







使用Cloudera Manager搭建Hive服务
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.安装Hive环境
1>.进入CM服务安装向导

2>.选择需要安装的hive服务
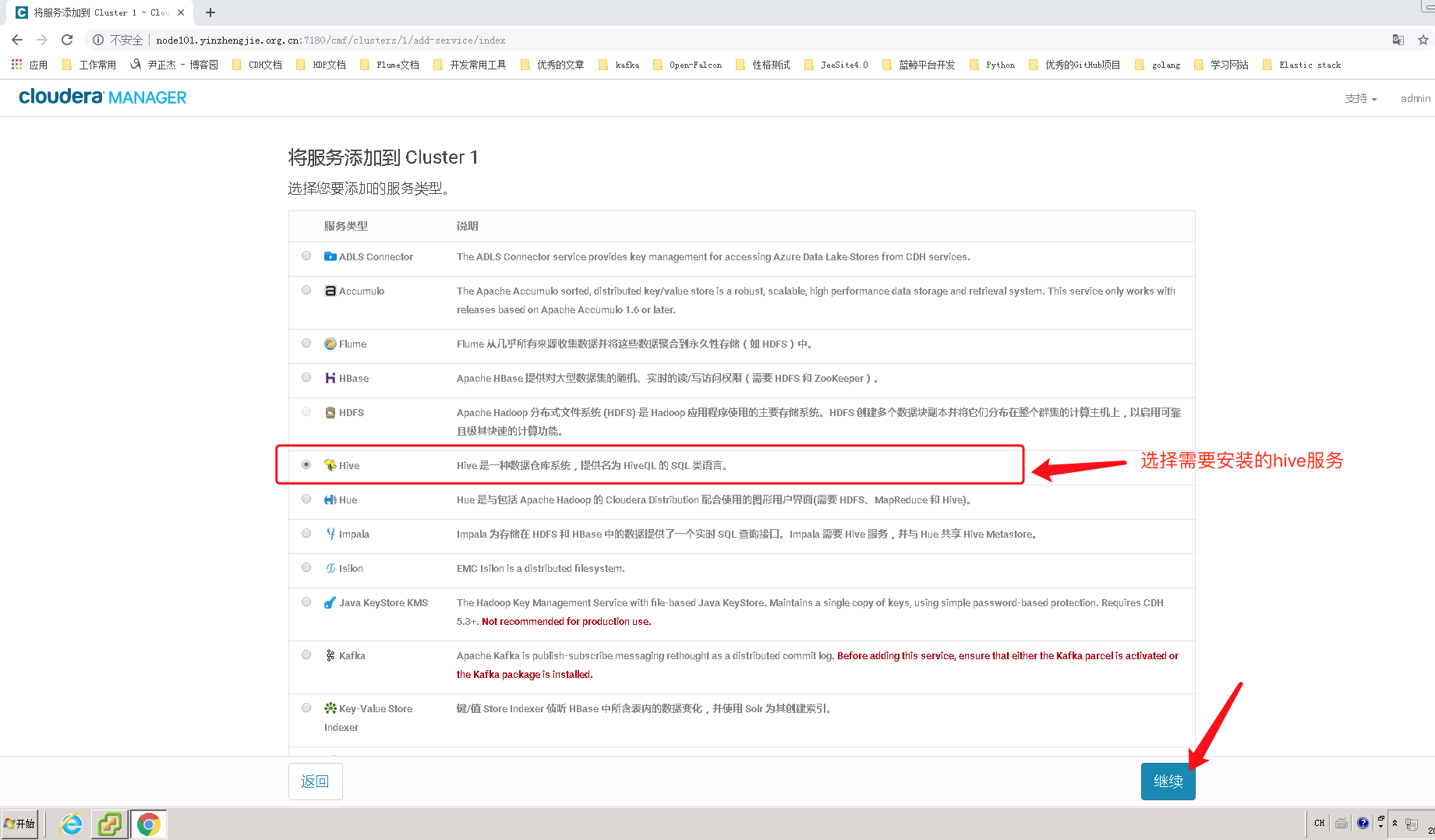
3>.选择hive的依赖环境,我们选择第一个即可(hive不仅仅可以使用mr计算,还可以使用tez计算哟~)
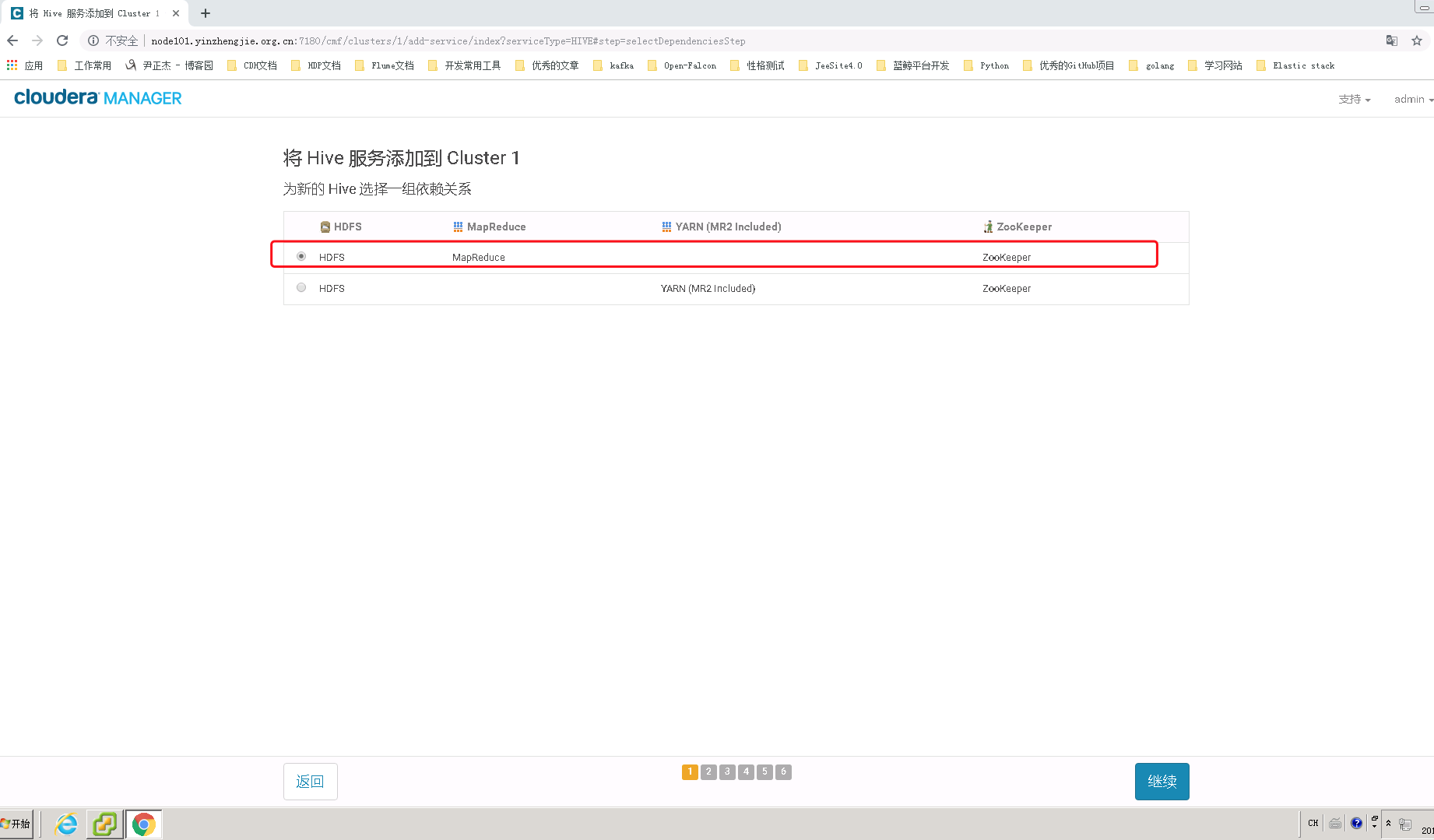
4>.为Hive分配角色


Hive Metastore是管理和存储元信息的服务,它保存了数据库的基本信息以及数据表的定义等,为了能够可靠地保存这些元信息,Hive Metastore一般将它们持久化到关系型数据库中,默认采用了嵌入式数据库Derby(数据存放在内存中),用户可以根据需要启用其他数据库,比如MySQL。
推荐阅读:https://www.cnblogs.com/yinzhengjie/p/10836132.html
Hive Metastore 简介戳我
HCatalog是Hadoop中的表和存储管理层,能够支持用户用不同的工具(Pig、MapReduce)更容易地表格化读写数据。
HCatalog从Apache孵化器毕业,并于2013年3月26日与Hive项目合并。
Hive版本0.11.0是包含HCatalog的第一个版本。(随Hive一起安装),CDH 5.15.1默认使用的是Hive版本为:1.1.0+cdh5.15.1+1395,即Apache Hive 1.1.0版本。
HCatalog的表抽象向用户提供了Hadoop分布式文件系统(HDFS)中数据的关系视图,并确保用户不必担心数据存储在哪里或以什么格式存储-RCFile格式,文本文件,SequenceFiles或ORC文件。
HCatalog支持读写任意格式的SerDe(序列化-反序列化)文件。默认情况下,HCatalog支持RCFile,CSV,JSON和SequenceFile以及ORC文件格式。要使用自定义格式,您必须提供InputFormat,OutputFormat和SerDe。
HCatalog构建于Hive metastore,并包含Hive的DDL。HCatalog为Pig和MapReduce提供读写接口,并使用Hive的命令行界面发布数据定义和元数据探索命令。
HCatalog 简介戳我
HiveServer2(HS2)是一个服务端接口,使远程客户端可以执行对Hive的查询并返回结果。目前基于Thrift RPC的实现是HiveServer的改进版本,并支持多客户端并发和身份验证
启动hiveServer2服务后,就可以使用jdbc,odbc,或者thrift的方式连接。 用java编码jdbc或则beeline连接使用jdbc的方式,据说hue是用thrift的方式连接的hive服务。
HiveServer2 简介戳我
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









