





# 废话
目前在工作中写脚本的时候发现了一些之前开源的apiAutoTest的可优化项,后面应该也是会慢慢的继续优化了
# 2020/11/19
截止到写这篇文章的时间是,2020/11/19 00:53 现在也是把该项优化了,那优化了什么尼?
# 参数依赖
我理解的参数依赖/接口依赖就是接口进行关联操作,比如有些查询接口需要登录之后才可以操作,那么我们就需要拿到token之类的东西,这一部分东西是放到header中的,apiAutoTest围绕的只有路径参数依赖,请求数据依赖
- 路径参数依赖
譬如说现在的restful,一个users接口,路由一般这样的`users`他的请求方式是get,这个路由我们把他认为是查所有用户,如果查某一个用户可能是这样的`users/:id`也是个get请求,这里这个id想表达的意思是这里有个需要个用户id的参数,比如1-500里面的任意1个,也就是说这个id是可变的,可以从登录接口的返回响应取一个叫userId的值
- 请求参数依赖
这个应该好理解些,就是说支付接口需要的订单id,是从上一步提交订单接口返回的响应订单id
# 更新后的效果
由于在改动时发现了之前的代码挺绕的,而且都没什么帮助所以就不说了,如果对之前的感兴趣可以看这里:https://testerhome.com/topics/25003 , 下面上新版用例截图
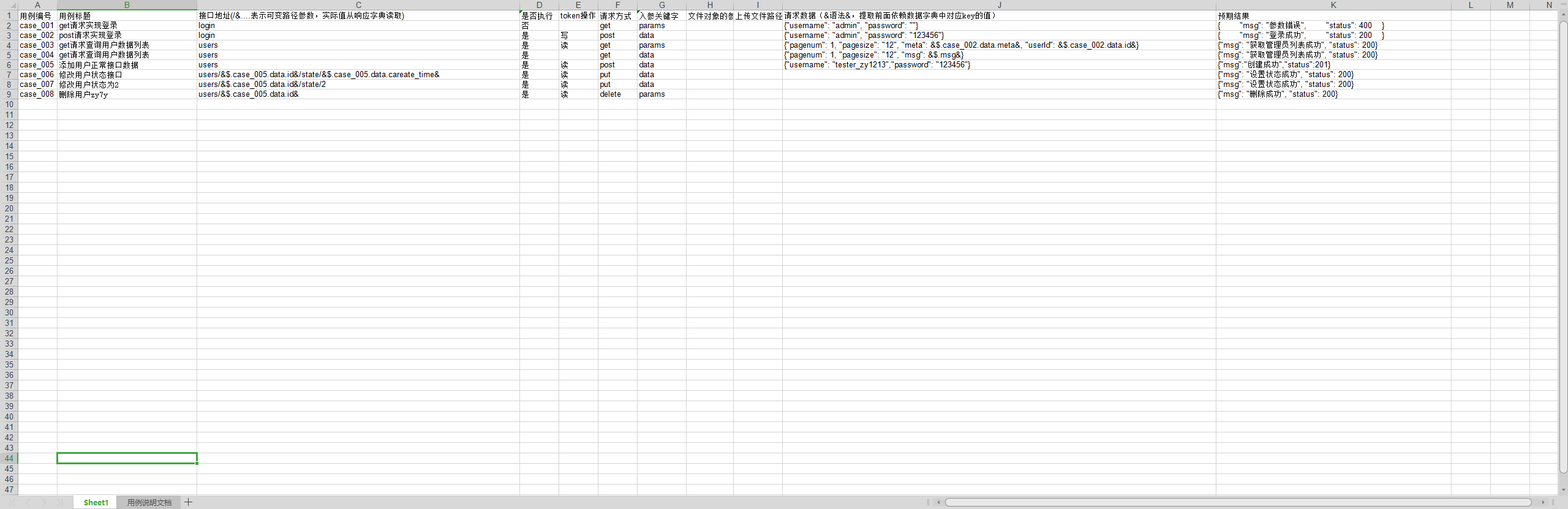
- 关于文件改动,新增了`data_process.py`文件里面封装了请求保存实际结果响应,path参数处理,请求数据处理
```python
#!/usr/bin/env/python3
# -*- coding:utf-8 -*-
"""
@project: apiAutoTest
@author: zy7y
@file: data_process.py
@ide: PyCharm
@time: 2020/11/18
"""
import json
import re
from tools import *
class DataProcess:
response_dict = {}
header = {}
null_header = {}
@classmethod
def save_response(cls, key: str, value: object) -> None:
"""
保存实际响应
:param key: 保存字典中的key,一般使用用例编号
:param value: 保存字典中的value,使用json响应
"""
cls.response_dict[key] = value
logger.info(f'添加key: {key}, 对应value: {value}')
@classmethod
def handle_path(cls, path_str: str = '') -> str:
"""路径参数处理
:param path_str: 带提取表达式的字符串 /&$.case_005.data.id&/state/&$.case_005.data.create_time&
上述内容表示,从响应字典中提取到case_005字典里data字典里id的值,假设是500,后面&$.case_005.data.create_time& 类似,最终提取结果
return /511/state/1605711095
"""
# /&$.case.data.id&/state/&$.case_005.data.create_time&
for i in re.findall('&(.*?)&', path_str):
path_str = path_str.replace(f'&{i}&', str(extractor(cls.response_dict, i)))
logger.info(f'提取出的路径地址: {path_str}')
return path_str
@classmethod
def handle_header(cls, is_token: str, response: dict, reg) -> dict:
"""处理header"""
if is_token == '写':
cls.header['Authorization'] = extractor(response, reg)
return cls.header
elif is_token == '':
return cls.null_header
else:
return cls.header
@classmethod
def handle_data(cls, variable: str) -> dict:
"""请求数据处理
:param variable: 请求数据,传入的是可转换字典/json的字符串,其中可以包含变量表达式
return 处理之后的json/dict类型的字典数据
"""
if variable == '':
return
for i in re.findall('&(.*?)&', variable):
variable = variable.replace(f'&{i}&', str(extractor(cls.response_dict, i)))
if 'null' in variable:
variable = variable.replace('null', 'None')
if 'true' in variable:
variable = variable.replace('true', 'True')
if 'false' in variable:
variable = variable.replace('false', 'False')
logger.info(f'最终的请求数据如下: {variable}')
return eval(variable)
```
相比之前这种写法应该更加清晰,然后之前的请求数据是采用字典合并的方式,在请求数据多层结构的时候会出现bug,现在改成了文本替换之后转json/dict的方法
# 新版依赖数据如何使用
**举个例子**
假设现在有个实际响应结果字典如下
```json
{"case_002": {
"data": {
"id": 500,
"username": "admin",
"mobile": "12345678",
}},
"case_005": {
"data": {
"id": 511,
"create_time": 1605711095
},
}
}
```
- excel中接口路径内容:`users/&$.case_005.data.id&/state/&$.case_005.data.careate_time&`
代码内部解析后如下:`users/511/state/1605711095`
`&$.case_005.data.id&` 代表从响应字典中提取case_005字典中data字典中的id的值,提取出来的结果是511
- excel中请求参数内容如下:
```json
{
"pagenum": 1,
"pagesize": "12",
"data": &$.case_005.data&,
"userId": &$.case_002.data.id&
}
```
代码内部解析后如下:
```json
{
"pagenum": 1,
"pagesize": "12",
"meta": {
"id": 511,
"create_time": 1605711095
},
"userId": 500
}
```
**其实不难看出其中规则`&jsonpath提取语法&`,如果你需要的内容是字符串类型,只需要这样`"&jsonpath提取语法&"`**
# 源码地址
github: https://github.com/zy7y/apiAutoTest.git
gitee: https://gitee.com/zy7y/apiAutoTest.git
# 道谢
谢谢各位的点评,在实际工作写到之后发现之前的写法的确不如意,希望多写,然后进步~晚安
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









