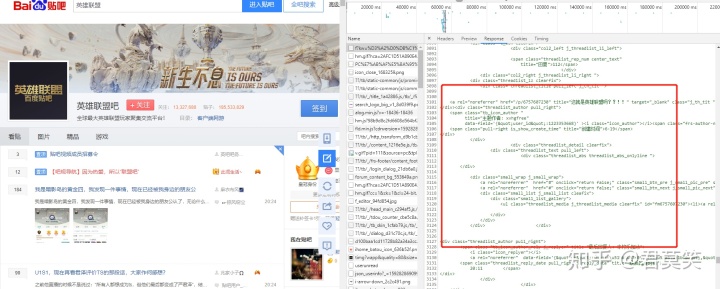
但是我们会发现这个数据和我们常见的网页数据不一样,我们可以用request来论证这个观点
response = requests.get(url,headers=self.headers)
try:
response_txt = str(response.content,'utf-8')
except Exception as e:
response_txt = str(response.content,'gbk')我们会发现无法直接通过xpath解析我们拿到的数据,原因其实很简单,就是这些网页数据是百度通过特殊的js动态渲染的,但是我们在第一个请求里其实就可以拿到我们想要的数据,只不过,我们需要多费点劲,我们现在就来研究下这个接口里返回的数据,如下图所示

可以发现,我们所有的数据的html都是被<!-- -->符号给包裹起来了,这对于html文件来说就是注释的意思,所以直接解析这些数据,肯定是无法获取的,既然我们无法解析,那就该想想其他的办法,既然我们发现了我们的数据都是存在于<!-- -->符号,那我们可以考虑把这个数据当成整个的字符串,然后用正则表达式获取这部分内容不就成了么,说干就干,代码如下:
bs64_str = re.findall('<code class="pagelet_html" id="pagelet_html_frs-list/pagelet/thread_list" style="display:none;">[.nSs]*?</code>', response_txt)
bs64_str = ''.join(bs64_str).replace('<code class="pagelet_html" id="pagelet_html_frs-list/pagelet/thread_list" style="display:none;"><!--','')
bs64_str = bs64_str.replace('--></code>','')解析的结果你们就自行实验去把,按照这种正则表达式我们就可以拿到我们想要的数据,拿到了数据,我们就可以利用xpath解析数据,代码如下
html = etree.HTML(bs64_str)
# print(thread_list)
# 标题列表
title_list = html.xpath('//div[@class="threadlist_title pull_left j_th_tit "]/a[1]/@title')
# print(title_list)
# 链接列表
link_list = html.xpath('//div[@class="threadlist_title pull_left j_th_tit "]/a[1]/@href')
# 发帖人
creator_list = html.xpath('//div[@class="threadlist_author pull_right"]/span[@class="tb_icon_author "]/@title')
# 发帖时间
create_time_list = html.xpath('//div[@class="threadlist_author pull_right"]/span[@class="pull-right is_show_create_time"]/text()')
creator_list = creator_list[1:]
create_time_list = create_time_list[1:]
print(create_time_list)
print(create_time_list[1])
for i in range(len(title_list)):
item = dict()
item['create_time'] = create_time_list[i]
if(item['create_time'] == '广告'):
continue
item['create_time'] = self.get_time_convert(item['create_time'])
print(item['create_time'])
item['title'] = self.filter_emoji(title_list[i])
item['link'] = 'https://tieba.baidu.com'+link_list[i]
item['creator'] = self.filter_emoji(creator_list[i]).replace('主题作者: ','')
item['content'] = self.filter_emoji(item['title'])
print(item['creator'])
# 保存帖子数据
result = self.database.query_tieba(item['link'])
if(not result):
self.database.save_tieba(item)
self.spider_tieba_detail(item['link'])进行到这一步,我们的爬虫代码基本就成了,这只是简单的实现,我们可以看下爬到的数据,如下图所示
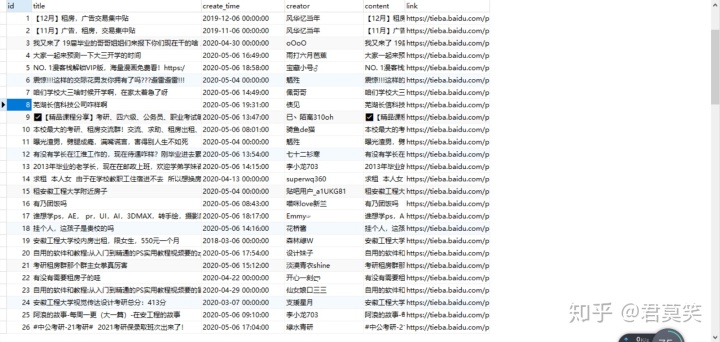
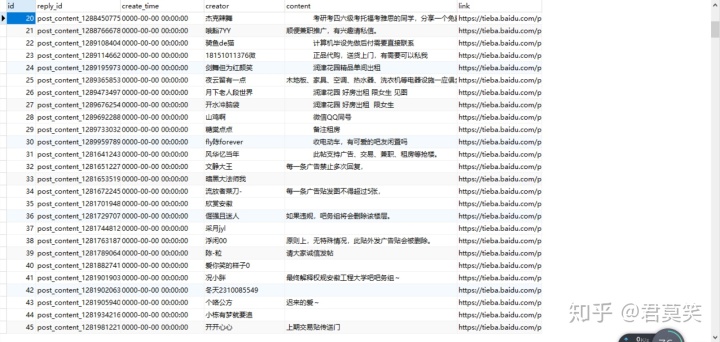
完整代码的话去我开源的爬虫项目里看看,有任何疑问,也欢迎各位留言或者咨询
https://gitee.com/chengrongkai/OpenSpiders
本文首发于https://www.bizhibihui.com/blog/article/43














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









