





记录几个tensorflow函数用法
tf.unique_with_counts(x,out_idx=tf.dtypes.int32,name=None)
x表示一个一维张量,此函数用来统计x中不同元素的信息,可以统计标签信息
import tensorflow as tf
import numpy as np
x = tf.placeholder(dtype=tf.int32,shape=(10,))
y,idx,count = tf.unique_with_counts(x)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
x_v = np.random.choice(np.arange(0,10),size=10,replace=True)
print('x:',x_v)
y_v,idx_v,count_v = sess.run([y,idx,count],feed_dict={x:x_v})
print('y:',y_v)
print('idx:',idx_v)
print('count',count_v)
output:
x: [5 0 6 9 6 1 9 9 1 5]
y: [5 0 6 9 1]# 元素集合
idx: [0 1 2 3 2 4 3 3 4 0]# x中元素在y中对应的索引
count [2 1 2 3 2]# 每种元素的个数tf.scatter_sub(ref,indices,updates,use_locking=False,name=None)
ref表示张量(大于零维),将ref中的值按照indices,用updates更新,ref按照第一个维度进行索引,对应的还有scatter_add,scatter_div,scatter_mul,scatter_max,scatter_min
其中max和min将updates和ref对应的值进行比较,返回较大或者较小的那个
indices和updates第一个维度必须相同,如果indices表示标签,那么该函数可以按标签更新,维护一个类似类中心的变量
import tensorflow as tf
import numpy as np
ref = tf.Variable([1,3,5,7,9,2,4,6,8,10],dtype = tf.int32)
index = tf.constant([4, 3, 1, 7],dtype = tf.int32)
updates = tf.constant([9, 7, 3, 6],dtype = tf.int32)
ref_sub = tf.scatter_sub(ref,index,updates)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
ref_sub_v = sess.run(ref_sub)
print(ref_sub_v)
output:[ 1 0 5 0 0 2 4 0 8 10]
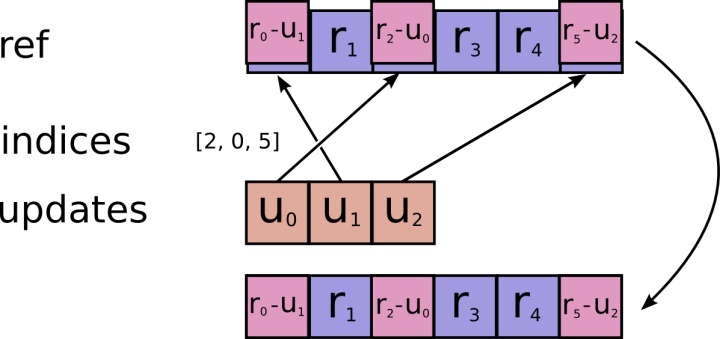
tf.scatter_nd(indices,updates,shape,name=None)
scatter_nd用零初始化一个shape维度的张量,然后用indices作为索引,用updates的值初始化新创建的全零张量,这里应该要求indices的索引值不能超过shape的第一个维度(不然索引找不到)
tf.scatter_nd(indices, values, shape) 和 tf.tensor_scatter_add(tf.zeros(shape, values.dtype), indices, values)表示的含义相同
import tensorflow as tf
import numpy as np
indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
shape = tf.constant([8])
scatter = tf.scatter_nd(indices, updates, shape)
with tf.Session() as sess:
print(sess.run(scatter))
output:[ 0 11 0 10 9 0 0 12]

tf.scatter_nd_add(ref,indices,updates,use_locking=False,name=None)
升级版的scatter_add,可以按照指定的索引(indices),用updates对ref进行更新,不过这里的索引可以是对多维张量的索引(注意使用时必须可以在ref中索引到),updates的维度应该和ref中一个indices对应的张量维度相同,scatter_nd_sub(相减,ref[index]-updates[index]),scatter_nd_update(用updates的值替换,不做加减法)同理
有点饶,看代码比较明显:
import tensorflow as tf
import numpy as np
ref = tf.Variable([[[1, 2, 3, 4],[5, 6, 7, 8],
[1, 2, 3, 4],[5, 6, 7, 8]],
[[10,11,12,13],[14,15,16,17],
[10,11,12,13],[14,15,16,17]]
])
indices = tf.constant([[1,1]])# 表示对应的索引,ref[1,1]=[14,15,16,17]
updates = tf.constant([[-14,-15,-16,-17]])# 要更新的值,相加会全变成0
add = tf.scatter_nd_add(ref, indices, updates)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(add))
output:
[[[ 1 2 3 4]
[ 5 6 7 8]
[ 1 2 3 4]
[ 5 6 7 8]]
[[10 11 12 13]
[ 0 0 0 0]
[10 11 12 13]
[14 15 16 17]]]tf.Variable()
创建变量,在初始化值中指定数据维度和内容,其他东西有点多....,先关注简易版
必须指定初始化
__init__(
initial_value=None,
trainable=None,
collections=None,
validate_shape=True,
caching_device=None,
name=None,
variable_def=None,
dtype=None,
expected_shape=None,
import_scope=None,
constraint=None,
use_resource=None,
synchronization=tf.VariableSynchronization.AUTO,
aggregation=tf.VariableAggregation.NONE,
shape=None
)
import tensorflow as tf
import numpy as np
a1 = tf.Variable(tf.random_normal(shape=[2,3], mean=0, stddev=1), name='a1')
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(a1))
output:
[[ 0.1626461 1.4406685 0.2573926]
[-1.911016 -0.6992628 -0.8095152]]tf.get_variable()
获取已存在的变量,如果不存在,就新建一个,需要指定名称,可以用于参数共享
tf.get_variable(
name,
shape=None,
dtype=None,
initializer=None,
regularizer=None,
trainable=None,
collections=None,
caching_device=None,
partitioner=None,
validate_shape=True,
use_resource=None,
custom_getter=None,
constraint=None,
synchronization=tf.VariableSynchronization.AUTO,
aggregation=tf.VariableAggregation.NONE
)tf.variable_scope()
tf.variable_scope()与tf.get_variable()配合,用于实现变量共享
tf.name_scope()
tf.name_scope不会对tf.get_variable()创建的变量产生影响,用于管理命名空间
对于使用tf.Variable来说,tf.name_scope和tf.variable_scope功能一样,都是给变量加前缀,相当于分类管理,模块化。
对于tf.get_variable来说,tf.name_scope对其无效,也就是说tf认为当你使用tf.get_variable时,你只归属于tf.variable_scope来管理共享与否。
name_scope为命名域,variable_scope为变量域,
import tensorflow as tf
# x = tf.get_variable('x',shape=[32,32],initializer=tf.initializers.random_normal)
# y = tf.get_variable('y',shape=[32,32],initializer=tf.initializers.random_normal)
with tf.name_scope('name_scope'):
x = tf.get_variable('x',shape=[32,32],initializer=tf.initializers.random_normal)
y = tf.get_variable('y',shape=[32,32],initializer=tf.initializers.random_normal)
print(x.name,y.name)
with tf.variable_scope('variable_scope'):
x = tf.get_variable('x',shape=[32,32],initializer=tf.initializers.random_normal)
y = tf.get_variable('y',shape=[32,32],initializer=tf.initializers.random_normal)
print(x.name,y.name)
output:
x:0 y:0
variable_scope/x:0 variable_scope/y:0import tensorflow as tf
x = tf.placeholder(dtype=tf.float32,shape=(None,32,32,3))
with tf.variable_scope('extra/conv1'):
conv1 = tf.layers.conv2d(x,64,(3,3))
conv1 = tf.layers.batch_normalization(conv1)
print(conv1)
def extra(x):
with tf.variable_scope('extra',reuse=tf.AUTO_REUSE):
with tf.variable_scope('conv1'):
conv1 = tf.layers.conv2d(x,64,(3,3))
conv1 = tf.layers.batch_normalization(conv1)
print(conv1)
with tf.variable_scope('conv2'):
conv2 = tf.layers.conv2d(conv1,64,(3,3))
conv2 = tf.layers.batch_normalization(conv2)
print(conv2)
with tf.variable_scope('fc',reuse=tf.AUTO_REUSE):
fc = tf.layers.flatten(conv2)
logits = tf.layers.dense(fc,10)
print(logits)
return logits
y1 = extra(x)
y2 = extra(x)
vars = tf.trainable_variables()
for k,v in enumerate(vars):
print(k,v)
with tf.variable_scope('', reuse=tf.AUTO_REUSE):
bn = tf.get_variable(name='extra1/conv2/batch_normalization/gamma',shape=(64,))
print(bn)
output:
Tensor("extra/conv1/batch_normalization/FusedBatchNorm:0", shape=(?, 30, 30, 64), dtype=float32)
Tensor("extra/conv1_1/batch_normalization/FusedBatchNorm:0", shape=(?, 30, 30, 64), dtype=float32)
Tensor("extra/conv2/batch_normalization/FusedBatchNorm:0", shape=(?, 28, 28, 64), dtype=float32)
Tensor("fc/dense/BiasAdd:0", shape=(?, 10), dtype=float32)
Tensor("extra_1/conv1/batch_normalization/FusedBatchNorm:0", shape=(?, 30, 30, 64), dtype=float32)
Tensor("extra_1/conv2/batch_normalization/FusedBatchNorm:0", shape=(?, 28, 28, 64), dtype=float32)
Tensor("fc_1/dense/BiasAdd:0", shape=(?, 10), dtype=float32)
0 <tf.Variable 'extra/conv1/conv2d/kernel:0' shape=(3, 3, 3, 64) dtype=float32_ref>
1 <tf.Variable 'extra/conv1/conv2d/bias:0' shape=(64,) dtype=float32_ref>
2 <tf.Variable 'extra/conv1/batch_normalization/gamma:0' shape=(64,) dtype=float32_ref>
3 <tf.Variable 'extra/conv1/batch_normalization/beta:0' shape=(64,) dtype=float32_ref>
4 <tf.Variable 'extra/conv2/conv2d/kernel:0' shape=(3, 3, 64, 64) dtype=float32_ref>
5 <tf.Variable 'extra/conv2/conv2d/bias:0' shape=(64,) dtype=float32_ref>
6 <tf.Variable 'extra/conv2/batch_normalization/gamma:0' shape=(64,) dtype=float32_ref>
7 <tf.Variable 'extra/conv2/batch_normalization/beta:0' shape=(64,) dtype=float32_ref>
8 <tf.Variable 'fc/dense/kernel:0' shape=(50176, 10) dtype=float32_ref>
9 <tf.Variable 'fc/dense/bias:0' shape=(10,) dtype=float32_ref>
<tf.Variable 'extra1/conv2/batch_normalization/gamma:0' shape=(64,) dtype=float32_ref>为啥直接print变量,像extra,fc会添加后缀,成为extra_1,fc_1?
tf.get_collection(key,scope)
从一个集合中取出全部变量,是一个列表
tensorflow允许将变量与一个key关联,然后通过指定key来获取关联的变量,标准的key定义在tf.GraphKeys 中:
常见的key,tf.GraphKeys
GLOBAL_VARIABLES:
LOCAL_VARIABLES
MODEL_VARIABLES
TRAINALBEL_VARIABLES
REGULARIZATION_LOSSES
SUMMARIES
QUEUE_RUNNERS
VARIABLES
UPDATE_OPS
TRAIN_OP
SAVERS
WEIGHTS
BIASES
ACTIVATIONStf.group()
将一个op的list合并成一个op,创建一个新的op
op = tf.group(*[op1,op2])
tf.cond()
tensorflow中的判断语句
tf.cond(
pred,
true_fn=None,
false_fn=None,
name=None
)
pred:判断条件
true_fn:为真时调用此函数
false_fn:为假时调用此函数
import tensorflow as tf
a=tf.constant(2)
b=tf.constant(3)
x=tf.constant(4)
y=tf.constant(5)
z = tf.multiply(a, b)# 6
result = tf.cond(x > y, lambda: tf.add(x, z), lambda: tf.subtract(y,z))# 调用减法
with tf.Session() as session:
print(result.eval())
output:-1tf.clip_by_value():将t按照指定的最大和最小值进行截断
tf.clip_by_value(
t,
clip_value_min,
clip_value_max,
name=None
)













 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









