






上一关,我们学习了Scrapy框架,知道了Scrapy爬虫公司的结构和工作原理。
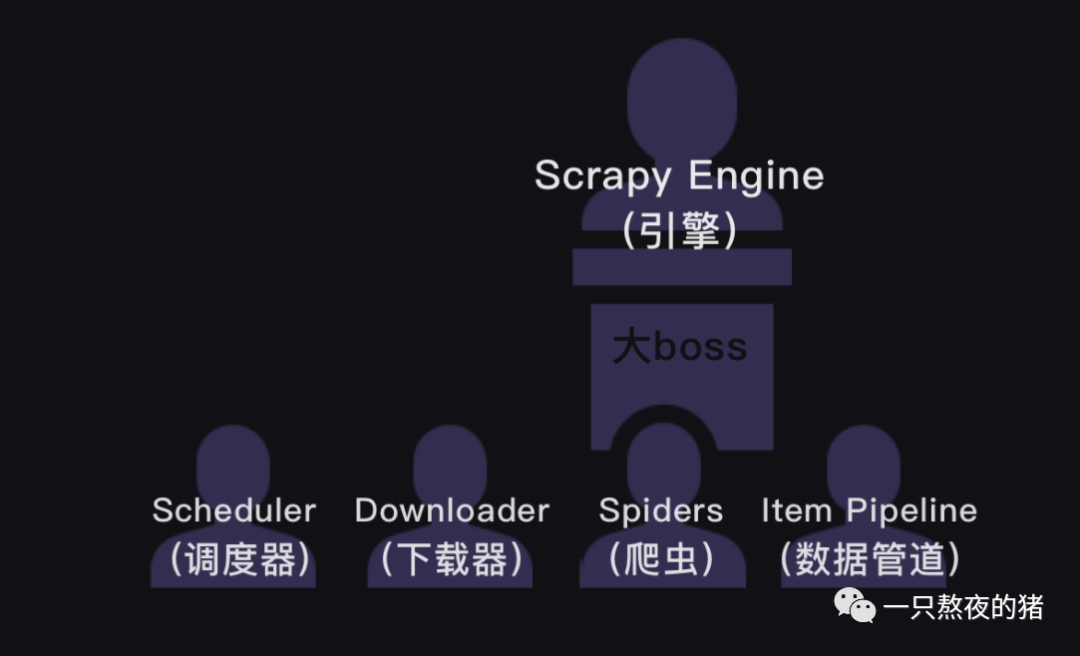
在Scrapy爬虫公司里,引擎是最大的boss,统领着调度器、下载器、爬虫和数据管道四大部门。这四大部门都听命于引擎,视引擎的需求为最高需求。
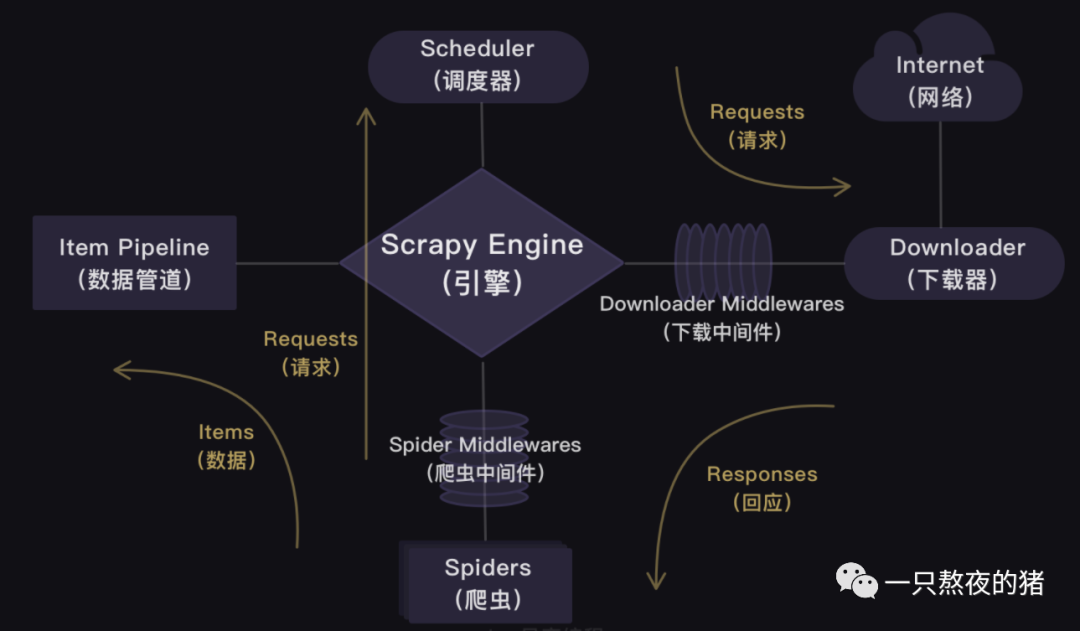
这一关,我会带你实操一个更大的项目——用Scrapy爬取招聘网站的招聘信息。
你可以借此体验一把当Scrapy爬虫公司CEO的感觉,用代码控制并操作整个Scrapy的运行。
那我们爬取什么招聘网站呢?在众多招聘网站中,我挑选了职友集。这个网站可以通过索引的方式,搜索到全国上百家招聘网站的最新职位。
现在,请你用浏览器打开职友集的网址链接(一定要打开哦):
https://www.jobui.com/rank/company/
我们先对这个网站做初步的观察,这样我们才能明确项目的爬取目标。
1 明确目标
打开网址后,你会发现:这是职友集网站的地区企业排行榜。
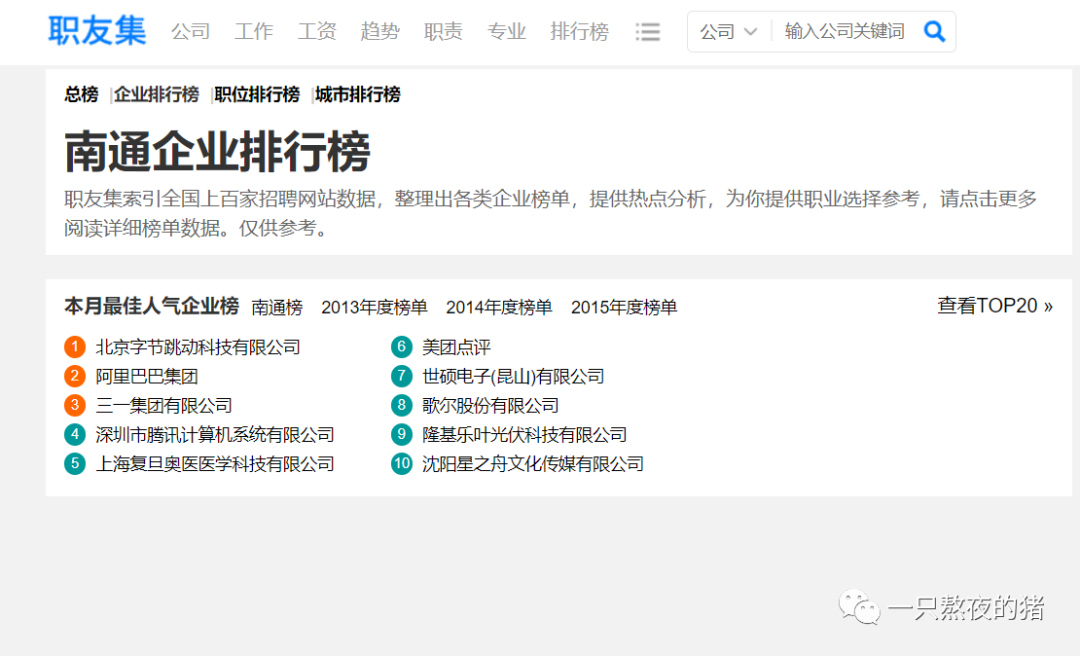
点击【北京字节跳动科技有限公司】,会跳转到这家公司的详情页面,再点击【招聘】,就能看到这家公司正在招聘的所有岗位信息。
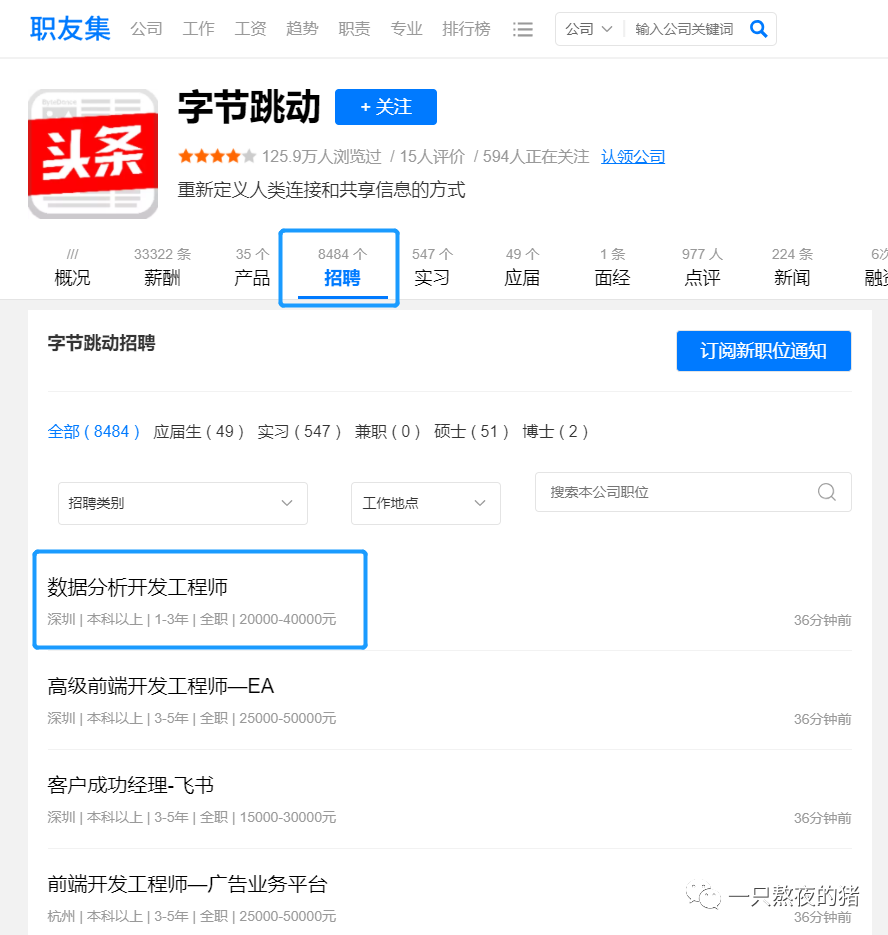
初步观察后,我们可以把爬取目标定为:先爬取企业排行榜榜单里的公司,再接着爬取这些公司的招聘信息。每个榜单有10家公司,也就是说,我们要先从企业排行榜爬取到这10家公司,再跳转到这10家公司的招聘信息页面,爬取到公司名称、职位、工作地点和招聘要求。
2 分析过程
明确完目标,我们开始分析过程。首先,要看企业排行榜里的公司信息藏在了哪里。
2.1 企业排行榜的公司信息
请你右击打开“检查”工具,点击Network,刷新页面。点开第0个请求company/,看Response,找一下有没有榜单的公司信息在里面。
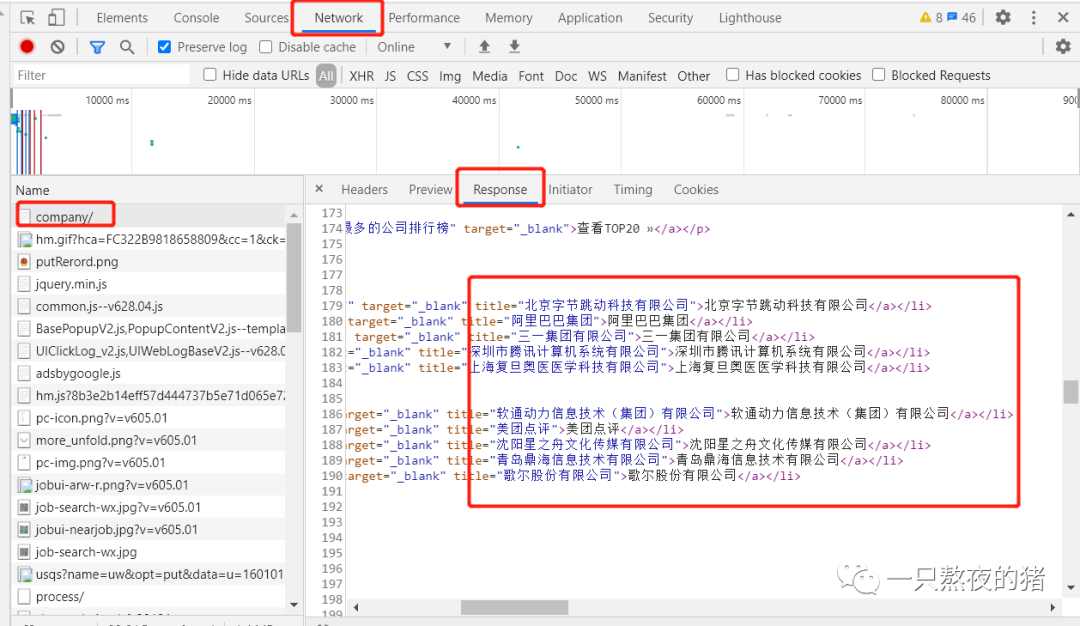
一找,发榜单的所有公司信息都在里面。说明企业排行榜的公司信息就藏在html里。现在请你点击Elements,点亮光标,再把鼠标移到【北京字节跳动科技有限公司】,这时就会定位到含有这家公司信息的元素上。
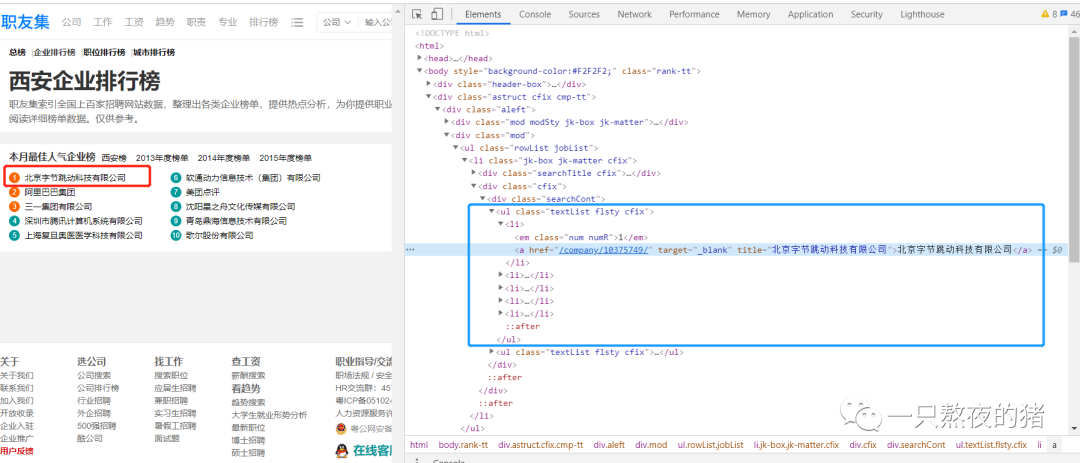
点击href="/company/10375749/",会跳转到字节跳动这家公司的详情页面。详情页面的网址是:https://www.jobui.com/company/10375749/
你再把鼠标移到【阿里巴巴集团】,点击href="/company/281097/",会跳转到阿里公司的详情页面,页面的网址为:
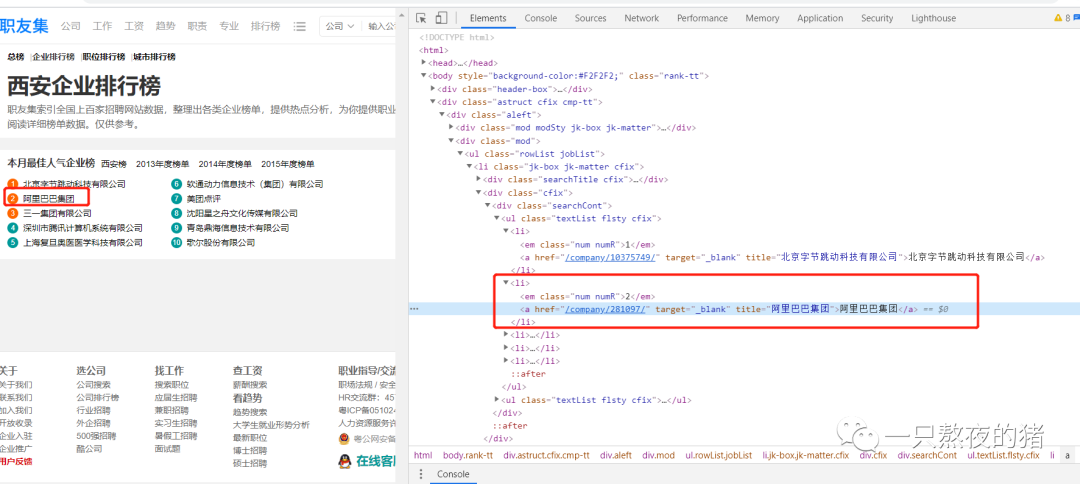
https://www.jobui.com/company/281097/
我们可以猜到:/company/+数字/应该是公司id的标识。这么一观察,榜单上的公司详情页面的网址规律我们就得出来了。

那么,我们只要把元素的href属性的值提取出来,就能构造出每家公司详情页面的网址。构造公司详情页面的网址是为了后面能获得详情页面里的招聘信息。现在,我们来分析html的结构,看看怎样才能把元素href属性的值提取出来。
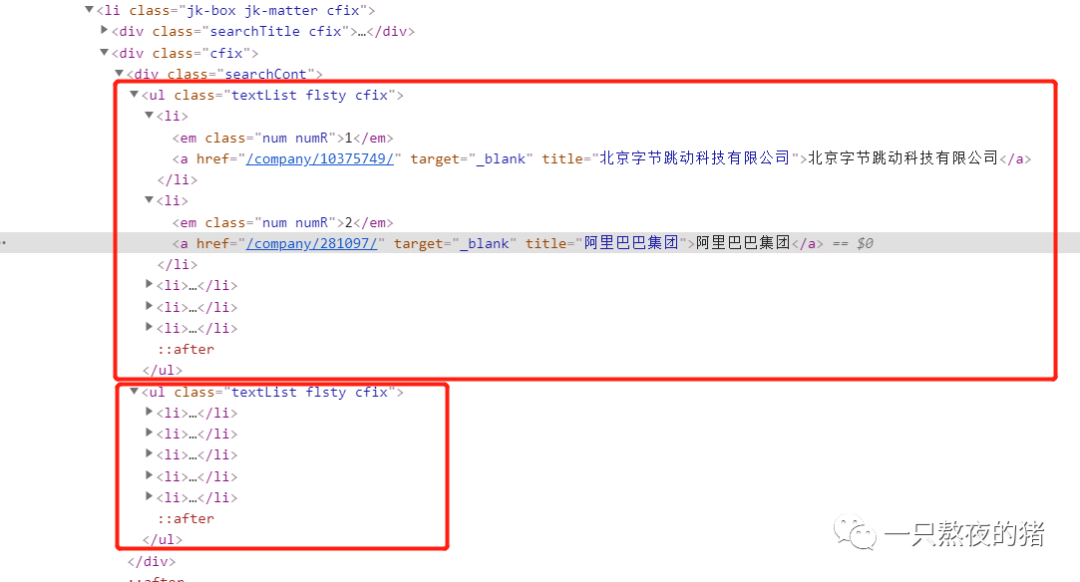
仔细观察html的结构,你会发现,每个公司信息都藏在一个元素里,而每5个元素都从属与一个
- 标签。这是一个层层嵌套的关系。我们想拿到所有
接下来,我们需要分析的就是,每家公司的详情页面。
2.2 公司详情页面的招聘信息
我们打开【北京字节跳动科技有限公司】的详情页面,点击【招聘】。这时,网址会发生变化,多了jobs的参数。
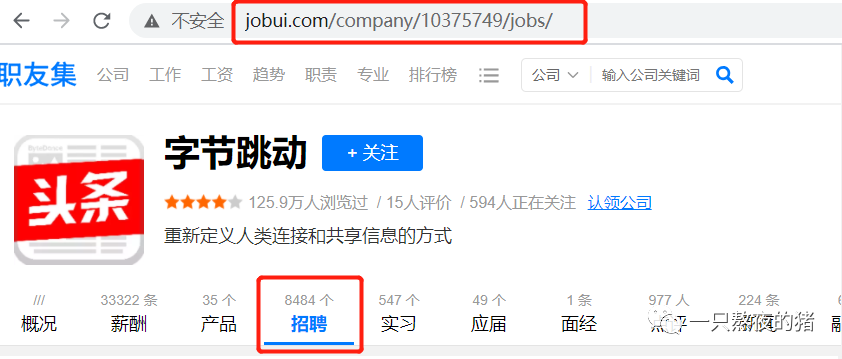
如果你多点击几家公司的详情页面,查看招聘信息,就会知道:公司招聘信息的网址规律也是有规律的。比如,阿里的招聘信息的网址是:
https://www.jobui.com/company/281097/jobs/

接着,我们需要找找看公司的招聘信息都存在了哪里。
还是在字节跳动公司的招聘信息页面,右击打开“检查”工具,点击Network,刷新页面。我们点击第0个请求jobs/,查看Response,翻找看看里面有没有这家公司的招聘信息。
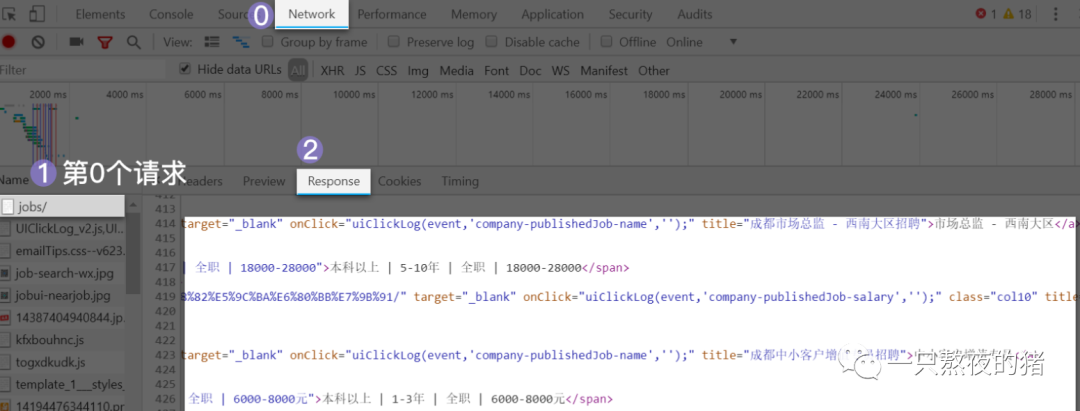
在Response里我们找到了想要的招聘信息。这说明公司的招聘信息依旧是藏在了html里。接下来,你应该知道要分析什么了吧。分析的套路都是相同的,知道数据藏在html后,接着是分析html的结构,想办法提取出我们想要的数据。那就按照惯例点击Elements,然后点亮光标,把鼠标移到公司名称吧。
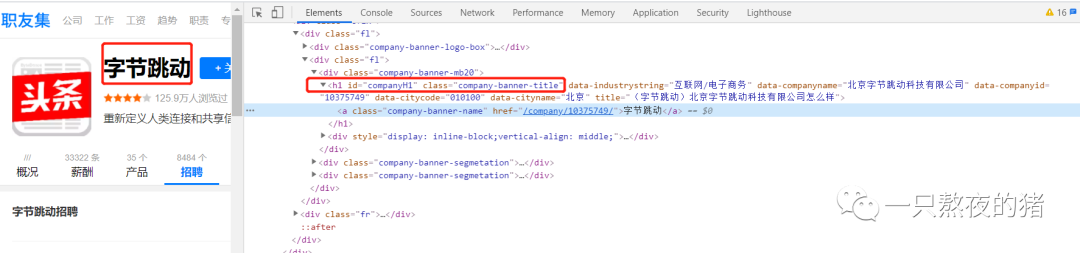
公司名称藏在
不过经过我几次的操作试验,发现职友集这个网站间隔一段时间就会更换这个标签的名字(可能你此时看到的标签名不一定是
为了保证一定能取到公司名称,我们改成用id属性(id="companyH1")来定位这个标签。这样,不管这个标签名字如何更换,我们依旧能抓到它。下面,再把鼠标移到岗位名称,看看招聘的岗位信息可以怎么提取。
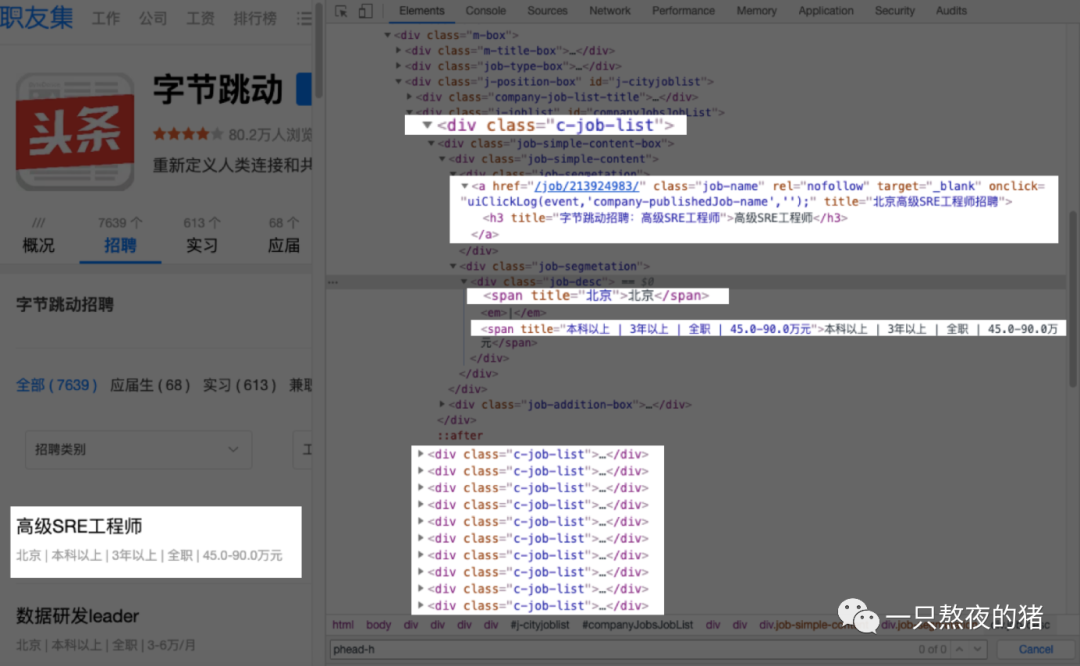
你会发现:每个岗位的信息都藏在一个















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









