





继之前我们讲解了“惩罚回归”与“支持向量机”后,我们在本节将对K近邻与决策树算法进行讲解。
K近邻
K近邻(K-nearestneighbor,KNN)是一种有监督学习方法,常用于分类,有时也用于回归。这个方法是通过发现新数据和现有数据之间的相似点(“接近度”)来对新数据进行分类。
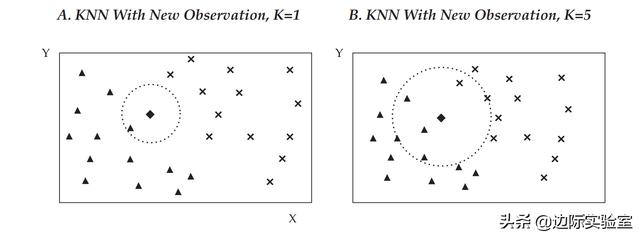
回到我们在上一节讲的散点图,我们假设有一个新的观察结果:新的菱形需要被归类为叉号或三角形的类别。如果k=1,则该菱形将被归入其最近邻居的类别(即,左边的三角形)。下面右边的图展示了k=5的情况,此算法将查看菱形5个最近的邻居,即3个三角形和2个叉号。决策依据是考虑5个分类中邻居数量最大的分类。因此,菱形被归类为三角形。
假设我们有一个信用评级分类的公司债券数据库,其中还包含这些债券特征的详细信息。这些特征包括:发行企业的特征(例如,资产规模、行业、杠杆率、现金流比率)和债券本身的特征(例如,期限、固定/浮动息票、嵌入期权)。现在,假设一种没有信用评级的新债券即将发行。从本质上讲,具有相似发行企业和债券特征的公司债券应该被给予相似的信用评级。因此,通过使用KNN,我们可以根据新债券的特征与我们数据库中老债券的特征的相似性来预测新债券的隐含信用评级。
KNN是一个简单直观的模型。它的强大之处在于它是非参数的;该模型对数据的分布没有任何假设。此外,它还可以直接用于多类别分类。然而,KNN面临的一个关键挑战是怎样定义“相似”(或接近)。除了特征的选择外,对于距离的度量是重要的决策项,不恰当的度量将生成性能较差的模型。
对于有序数据或分类数据,选择正确的距离度量可能是结果更加主观。例如,如果分析师正在研究各种股票的市场表现出的相似性,他可能会考虑使用股票历史回报率之间的相关性作为衡量相似性的适当方法。
对数据及业务的分析能力是衡量相似性的关键。KNN的结果可能对不相关或高相关的特征很敏感,因此可能需要手动选择这些特征。通过这样做,分析人员删除了不太有价值的信息,以保留最相关的信息。如果处理正确,这个过程应该产生一个更有代表性的距离测量。KNN算法一般在特征较少的条件下结果更好。
最后,在选择模型的超参数k时,必须考虑到k值的不同会导致不同的结论。例如,要预测未评级债券的信用评级,k到底应该是与未评级债券最相似的3种、15种还是50种债券?如果k是偶数,相邻分类的数目可能会相等,这就导致没有明确的分类。为k选择一个太小的值会导致很高的错误率和对局部异常值较强的敏感性,但是为k选择一个太大的值又会稀释最近邻居的解释性,因为会对太多的结果求平均值。在实践中,可以使用几种不同的技术来确定k的最优值,同时考虑类别的数量和特征空间的划分。KNN算法在投资行业有很多应用,包括破产预测、股价预测、公司债券信用评级分配、定制股票和债券指数创建等。
分类与回归树
分类与回归树(Classificationand Regression Tree,CART)是另一种常见的监督机器学习技术,可用于预测产生分类树的分类目标变量或产生回归树的连续目标变量。CART常用于二进制分类或回归。
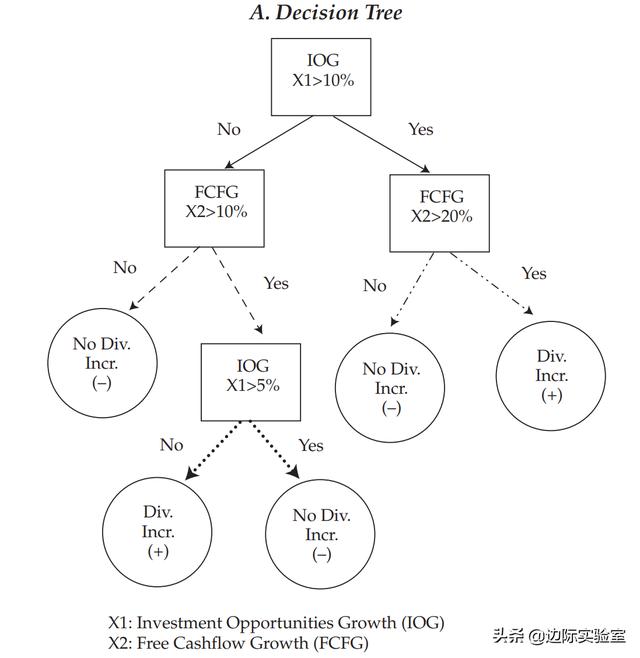
我们用一个简化的公司分类模型对CART进行讨论,分类依据是公司是否增加了向股东支付的股息。该分类需要一个二叉树:一个初始根节点、决策节点和终止节点的组合。根节点和每个决策节点表示单个特征(f)和该特征的截断值(c)。如下表所示,我们从一个新数据点的初始根节点开始。在这种情况下,初始根节点表示特征的投资机会增长(IOG),指定为X1,截断值为10%。从初始根节点开始,在决策节点处将数据划分为越来越小的子组,直到包含预测标签的终止节点。在这种情况下,预测的标签是股息增加(加号)或无股息增加(减号)。
如果特征IOG(X1)的值大于10%(Yes),那么我们将进入自由现金流增长(FCFG)的决策节点(X2),其截断值为20%。如果FCFG的值不大于20%(No),则CART将预测数据点属于无股息增加(dash)类别,到达一个终止节点。相反,如果X2的值大于20%(Yes),则CART将预测数据点属于股息增加(cross)类别到达另一个终端节点。
需要注意的是,同一个的特征可能与其他特征一起多次出现在树中。例如,回到初始根节点,如果IOG不大于10%(X1≤10%),且FCFG大于10%,则IOG将再次作为另一个决策节点出现,但这次它位于树的较低位置,截断值为5%。
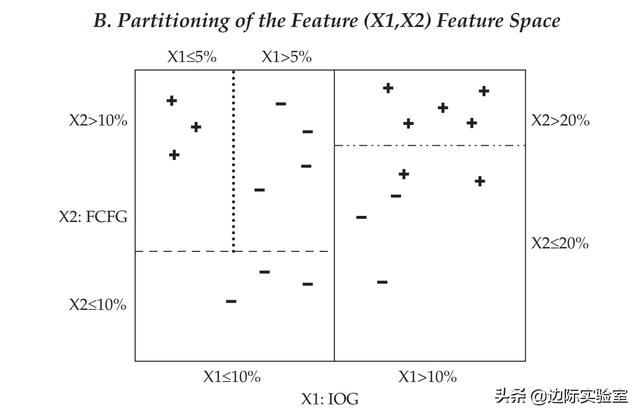
现在我们讨论CART算法如何选择特性和相对应的截止值。最初,分类模型是从标记的数据中训练出来的,在我们上述的案例中,有10个公司增加了股息(加号),10个公司没有增加股息(减号)。如上表中的B表所示,在初始根节点处和每个决策节点处,特征空间(即X1和X2)定义的平面被分割成两个矩形,其值分别位于该节点所表示特征的截止值之上和之下。这与A表中决策节点发出线的图形相比,有着不同的模式。
CART算法在每个节点上选择的特征和截止值取决于对标记数据进行了最大范围的分离,以最小化分类误差(例如均值平方误差)。在每个决策节点之后,特征空间的划分越来越小,使得每组的观测值组内的误差比之前更小。在树的任一级别上,如果分类误差没有从另一个分支(分岔)中减少太多时,分类进程停止。这样的节点是终止节点,如果是分类模型,算法在终止节点的预测值就是该数据点上最多的一种类别。例如,在B表中,特征空间右上角的矩形,代表IOG(X1)>10%和FCFG(X2)>20%,包含5个加号,是分区中最多的数据点类别。因此,CART会预测属于这一空间的新数据同样具有这一特征(股息增加)。但是,如果新数据点的IOG(X1)>10%和FCFG(X2)≤20%,则预测该数据点将属于减号(无股息增加)类——该空间(右下角的矩形)里有2个加号、3个减号。如果是回归模型,那么每个终止节点的预测值就是标记值的平均值。
CART不对训练数据的特征进行任何假设,因此,在没有约束的条件下,它可以完美地学习训练数据。为了避免过拟合,可以添加约束参数,例如树的最大深度、节点的最小数目或决策节点的最大数目。一旦达到约束准则,模型就停止构建节点的迭代过程。例如,在图B中,特征空间左上角的矩形(X1≤10%,X2>10%和X1≤5%,包含三个加号)可能是根据终止节点最小数目等于3的约束准则得出的。或者可以通过修剪技术减少树的大小,来对模型进行约束。该技术将树种几乎无法提供分类能力的部分修剪(删除)掉。
通过迭代结构,CART可以发现其他模型无法解释的特征之间的复杂依赖性。如我们此前的案例所示,同一特征可以与其他特征组合出现数次,并且只有在满足一定条件的情况下,某些特征才有意义。
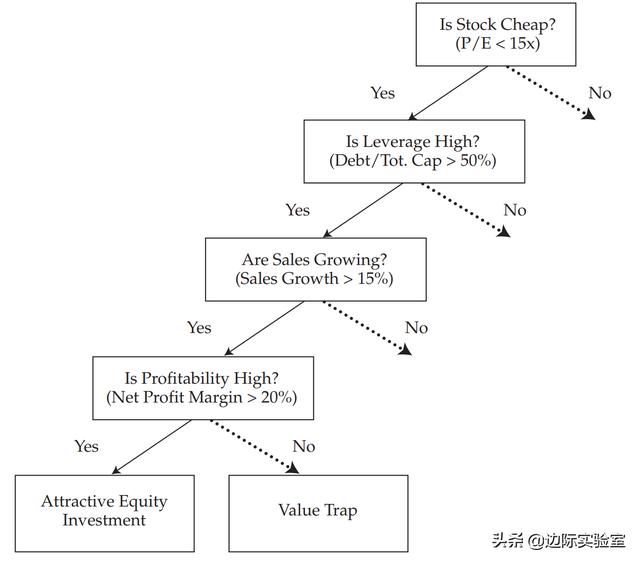
如下表所示,高盈利能力是预测股票是否具有吸引力的关键特征。不过,只有当股票价格便宜(P/E小于15)、杠杆率很高(债务占总资本的比率>50%),并且销售正在扩张(销售额增长>15%)的时候该特征才有意义。换句话说,在这种情况下,如果股票价格不便宜、杠杆率不高以及销售没有扩张,那么高利润率就无关紧要。我们如果用多元线性回归难以发现这种关系。
CART是一种流行的有监督机器学习模型,因为树为预测提供了可视化的解释。这与通常被认为存在“黑箱”的其他算法形成了显著的对比。如果模型存在“黑箱”,很难理解它们结果背后的原因。CART是为决策过程构建了专家工具,它在有噪声的数据和特征之间有效地对复杂关系进行了归纳总结。CART在投资管理中的典型应用包括:对财务报表欺诈的检测,对股票和固定收益产品的选择中产生一致的决策,以及简化与客户的投资策略沟通。
本文由边际实验室原创,转载请务必注明出处。
更多机器学习内容,请关注“边际实验室”。
如果喜欢本文,请点“在看”让更多人看到。
原创不易,感谢您的支持!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









