






 本文通过kaggle的泰坦尼克号数据集,利用机器学习算法构建模型,预测乘客的存活概率。数据预处理涉及填充缺失值、特征提取与选择,最终模型的准确率为80.0%。分析结果显示,女性、高舱位和特定头衔的乘客存活率较高。
本文通过kaggle的泰坦尼克号数据集,利用机器学习算法构建模型,预测乘客的存活概率。数据预处理涉及填充缺失值、特征提取与选择,最终模型的准确率为80.0%。分析结果显示,女性、高舱位和特定头衔的乘客存活率较高。
一、提出问题(Business Understanding )
1912年4月15日,泰坦尼克号在与冰山相撞之后,沉没于北大西洋。船上的2224名船员及乘客中,只有772人存活了下来,存活率只有32%。
泰坦尼克号沉没事故,为和平时期死伤人数最为惨重的一次海难。泰坦尼克号也变成了隐喻灾难性事故的象征符号,从此警醒世人。
那么,究竟什么样的人在这次事故中相对容易存活?这便是本次分析要处理的问题。
本次分析旨在:利用kaggle网站Titanic项目的数据集,建构一个机器学习的算法模型,以预测特定属性的人的存活概率。
二、理解数据(Data Understanding)
2.1采集数据
数据集来源于kaggle网站Titanic项目。

本次分析使用两个数据集:train.csv,test.csv。
2.2导入数据
为了方便之后的数据清洗,将两个导入的数据集进行合并。
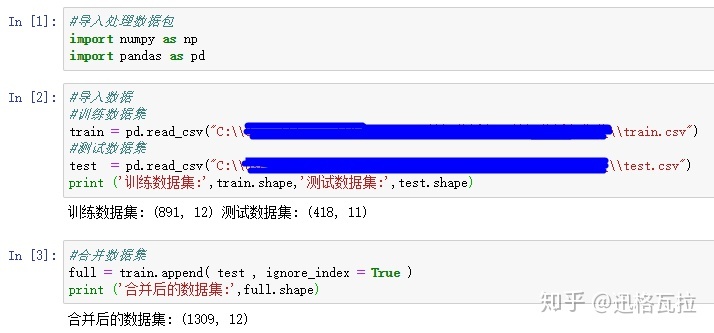
2.3查看数据集信息
1)合并数据集
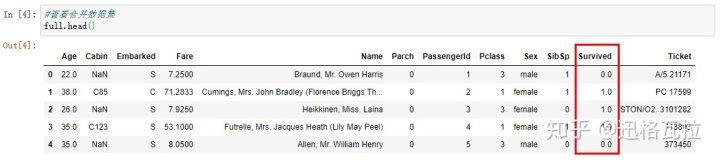
train.csv比test.csv集多了一个变量Survived,因此合并数据集(full)有418行数据在该维度下是空值。
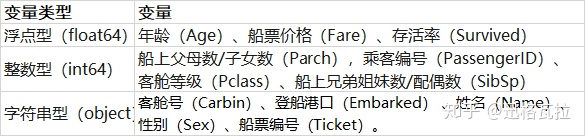
合并数据集(full)共计12个变量,其含义见下表:

2)查看合并数据集的描述统计信息
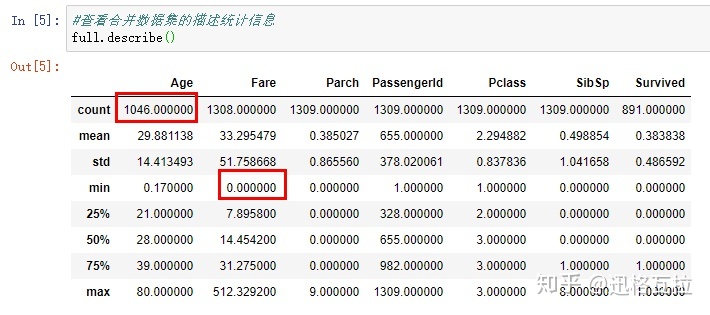
发现年龄行数较少、船票价格最小值为零两个异常值。
推测这两个变量存在着空值,后续需要清洗。
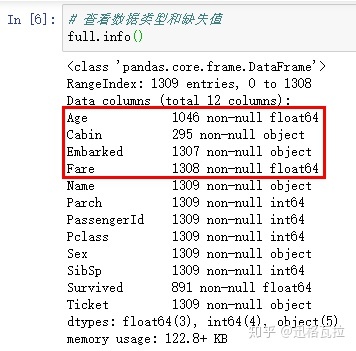
3)查看合并数据集的变量类型和缺失值
变量类型总共三类:
数据集总共1309行,有缺失值的变量总共四种(Survived是标签,不属于缺失值范围):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 431
431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









