





首先需要要理解什么是并发和并行,这些概念我在Linux编程专题中也提过
并发:在同一个核心的CPU中,同一个时刻,只能有一条指令执行,但多个进程指令被操作系统内核快速轮换执行,使得在宏观上具有多个进程同时执行的效果。

我们用一个生动的例子来做说明,例如有两行排队的顾客,只有一个服务员在两个队列中来回切换处理两行队列的顾客需求,我们说服务员可以比喻为CPU,两行顾客队列可以比作2个不同线程请求
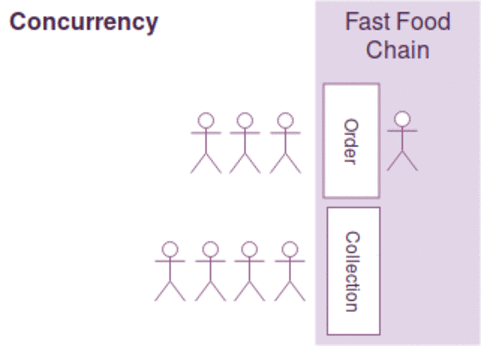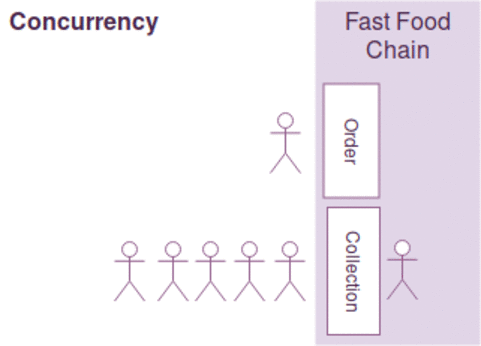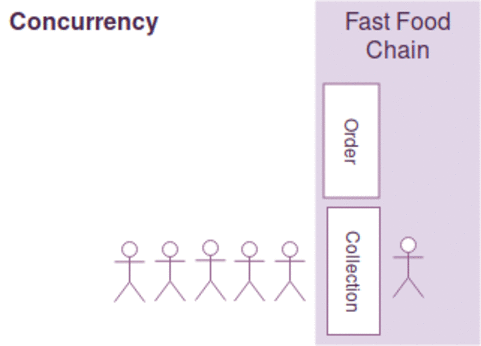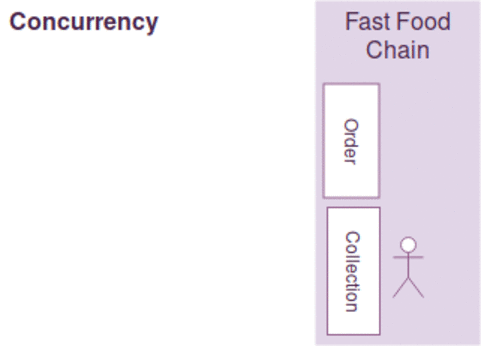
并行:是指在同一个时刻,有多条指令在多个CPU核心上同时执行。当然可以指两个不同的进程位于被调度到不同的CPU核心,也可以不同的线程位于不同的CPU核心中执行,典型的例子Java。
线程编程模式中还有两个重要的概念就是 同步和异步
同步:彼此有依赖关系的调用不应“同时发生”,而同步就是阻止同时发生的事情,同步机制通常是一个线程拥有可以访问系统资源的锁,意味着某个线程在某一时刻执行时占用着CPU资源和进程级别的共享对象会被"锁定",其他线程会被抑制执行而无法获取CPU资源和进程级别共享对象访问的控制权,只有等到拥有该锁的线程的锁释放后,其他线程有机会"争夺"获得该锁才能获得CPU资源和进程的共享对象访问的控制权。
异步:和同步的概念是相对的,任何两个彼此独立的操作是异步的,它表明事件是独立发生的。
但非常可悲的是,CPython在多线程并发在角度来说,是大打折扣的,它并非真正意义上的多线程。
臭名昭著的GIL
CPython(标准python实现)有一种称为GIL(全局解释器锁)的东西;GIL仅允许一个线程在同一时刻在一个CPU上执行,因为多个线程之间竞争GIL的控制权,只有取得GIL的线程才能获得CPU运行的时间。因此即使在具有多个CPU内核的多线程体系结构中,GIL也因Python的“臭名昭著"。当遇到I/O等待或者已到CPU轮询时,系统内核会强制CPU切换,将CPU时间分配到其他任意一个线程,当然获得CPU运行时间的线程也竞逐得到GIL,并且CPU切换同样存在时间开销。对于CPU密集型的程序来说,线程在执行计算时不存在I/O等待,但CPU只要到达轮询时,OS内核仍然会强制CPU执行切换到另外一个线程,原先执行计算的线程只能等待下一次CPU调度才能继续执行,这种CPU切换操作无时无刻伴随着线程之间的GIL占用与释放,意味着每次CPU切换操作,其他没有得到GIL的线程都会被强制等待(或阻塞)。这是同样的CPU密集型算法在CPython中使用多线程执行,比使用单线程还要慢的原因所在。
笔者需要明确一个概念,从线程角度来,CPython实现的threading模块并不存在真正意义上的"并发",我更喜欢称为其CPython线程的伪并发。然而在CPython3.5引入了async关键字这一概念,其实CPython异步都是从javascript那里学过来的。“并发"这一概念在CPython3.5才能得到重新洗牌,也就是说异步I/O模式下的多个就绪任务在单线程的事件循环是不受GIL束缚,是事实上的多任务并发。这也是为什么CPython官方鼓励程序员在并发I/O的应用中使用asyncio异步编程的。
然而线程的伪并发对于I/O密集型程序(涉及等待web请求或文件读/写操作的任务)非常有用。 多线程有助于强制程序主动对I/O等待状态中的线程及时作出响应,因为多线程其中一个特性就是当遇到I/O等待,就会马上切换其他处于I/O就绪状态的线程。这种CPU切换操作对于I/O等待状态的线程来说是合情合理的,形象地说,既然I/O等待的线程什么事情都没做,我干嘛将宝贵的CPU时间浪费在它身上呢?马上换另一个就绪的线程。
备注: CPU密集型程序:只要不涉及I/O操作的任何代码都可以叫CPU密集型程序,换句话说任何循环、if/switch控制结构和非I/O操作的简单语句组合的代码都属于这一类。 I/O密集型程序:整个代码逻辑以I/O操作为主的程序,例如open、write/read、socket这些都是I/O密集型的操作。
下面是上一篇代码改进后的多线程版本
#!/usr/bin/env python3
import requests,csv,os,sys,shutil
import time,threading,glob
from lxml import etree
from queue import Queue
IMG_SAVE_PATH='/home/yening/dowlaod_img'
FOLDER_NAME_MAXLEN=10
PERMIT_IMG_EXT=('png','jpg','jpeg')
IMG_SRC_ATTR='data-original'
HEADER={"User-Agent": "Mozilla/5.0 Firefox/47.0"}
thVar=threading.local()
def cur_session():
if not hasattr(thVar,'session'):
thVar.session=requests.Session()
return thVar.session
#end-def
class ImgScrapy(threading.Thread):
def __init__(self,name,sjQue,parentXP,lock):
super(ImgScrapy,self).__init__()
self.name=name
self.tasks=sjQue
self.lock=threading.Lock()
self.parentXP=parentXP
self.lock=lock
self.idx=0
def run(self):
while self.tasks.qsize():
try:
sjTitle,sjUrl=self.tasks.get()
session=cur_session()
with session.get(sjUrl,headers=HEADER) as rs:
print(f"{self.name}尝试分析页面{sjUrl}")
if rs.status_code==200:
self.idx=0
dom=etree.HTML(rs.text)
parent=dom.xpath(self.parentXP)
if len(parent)==0:
raise Exception(f"{self.name}未能找到img图片所在的容器")
parent=parent[0]
imgs=parent.xpath('.//*/img')
if len(imgs)==0:
raise Exception(f"{self.name}未能找到img图片")
print(f"{self.name}在页面{sjUrl}找到{len(imgs)}个图片!!")
for img in imgs:
try:
imgUrl=img.attrib[IMG_SRC_ATTR]
folder=sjTitle[:FOLDER_NAME_MAXLEN]
savePath=os.path.join(IMG_SAVE_PATH,folder)
if not os.path.exists(savePath):
os.mkdir(savePath)
self.dowload(imgUrl,savePath)
except KeyError as e:
continue
#end-for
else:
raise Exception(f'远程服务器返回错误状态码{rs.status_code}')
except requests.exceptions.ProxyError as e:
print(f"尝试抓取{imgUrl}失败,跳过")
except requests.exceptions.ConnectionError as e:
print(f"尝试抓取{imgUrl}失败,跳过")
except Exception as e:
print(e)
continue
#end-while
#end-def
def dowload(self,url,savePath):
sess=cur_session()
with sess.get(url,headers=HEADER,stream=True) as rd:
ext=url.split('.')[-1]
if not ext in PERMIT_IMG_EXT:
return
imgName=''.join([os.path.basename(savePath),str(self.idx),'.',ext])
imgFile=os.path.join(savePath,imgName)
with self.lock:
print(f"{self.name}正在下载图片{imgName}")
with open(imgFile,'wb') as f:
rd.raw.decode_content=True
shutil.copyfileobj(rd.raw,f)
self.idx+=1
#end-with
#end-with
#end-with
#end-def
#end-class
调用代码
if __name__=='__main__':
start=time.time()
sjQue=Queue()
lock=threading.Lock()
urlSource="/home/yening/report/人像摄影摄影教程-第26页-中关村在线摄影论坛_alum.csv"
with open(urlSource,'r') as f:
data=csv.reader(f)
for row in data:
sjQue.put(row)
imgTaskList=[]
for k in range(10):
imgSpy=ImgScrapy(
f"ImageScrapy线程{k}",
sjQue,
'//div[@id="bookContent"]',
lock
)
imgSpy.start()
imgTaskList.append(imgSpy)
#end-for
for t in imgTaskList:
t.join()
#end-for
end=time.time()
print("一共耗时{}s".format(end-start))运行测试

我们的多线程爬虫有一个有趣的地方就是,每个线程都需要创建自己的request.Session()对象。很显然,每个线程都需要一个单独的Session。这是在多线程棘手的问题之一。不幸的是,requests.Session()不是线程安全的。threading.local在线程模块中专门解决这个问题。事实上我们只创建了一个requests.Session()对象,而不是为每个线程创建一个会话对象。对象本身负责分离不同线程对不同数据的访问。在本篇示例中,这是通过threadLocal和cur_session()函数完成的:
thread_local=threading.local()
def cur_session():
if not hasattr(thread_local,"session"):
thread_local.session=requests.Session()
return thread_local.session当调用cur_session()时,它查找的会话特定于它正在运行的特定线程。因此,每个线程将在第一次调用cur_session()时创建一个会话,然后在其整个生命周期内对每个线程后续运行都调用该会话。 这里使用的策略是称为线程本地存储。我们将同一个session会话寄存到 Threading.local()中,它看起来像全局对象的对象,但该对象特定于每个单独的线程。
因为操作系统控制您的任务何时中断以及另一个任务何时开始都是根据当前拥有GIL的线程的I/O状态而定,所以线程之间共享的任何数据都需要受到保护,我们知道位于threading.local()的变量是线程安全的。CPython还有几种线程安全的数据结构,例如Python的queue模块中的Queue。这些对象其实都封装了threading.Lock之类的低级原语,以确保只有一个线程可以同时访问一块代码或一部分内存。
最后,简单介绍一下如何选择线程数。您可以看到示例代码使用了32个线程获得抓取网站内容的性能是最优。但并不是线程数越多,性能就越好的。在笔者测试中大于2的指数级递增线程数以后,平均的时间开销都会逐渐递增的。原因是什么呢?因为在C底层都有线程创建和销毁线程的额外开销,如果线程数过大,线程竞逐GIL也是存在时间开销的,那么这些线程的额外时间开销会抹去任何节省的时间。
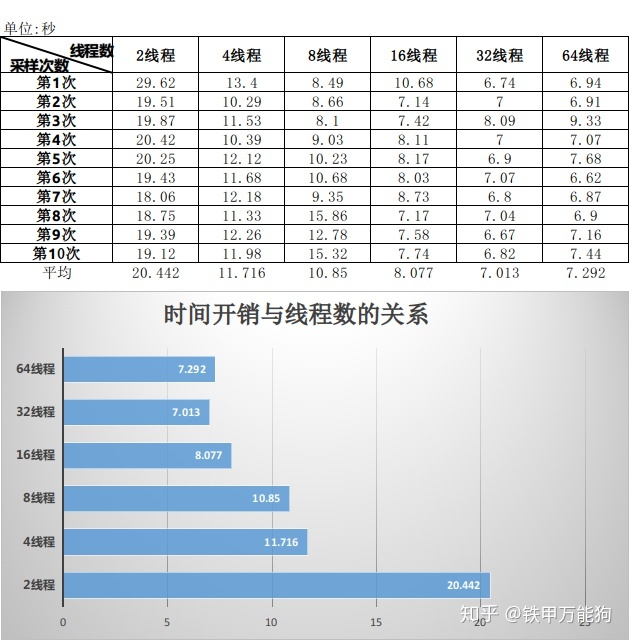
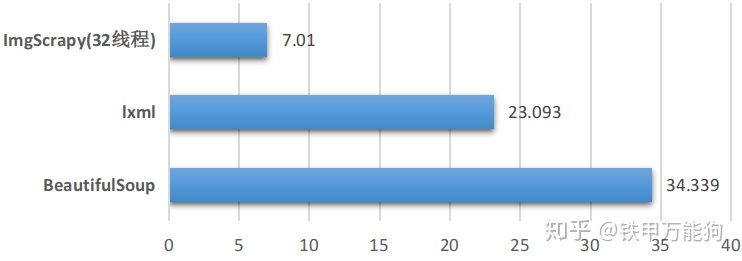
从目前来看7.01这个时间开销,我觉得能够接受。然而我们目前仍然使用原生Python写的多线程爬虫,它仍然是慢代码,也就是7.01秒这个时间开销,包含了线程切换的GIL开销,以及动态派遣等一系列Python内部的开销。也就是我们可以进一步压缩时间开销,这些留到以后再说。
小结
CPython尽管存在如此多的诽议,作为思维清晰的Python用户应该敢于正视GIL的存在,从目前看来,CPython要根除GIL是不太可能的,从GIL这个诟病,也许你可以悲观地认为,很多第三方的Python重新实现都是它逼出来的,谁让Python的商业炒作如此成功呢!















 1520
1520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









