






当系统中的数据超出一定数量时,给展示端展示列表性的数据时,一般不会把所有的数据一次性全部显示到展示端,体验良好的交互设计一般是一次只展示一部分数据,通过上下翻页或指定页码的方式查看其它页的数据,就像翻书一样。另一方面当数据量大时,服务器的资源也限制了一次查所有数据,如果一次查询的数据量过多,数据库和应用服务器的内存都有可能被撑爆。

单库分页查询
主流的数据库的sql语法都支持分页,比如mysql的offset ... limit,oracle的rownum。PageHelper框架可以让使用者不用关心分页语法就可以让dao查询接口实现分页功能,它跟mybatis框架结合使用,使用mybatis的Interceptor机制,通过拦截Executor的query方法拦截所有dao数据查询,通过替换MappedStatement修改执行的sql,给待执行的sql套上分页条件把源sql转换成支持分页的sql,PageHelper支持mysql、oracle、db2、sqlserver等主流数据库,这个框架屏蔽了不同数据的分页语法差异,让使用者可以不用了解这些数据库的分页语法就能实现分页功能。
PageHelper的基本用法是在dao查询之前设置分页参数到线程上下文,传入页数,页记录数,第三个参数是是否查询总数,这个参数设置true之后,框架会自动增加一次额外的查询,在原sql上套上一层count查询满足条件的总记录数:
Page page = PageHelper.startPage(pageNo, pageSize, true);
try{
List result = dao.query(...);
}finally{
SqlUtil.clearLocalPage();
}
记得一定要在finally块中把分页参数从线程上文中清除掉,否则可能会因为线程上下文污染引发一些奇怪的问题,特别是rpc框架使用了线程池的情况下,因为线程池会复用线程,如果分页参数没有被清除,线程后续被分配给其它请求时,如果请求有查询数据库,由于线程上下文分页参数的存在该访问sql会被修改造成功能问题,甚至sql执行有可能会报错。笔者曾经就遇到过这种问题,应用中有些代码调用了startPage方法,忘记在finally块中清除,结果导致某些select count(*) from t之类的sql被框架转换套上count之后报错。
上面这种模板式的代码可以采用aop切面+注解的方式把分页参数的设置和清除从业务代码剥离出去,通过注解标识分页查询接口和分页页号和页大小参数,切面拦截分页查询接口并生成Page对象设置到线程上下文中和PageHelper结合起来生成分页sql,这样即能达到不侵入代码的目的,又可以消除忘记在finally块中清除的风险。
还有一种方式是在定义dao查询接口时,给查询方法增加一个RowBounds类型的参数到最后,设置好分页参数offset和limit传入到这个RowBounds参数中,通过这种方式,框架会识别最后一个RowBounds类型的参数,生成一个对应的Page设置到线程上线文中,rowBoundsWithCount属性被设置成true时,也会生成count sql增加一次额外的查询查总数,查询结束之后框架会自动把线程上下文清掉。
跨库分页查询
当数据库是单实例数据库时,实现分页查询是很简单的,但是当系统的数据量大到一定程度之后,超过了单机可垂直扩展的上限之后,就要对数据进行分库横向扩展,数据存储到多个节点中演变成分布式数据库。分布式数据库要求业务建表时指定一个字段为均衡字段来做为分库路由因子。为了提高性能应用中应尽量避免跨库查询,查询时查询条件中带上均衡字段,把查询锁定在单个数据节点,省去多库数据聚合的开销。但是实际的业务中不会这么理想所有条件都可以带上均衡字段,比如面向用户的订单查询业务,订单表均衡字段一般为设成账号字段,用户端查询订单时可带上均衡字段,但是如果是商家的查询订单时显然无法在条件中带上均衡字段了,当然可以通过数据冗余来解决一部分问题,还是刚刚那个用户端和商家端查询的例子,可以建一张冗余表同步一份数据,这个表的均衡字段设置成商家字段,这个商家查询需求也可以带上均衡字段把查询锁定在单个节点。
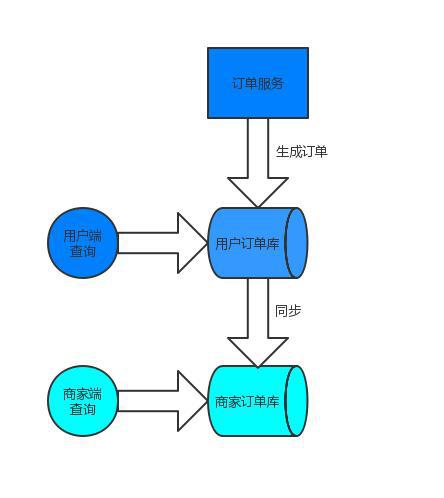
这种方案的代价也比较大:
一、DB资源需要翻倍;
二、需要解决多份数据的一致性问题,特别是对数据一致性要求比较高的场景,解决方案会比较复杂;
三、会有数据均衡问题,有些商家的商品热销,有些商家商品销量不好,容易出现各数据节点数据不均衡。
而且在实际的业务需求中,可能会存在无法带上均衡字段的各种字段维度的查询,不可能每个查询维度都去冗余一份,因此最终还是要应对跨库查询的问题。
显然跨库分页查询就没那么简单了,展示端的数据分页一般要求数据按照某个排序因子排序,比如展示订单列表时一般都会按照订单时间进行降序排序。而当数据存放在多个节点之后,每个数据节点的数据只能在本节点局部排序,所有节点的数据加载到一个数据聚合节点聚合数据之后才能进行全局排序。本文的剩余部分将重点介绍几种跨库分页查询的实现思路。
全局排序分页
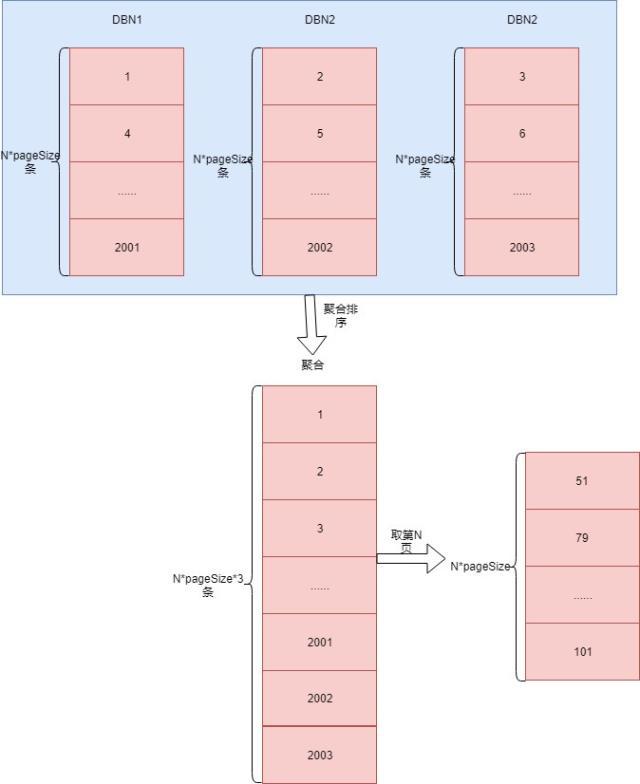
当系统数据量比较少,可以采用全局排序分页,当需要查询第N页数据时,每个数据节点返回前N*pageSize条数据到聚合节点,聚合节点拿到所有节点数据之后,再对所有数据进行全局排序,取第(N-1)*pageSize+1到N*pageSize条数据即全局的第N页数据,这种实现方式很简单但缺点也很明显,当系统数据量很大时会有深分页问题,性能会指数级下降,聚合节点会面临OOM的风险,试想一下系统总共有100万条数据,要查最后几页数据时需要把100万条数据全部查出来聚合排序,这显然会对应用服务器和网络带宽带来巨大的压力。
限定排序因子范围分页
假如在查询时已知上(下)页的分页列表的最后一条数据的排序因子字段的值时,那么查询当前页数据时可以利用排序因子的范围来缩小每个数据节点需要查的数据。比如要对订单列表进行分页,排序因子是订单时间降序排序,向后翻页时假如上一页列表的最后一条数据的订单时间是t1,那么查询当前页数据时每个节点只需查订单时间小于t1的订单,取pageSize条数据,使用sql:select * from orders where orderTime
每个数据节点查到这pageSize条数据,聚合节点对所有节点的pageSize条数据进行全局排序取前pageSize条,这样聚合节点最多只需处理M(数据节点个数)*pageSize条记录不会有深分页问题,这种方案在查询时展示层需要传三个参数:
1.标识是向前翻页还是向后翻页;
2.前一页最后一条记录排序因子字段值(如果是向前翻页则是后一页第一条记录排序因子值);
3.页大小。
它的性能是非常稳定的,不会随着系统数据量的增大导致性能下降,但是要求业务上做折中,只能上下翻页不能跳页查询,从第2页只能跳到第1页和第3页查询,不能跳到第4页查询,因为跳页查询就不能参考前一次的排序因子字段值了,还有一个限制就是如果db中有多条排序因子字段值相同的记录,可能会漏掉这些有字段值相同的就来记录,比如上一页最后一条orderTime是t1,但是在后一页还有orderTime是t1的记录,因为查询条件是orderTime
二次查询分页
二次查询方案的思路是先通过一次查询粗略的圈定待查询数据范围,然后在这个范围内精确的排序并确定各条数据的全局offset进而确定属于查询范围内的数据。还是拿上面的订单列表分页举例,假设有3个数据节点,pageSize=5,要查第10页的数据,第10页的数据的全局offset是50,在这3个数据节点都执行offset=50/3,limit=5查询一批数据,offset向下取整为16,不能向上取整,如果向上取整取17,17*3=51大于50可能会漏掉靠前的数据,所有数据节点的数据查询出来之后,聚合节点找到这些数据中orderTime最大的一条,假设最大的排序因子maxOrderTime。

在另外几个最大orderTime大于maxOrderTime的节点再执行一次查询补全数据确定maxOrderTime的全局offset,假设各个节点第一次查询出的记录最大的orderTime值分别是maxOrderTime(n)那么查询条件为orderTime between maxOrderTime(n) and maxOrderTime。

执行完次查询之后,就能确定每个节点orderTime最大的一条小于maxOrderTime,进而确定maxOrderTime所在记录在每个数据节点中的offset,把节点局部的offset相加就能确定maxOrderTime所在记录的全局offset,如上图可知例中maxOrderTime的offset=16+13+14=43,接下来可以通过排序获取所有记录的全局offset。
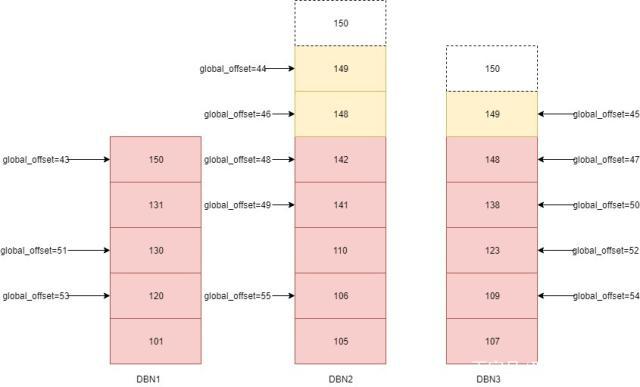
所有记录的全局offset确定之后就能找到全局的offset 50 limit 5的记录了,像上图中的,offset为50,51,52,53,54(数值为138,130,123,120,109)的5条记录就是要查的第10页的记录。
这种方案的优点有:
1.业务无损,无需业务折中
2.性能稳定,不会随着数据量的增加造成性能下降
缺点是:
1.增加额外的查询耗时相对较高
2.实现复杂度相对较高















 1431
1431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









