





混淆矩阵和分类报告为一组特定的预测提供了非常详尽的分析,但是,预测本身已经丢弃了模型中的某些信息。正如前面所说的那样,大部分分类器都提供了一个decision_function或predict_proba方法来评估预测不确定度。预测可被看作是以某个固定点作为decision_或predict_proba输出的阈值——在二分类问题中,我们使用0作为决策函数的阈值,0.5作为predict_proba的阈值。
下面我们以一个不平衡的二分类作为示例说明:反类中有400个点,而正类只有50个点。使用SVM函数来训练模型,对应代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.svm import SVC
import mglearn
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
from mglearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
x,y=make_blobs(n_samples=(400,50), centers=2, cluster_std=(7,2), random_state=22)
x_train, x_test, y_train, y_test=train_test_split(x, y, random_state=22)
svc=SVC(gamma=0.5).fit(x_train, y_train)
mglearn.plots.plot_decision_threshold()
#使用classification_report函数来评估两个类别的准确率与召唤率
print("Classification report values:")
print(classification_report(y_test, svc.predict(x_test)))
运行后其结果如下:
Classification report values:
precision recall f1-score support
0 0.92 0.95 0.94 102
1 0.38 0.27 0.32 11
avg / total 0.87 0.88 0.88 113

决策函数的热图与改变决策阈值的影响
从运行结果得知,对于类别1,我们得到了一个相当低的准确率,不过类别0的准确率却是不错,所以分类器将重点放在类别0分类正确,而不是类别1.
假设我们在应用中,类别1具有高召回率更加重要,如癌症筛查(我们允许自动筛查的时候自动检查到的为癌症的人通过人工检查没有得到癌症,但是不允许本人已经得到癌症了但是自动检查却将其漏过,这样会使得病人错过最佳治疗时期)。这意味着我们更愿意冒险有更多的假正例(假的类别为1),以换取更多的真正例(可以增大召回率)。
svc.predict生成的预测无法满足这个要求,但是我们可以通过改变决策阈值不等于0来将预测重点放在类别1的召回率上。默认情况下,decision_function值大于0的点将被规划为类别1,我们希望将更多的点划为类别1,所以需要减少阈值。对应代码如下:
y_pred_lower_threshold = svc.decision_function(x_test) > -.8
#我们来看一下这个预测报告:
print("The new Classification report values:")
print(classification_report(y_test, y_pred_lower_threshold))
上述代码运行后其结果为:
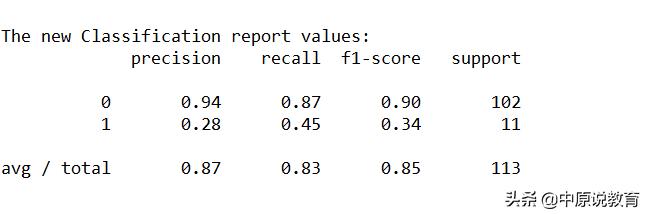
将阈值调整为接近为0的正数后的report结果
通过调整后,类别1的召回率增大,准确率降低。但是得到了更大的空间区域化为类别1.当然,如果需要的是更高的准确率的话,那么也通过改变与之的方法得到更好的结果。由于decision_function的取值很能在任意范围,所以很难提供关于如果选取与之经验的法则(注意:如果设置了阈值,该方法不能用在测试集上,这可能会导致得到的预测结果过于乐观,可以使用验证集或交叉验证来代替)。
我们将上述classification report结果可视化:
fig=plt.figure()
ax=fig.add_subplot(1, 1, 1)
mglearn.plot_helpers.discrete_scatter(x_train[:,0], x_train[:,1], y_train,ax=ax)
mglearn.tools.plot_2d_separator(svc,x_train, linewidth=3, ax=ax, threshold=-0.8)
运行后其结果为:
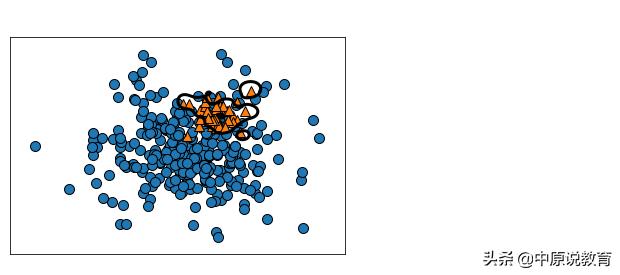
classification report热图
对于实现了predict_proba方法的模型来说,选择阈值可能更简单,因为predict_proba的输出固定在0-1之间,表示的是概率。默认情况下,0.5的阈值表示,如果模型已超过50%的概率“确信”一个点属于正类,那么就将其划分为正类,增大这个阈值意味着模型需要更加确信才能够做出正类的判断(较低成都的确信度就可以作为反类判断)。尽管使用概率可能比使用任意阈值更加直观,但是并非所有的模型都提供了不确定性的实际模型。














 2987
2987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









